Náhodná veličina
Náhodná veličina (používají se i různé kombinace slov náhodná, stochastická nebo náhodová a proměnná nebo veličina) je libovolná veličina, kterou je možné opakovaně měřit u různých objektů, v různých místech nebo v různém čase a její hodnoty podrobit zpracování metodami teorie pravděpodobnosti nebo matematické statistiky. Příkladem může být počet ok při vrhu kostkou, teplota naměřená na určitém místě ve stejnou hodinu v různých dnech, roční mzda jednotlivých občanů státu, apod. Náhodnou veličinu lze jednoduše charakterizovat jako veličinu, jejíž hodnoty nelze před provedením pozorování jednoznačně určit, ale závisí na náhodě.
Poněkud přesněji je náhodná veličina funkce, která přiřazuje každému elementárnímu náhodnému jevu nějakou (zpravidla číselnou) hodnotu (například při hodu mincí „hlavě“ nulu a „orlu“ jedničku).
Definice
Formální definice
Formální definice zahrnuje i agregované náhodné proměnné, jako jsou náhodné vektory, náhodné matice, náhodné posloupnosti a náhodné procesy.
Nechť:
- je pravděpodobnostní prostor; to znamená, že
- je libovolná neprázdná množina (množina elementárních jevů zvaná též výběrový prostor),
- je libovolný systém podmnožin , který tvoří -algebru, a
- je pravděpodobnost, čili míra na (tj. zobrazení, které každé podmnožině , která je zároveň prvkem , přiřadí nezáporné reálné číslo), která je normovaná tak, že
- je měřitelný prostor s borelovskou -algebrou podmnožin ; zpravidla se jako používá množina všech reálných čísel nebo nějaká její vhodná podmnožina.











Náhodnou veličinou pak nazýváme každé zobrazení z prostoru elementárních jevů do měřitelného prostoru , tj. , pokud je měřitelné, t.j. pokud pro každou množinu platí, že .



Jednoduchá náhodná veličina
Pro hodnoty jednoduché náhodné veličiny lze používat reálná čísla. Pak lze předchozí definici upravit tak, že je náhodná veličina právě tehdy, když pro každé reálné číslo platí (nerovnost může být i neostrá nebo obrácená).



V praxi se příliš neohlížíme na to, aby množina náhodných jevů byla -algebrou a do definice náhodné veličiny nezahrnujeme pravděpodobnostní míru. Pak může být definice následující:
Je-li Ω výběrový prostor přiřazený k výsledkům určitého pokusu, pak náhodná veličina, kterou označíme X, je funkce, která prvkům ω výběrového prostoru Ω přiřazuje reálná čísla x, kde x = X (ω).[1]
Náhodné veličiny se označují velkými písmeny latinské abecedy (např. X, Y) a jejich hodnoty malými písmeny (např. x, y).[1]
Náhodné veličiny diskrétního typu
Náhodná veličina je diskrétního typu, pokud množina je konečná nebo spočetná. Hodnoty náhodné proměnné lze pak psát x1, x2, ….
Pokud je množina konečná, je možné říct, že
Náhodná veličina X je diskrétní, jestliže prvky výběrového prostoru Ω zobrazí na osu reálných čísel jako izolované body, označení x1, x2, …., xk, přičemž každý z těchto bodů má nenulovou pravděpodobnost.[1]
Je-li výběrový prostor konečný, lze použít náhodnou veličinu, která přiřazuje jednotlivým elementárním jevům přirozená čísla, pak lze hodnoty xk označovat pouze symbolem k.
Pro pochopení této problematiky je potřeba znát pravděpodobnostní zákony rozdělení a základní charakteristiky diskrétních náhodných veličin. Rovněž s tímto tématem úzce souvisí důležitá rozdělení diskrétních náhodných veličin (binomické, hypergeometrické, geometrické a Poissonovo).
Mezi pravděpodobnostní zákony diskrétního rozdělení patří pravděpodobnostní funkce, která nese označení P (X = xk), kde xk jsou její hodnoty v číslech. Platí, že ve výběrovém prostoru mají prvky součet svých pravděpodobností roven jedné, potom součet všech hodnot pravděpodobnostní funkce je také roven jedné, tj. ∑P (X= xk)= 1.
Dalším pravděpodobnostním zákonem rozdělení náhodné veličiny X je její distribuční funkce, která se značí F (x). Ta je rovna pravděpodobnosti, s jakou náhodná veličina X nabude hodnot z intervalu (- ∞, x), tj. F (x)= P (X ≤ x ).
Známe-li hodnoty pravděpodobnostní funkce, pak distribuční funkci diskrétní náhodné veličiny lze získat součtem hodnot pravděpodobnostní funkce P (X= x) v bodech xk, které leží v intervalu (- ∞, x), tj. F (x)= ∑P (X= xk).[1]
Střední hodnota
Jedna z nejdůležitějších charakteristik sloužící pro popis diskrétní náhodné veličiny je střední hodnota označená E (X), která je definovaná následujícím vzorcem:

Výpočet se provádí tak, že se vynásobí hodnoty diskrétní náhodné veličiny jimi příslušnými hodnotami pravděpodobnostní funkce, a poté se tyto součiny sečtou. Rozlišujeme geometrickou a statistickou interpretaci střední hodnoty. Geometricky se střední hodnota znázorňuje jako bod na ose reálných čísel, na níž jsou hodnoty náhodné veličiny. Podle statistické interpretace představuje střední hodnota číslo, kolem něhož kolísají výběrové průměry vypočtené ze sérií pozorovaných hodnot náhodné veličiny.[1]
Výběrový průměr
Výběrový průměr, který nese označení , se počítá dle vzorce:


kde xi jsou hodnoty náhodné veličiny X
a n je počet pokusů.
Pokud opakujeme více sérií pokusu, docházíme ke zjištění, že výběrové průměry kolísají kolem střední hodnoty.
Rozptyl (variance, disperze)
Rozptyl se značí D (X) a vyjadřuje velikost odchylek hodnot diskrétní náhodné veličiny X od její střední hodnoty, přičemž bere v úvahu, jak je pravděpodobnost v těchto bodech rozdělena. Rozptyl se vypočítá následovně:

Samotnou hodnotu rozptylu určíme tak, že vypočteme součiny kvadrátů hodnot diskrétní náhodné veličiny s jimi příslušnými hodnotami pravděpodobnostní funkce a potom součiny sečteme. Od získaného součtu odečteme kvadrát střední hodnoty.[1]
Směrodatná odchylka
Jelikož rozptyl má rozměr kvadrátu, je směrodatná odchylka, značená σ (X) vhodnějším vyjádřením charakteristiky dané náhodné veličiny, protože se vypočítá jako odmocnina z rozptylu D (X).

Směrodatná odchylka vyjadřuje, o kolik je hodnota náhodné veličiny vzdálena od střední hodnoty.[1]
Alternativní rozložení
Toto rozložení náhodných veličin lze specifikovat jako rozložení náhodných veličin X, u kterých je známá pravděpodobnost úspěchu v jednom pokusu.[2]
Toto rozdělení tedy skýtá možné dva výsledky pokusu (úspěch a neúspěch). Pokud jde o úspěch nabývá náhodná veličina hodnoty 1. Pokud se jedná o nepříznivý výsledek nabývá náhodná veličina hodnoty 0.[3]


Binomické rozdělení
Toto rozdělení udává rozdělení náhodných veličin jako úspěchů v posloupnosti n opakovaných nezávislých pokusech. Pravděpodobnost výskytu jevu je zde stále stejná.[2]
Toto rozdělení tedy označujeme jako Bi (n,p), což naznačuje n náhodných pokusů při p pravděpodobnosti úspěchu v každém pokusu.[3]
- , kde x = 0, 1 [3]

Zde se vychází z Bernoulliova pokusu, který spočívá v tom, že v daném náhodném pokusu mohou nastat pouze dva stavy: A, A s pravděpodobností p, 1−p. To lze modelovat tzv. binární náhodnou proměnnou Y, pro kterou platí: P(Y = 1) = p a P(Y = 0) = 1−p. Platí:[3]


Náhodná proměnná X vznikne jako součet n nezávislých binárních proměnných Yi s hodnotami 0 nebo 1, které mají všechny stejné rozdělení určené parametrem p:[3]
Z tohoto vyplývají i určité charakteristiky tohoto rozdělení.


Hypergeometrické rozdělení
Toto rozdělení Hg (N,A,n) předpokládá, že v souboru N prvků je A prvků označeno; při náhodném pokusu náhodně vybereme n prvků (bez vracení). Náhodnou veličinou je počet označených prvků z n vybraných.
Zápis pak vypadá takto:[2]

Vlastnosti tohoto rozdělení tedy lze vyjádřit tímto způsobem:


Poissonovo rozdělení
Poissonovo rozdělení udává svou náhodnou veličinou počet výskytů, jež nastanou v nějakém určitém časovém intervalu. Parametr lambda vyjadřuje střední hodnotu počtu výskytů v daném intervalu.
Toto rozdělení se používá hlavně tam, kde je počet výskytů vzácný, neobvyklý.[2]
- v daném jednotkovém úseku, kde x = 0,1,2,... ; je parametr.[3]


Vlastnosti rozdělení vypadají takto:


Náhodné veličiny spojitého typu
Náhodné veličiny spojitého typu jsou charakterizovány následovně:
Náhodná veličina X je spojitá, jestliže její hodnoty, přiřazené prvkům výběrového prostoru Ω, tvoří interval na ose reálných čísel, přičemž každý bod toho intervalu má nulovou pravděpodobnost.[4]
Hodnota pravděpodobnostní funkce je tedy ve všech bodech nulová, proto musíme použít jiný pravděpodobnostní zákon, pomocí kterého budeme popisovat spojitou náhodnou veličinu, a tou je hustota pravděpodobnosti, označovaná f (x), která vypovídá o tom, jak jsou jednotlivé hodnoty spojité náhodné veličiny X „nahuštěny“ na ose reálných čísel v okolí bodu x.
Další funkcí, které se pro popis spojité náhodné veličiny používá, je funkce distribuční značená F (x), která je rovna pravděpodobnosti P (X≤x ). Charakterizovat ji lze jako funkci, která při postupu po ose reálných čísel „sčítá“ pravděpodobnosti. Pomocí hustoty pravděpodobnosti vyjádříme spojitou náhodnou veličinu X integrálem[4]

Hustotu pravděpodobnosti v tomto integrálu lze podle pravidel integrálního počtu určit jeho derivací. Z toho vychází, že hustota pravděpodobnosti je rovna derivaci distribuční funkce tedy

V bodě x, kde derivace F´(x) neexistuje, se hustotě pravděpodobnosti přiřadí f(x) libovolná hodnota.
Hustota pravděpodobnosti splňuje podmínku

Integrál představuje geometricky plochu s jednotkovým obsahem, zdola ohraničenou osou reálných čísel a shora grafem hustoty pravděpodobností.
Pravděpodobnost, že spojitá náhodná veličina nabude hodnoty z intervalu s hraničními body x1 a x2 , kde x1< x2, lze vypočítat buď pomocí její hustoty pravděpodobnosti nebo pomocí její distribuční funkce pomocí vzorců

K popisu spojité náhodné veličiny používáme číselné charakteristiky, obdobné náhodným veličinám diskrétního typu. Nejdůležitější charakteristikou náhodné veličiny je střední hodnota, označená E(X), která je definována integrálem

Střední hodnota spojité náhodné veličiny má stejný význam jako u diskrétní náhodné veličiny.
Další charakteristikou spojité náhodné veličiny je rozptyl, označovaný D(X), který lze vypočítat takto

K popisu hodnot rozptýlení spojité náhodné veličiny X se používá častěji směrodatná odchylka, označená σ(X), neboť má stejný rozměr jako náhodná veličina X, kdežto rozptyl má rozměr kvadrátu této veličiny. Směrodatná odchylka je definována takto:
Mezi další charakteristiky, které udávají, jak jsou náhodné veličiny X rozděleny na ose reálných čísel v určitém pravděpodobnostním poměru jsou kvantily. Definovat je lze takto: 100% kvantilem spojité náhodné veličiny X je reálné číslo, označené xp, kdy pro p platí F(xp) = p. Význam kvantilu spočívá v tom, že reálnou osu, na níž jsou hodnoty náhodné veličiny X rozloženy, rozdělí na dva intervaly.
K nejdůležitějším kvantilům patří medián, což je 50% kvantil. Medián se používá tehdy, když náhodná veličina nemá definovanou střední hodnotu.[4]
Rovnoměrné rozdělení
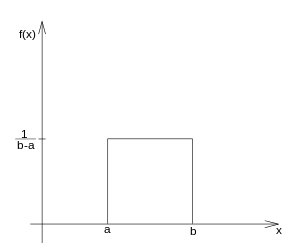
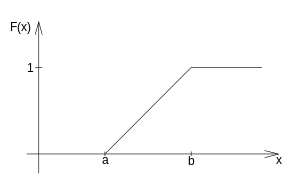
Spojitá náhodná veličina X má rovnoměrné rozdělení, jestliže její hustota pravděpodobnosti f (x) a distribuční funkce F (x) jsou zadány předpisy:

Rovnoměrným rozdělením se řídí takové náhodné veličiny, pro něž pravděpodobnost padnutí do jistého podintervalu zadaného intervalu 〈a,b〉 je úměrná délce tohoto podintervalu a nezávisí na jeho umístění v intervalu 〈a,b〉.[4]
Rovnoměrné rozdělení popisuje například chyby při zaokrouhlování čísel, doby čekání na uskutečnění jevu, který se může vyskytnout v časových intervalech pevně stanovené délky, apod[4].
Střední hodnota a rozptyl rovnoměrného rozdělení jsou:

Hustota pravděpodobnosti a distribuční funkce náhodné veličiny s rovnoměrným rozdělením:
Normální rozdělení
Spojitá náhodná veličina X má normální rozdělení s parametry µ a σ, což se označuje N (µ,σ2), jestliže jsou její hustota pravděpodobnosti f (x) a distribuční funkce F (x) pro x ∈ (-∞,∞) dány předpisy:

Střední hodnota a rozptyl normálního rozdělení jsou:

Křivka znázorňující hustotu pravděpodobnosti normálního rozdělení se nazývá Gaussova křivka. Charakteristickými rysy této křivky je to, že je symetrická kolem svislé přímky procházející bodem μ, v němž má funkce f (x) globální maximum, a ve vzdálenostech 3 σ vlevo a vpravo od bodu μ se téměř dotýká osy x[4].
Graf distribuční funkce F (x) normálního rozdělení a Gaussova křivka:


Normální rozdělení je nejdůležitějším spojitým rozdělením, protože jej mají mnohé náhodné veličiny, například chyby měření, rozměry výrobků při hromadné výrobě, mnohé jevy ve fyzice, v biologii a medicíně a podobně. Obecně lze říci, že je použitelné všude tam, kde hodnoty náhodné veličiny jsou ovlivněny působením velkého počtu nepatrných vzájemně nezávislých nebo slabě závislých náhodných vlivů. Jeho význam spočívá také v tom, že se jím dají za určitých podmínek aproximovat i jiná rozdělení, jak diskrétních, tak i spojitých náhodných veličin.
Při výpočtech úloh se spojitými náhodnými veličinami, které mají normální rozdělení, se tato rozdělení liší svými parametry µ a σ. Pro usnadnění výpočtů je vhodné tyto náhodné veličiny normovat, což se provede tak, že od hodnot náhodné veličiny se odečte její střední hodnota µ a rozdíl se vydělí směrodatnou odchylkou σ. Vznikne tak normovaná náhodnou veličinu, označená U, kde

Jestliže náhodná veličina X má normální rozdělení N (µ,σ2), pak jejím normováním vznikne náhodná veličinu U mající normované normální rozdělení, které se označí N(0,1), takže má náhodná veličina U střední hodnotu rovnu nule a rozptyl roven jedné.
Distribuční funkce normované náhodné veličiny U, která je označena FN(u), je pak vyjádřena integrálem:

Často řešenou úlohou je určení pravděpodobnosti, že náhodná veličina X s normálním rozdělením N(µ,σ2) nabude některé hodnoty z intervalu, jehož krajní body jsou x1 a x2. Tuto pravděpodobnost lze vypočíst pomocí vzorce:

Protože náhodná veličina X je spojitá, nezáleží tato pravděpodobnost na tom, zda jsou krajní body intervalu do výpočtu zahrnuty nebo ne.
K důležitým vlastnostem náhodné veličiny, mající normální rozdělení, patří pravidlo tří sigma, podle něhož je 99,73 % jejích hodnot v intervalu (μ-3σ,μ+3σ). V tomto intervalu jsou tak prakticky všechny její hodnoty. Pravidlo tří sigma lze odvodit s použitím vzorce takto[4]:

Exponenciální rozdělení
Spojitá náhodná veličina X má exponenciální rozdělení s parametry A a δ, což se značí E(A,δ), kde δ > 0, jestliže její hustota pravděpodobnosti a distribuční funkce jsou dány předpisy[4]:

Graf hustoty pravděpodobnosti a distribuční funkce:

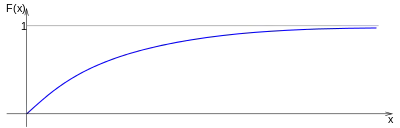
Střední hodnota a rozptyl exponenciálního rozdělení jsou:


Význam parametru A je v tom, že před touto hodnotou se hodnoty náhodné veličiny s exponenciálním rozdělením nemohou vyskytnout.
Exponenciální rozdělení se používá především v teorii hromadné obsluhy a teorii spolehlivosti. Náhodnou veličinou X bývá obvykle doba, během níž nastane sledovaný jev, například doby mezi poruchami přístroje nebo doby mezi příchody zákazníků do opravny. V některých případech, jako je například čekání na poruchu přístroje, se náhodná veličina X nazývá „dobou života“ tohoto přístroje.
Exponenciální rozdělení se někdy nazývá rozdělení bez paměti, což lze vyjádřit následovně: Pravděpodobnost, že zařízení, které pracovalo bez poruchy po dobu a, bude pracovat bez poruchy ještě další dobu x, je rovna pravděpodobnosti, že zařízení, které dosud nebylo v provozu, bude pracovat bez poruchy aspoň x hodin, tedy jakoby „zapomnělo“ již odpracovanou dobu.
Pro A = 0 lze vyjádřit tuto vlastnost vyjádřit následovně[4]:

Exponenciální rozdělení je z těchto důvodů vhodné k popisu rozdělení doby života těch zařízení, u nichž dochází k poruše ze zcela náhodných vnějších příčin, nikoliv například vlivem stárnutí materiálu.
Logaritmicko-normální rozdělení
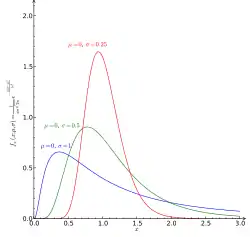
náhled Logaritmicko-normální rozdělení (stručně lognormální rozdělení) spojité náhodné veličiny se používá mimo jiné při popisu velikosti škody při živelních událostech a různých haváriích a jako model pro rozdělení velikosti platů v některých organizacích.
Spojitá náhodná veličina X má lognormální rozdělení s parametry µ a σ, což se značí LN(µ,σ2), jestliže její hustota pravděpodobnosti f(x) a distribuční funkce F(x) jsou pro x> 0 dány předpisy[4]:

Střední hodnota a rozptyl lognormálního rozdělení jsou:

Jsou-li známy hodnoty E(X) a D(X) lognormálního rozdělení, pak lze parametry µ a σ tohoto rozdělení určit pomocí těchto vzorců:

Využití náhodných veličin v marketingu
V prvé řadě nutno podotknout, že využití statistiky jako celku je velmi významné obzvláště při marketingovém výzkumu. Pokud firma pracuje v rámci organizace se svým vlastním marketingovým informačním systémem, je umění práce s informacemi do něj vstupujícími i vystupujícími, zcela klíčové. Výstupy tohoto systému je nejlépe popisovat statisticky. Jedním z nejdůležitějších prvků MIS je právě marketingový výzkum, který pracuje se sběrem, analýzou a vyhodnocováním dat, které popisují marketingovou situaci.
Výzkumy jsou většinou založené na bádání po náhodných veličinách a jejich rozdělení. Důležité je v tomto směru samozřejmě zobecňovat výsledky na bázi pravděpodobností, které vypovídají o minulých trendech ale i předvídání budoucích.
Odkazy
Reference
- KROPÁČ, Jiří. Statistika: náhodné jevy, náhodné veličiny, základy matematické statistiky, indexní analýza, regresní analýza, časové řady. 2. vyd. Brno: Vysoké učení technické v Brně, Fakulta podnikatelská, VUT v Brně, 2012. ISBN 978-80-7204-788-8. S. 138.
- BUDÍKOVÁ, Marie; KRÁLOVÁ, Mária. Průvodce základními statistickými metodami. 1. vyd. Praha: Grada, 2010. 272 s. ISBN 978-80-247-3243-5.
- ZÁKLADNÍ TYPY ROZDĚLENÍ PRAVDĚPODOBNOSTI DISKRÉTNÍ NÁHODNÉ VELIČINY. In: Homen.vs.cz [online]. 2015 [cit. 2015-03-09]. Dostupné z: http://homen.vsb.cz/~oti73/cdpast1/KAP04/PRAV4.HTM Archivováno 29. 4. 2015 na Wayback Machine
- KROPÁČ, Jiří. Statistika A: náhodné jevy, náhodné veličiny, náhodné vektory, indexní analýza, rozhodování za rizika. 3. dopl. vyd. Brno: Fakulta Podnikatelská, VUT v Brně, 2008. 139 s. ISBN 978-80-214-3587-2.
Související články
Externí odkazy
 Obrázky, zvuky či videa k tématu náhodná veličina na Wikimedia Commons
Obrázky, zvuky či videa k tématu náhodná veličina na Wikimedia Commons