Diskriminační analýza
Diskriminační analýza (DA, discriminant analysis) je jednou z metod mnohorozměrné statistické analýzy (MSA, multivariate statistical analysis), která slouží k diskriminaci (rozlišení) objektů pocházejících z konečného počtu tříd (kategorií) na základě objektů z jisté podmnožiny všech objektů, tzv. trénovací množiny, sestavením rozhodovacího pravidla a k následné klasifikaci (zařazení) objektů zbylých (těch mimo trénovací množinu) aplikací získaného pravidla do jiných tříd, které představují odhad skutečných tříd. Pod pojmem objekty je možné si představovat buď osoby, nebo živočichy, nebo rostliny, digitální fotografie, tvary, apod.; pojem třída by pak například u rostlin stejné čeledi mohl znamenat druhové jméno rostliny. Všechny objekty jsou charakterizovány sérií znaků, které na nich můžeme pozorovat. U rostlin například bychom mohli sledovat velikost, tvar, barvu květu, tvar listu, atd. Přitom předpokládáme, že objekty ze stejné třídy vykazují „podobné“ znaky, a o objektech mimo trénovací množinu předem nevíme, do které třídy patří. Součástí DA by také měl být odhad spolehlivosti výsledné klasifikace. Pro přesnější formulaci vizte sekci Základní principy DA.
DA úzce souvisí s dalšími metodami MSA, jako jsou shluková analýza (CA, cluster analysis), faktorová analýza (FA, factor analysis), zde speciálně s analýzou hlavních komponent (PCA, principal component analysis). V molekulární biologii je využívána kombinace analýz PCA a DA jako tzv. DAPC - diskriminační analýza hlavních komponent. DA dále např. souvisí s lineární regresí a logistickou regresí. Fisherova DA pak využívá techniky známé z mnohorozměrné analýzy rozptylu (MANOVA, multivariate analysis of variance).
Ideově je postup DA podobný metodám neuronových sítí.
Historie a využití v současnosti
Za zakladatele DA je považován sir Ronald Aylmer Fisher, který ve své práci[1] z roku 1936 použil metodu dnes označovanou jako Fisherova diskriminační analýza ke klasifikaci druhového jména rostlin kosatců na základě čtyř pozorovaných znaků. Metodu demonstroval na datech známých jako Iris flower data set.
Zpočátku byla DA využívána v biologii k třídění rostlin a zemědělských plodin, dále také v medicíně a v antropologii při klasifikaci koster. Širšího uplatnění se dočkala teprve s rozmachem výpočetní techniky, která umožnila rychle zpracovávat větší množství dat. V roce 1954 ji použili Maurice M. Tatsuoka a David V. Tiedeman v oblasti sociologie k psychologickým testům.[2] William R. Klecka v roce 1980 například aplikoval DA na sledování obyvatelstva v průběhu voleb, tedy v politice.[3] V bankovnictví se DA používala k rozhodování o přidělení úvěrů (tedy ke klasifikaci klientů dle solventnosti) a k odhalování podezřelých finančních transakcí.
V současnosti DA nalézá stále uplatnění v lékařství při stanovování diagnóz a určování rizikových skupin pacientů a rovněž v numerické taxonomii (fenetice), tedy ke klasifikaci rostlin a živočichů. Další oblastí, kde se DA participuje je rozpoznávání tváří (face recognition), nebo obecněji v rozpoznávání tvarů (pattern recognition), a dále například v kybernetice. Modely lineární DA se rovněž používají ve finančnictví a v marketingu, například také k předvídání krachů firem (bankruptcy prediction).
Základní principy DA
Předpoklady úlohy DA a značení v textu
V celém textu značí množinu reálných čísel a množinu přirozených čísel.


Nechť . Diskriminační analýzu používáme v situaci, kdy chceme rozlišit objektů pocházejících z disjunktních tříd (tzn. každý objekt pochází z právě jedné třídy) pouze na základě zvolených znaků, které na objektech pozorujeme. Soubor znaků sledovaných na jednom objektu reprezentujeme obecně -rozměrným reálným vektorem, . Přitom předpokládáme, že znaky pozorované na objektech ze stejné třídy respektují stejné pravděpodobnostní rozdělení na množině . Naopak po rozděleních znaků z různých tříd je přirozené požadovat, aby se vzájemně lišila, jinak nemá smysl diskriminační analýzu provádět.







V textu jsou jednotlivé třídy opatřeny indexy a značí se pro .


Pravděpodobnostní míru definovanou na měřitelném prostoru udávající rozdělení pozorovaných znaků na objektech z třídy označujeme pro . Jestliže rozdělení jsou absolutně spojitá vzhledem k -rozměrné lebesgueově míře na , pak vůči ní mají také hustotu pravděpodobnosti. V textu pak značíme malým písmenem hustotu pravděpodobnosti rozdělení znaků pozorovaných na objektech z třídy .



Čtenář, který není dostatečně obeznámen s teorií pravděpodobnosti může (byť s malou újmou na obecnosti, ne však takovou, která by znemožnila pochopení textu) předpokládat, že hustoty pravděpodobnosti rozdělení znaků ve všech třídách existují. Hustotu si pak může představovat jako funkci definovanou na všech možných znacích (na ), zobrazující do množiny nezáporných čísel (do ), která udává „jak často“ se daný znak vyskytuje při velkém počtu pozorování. Přesněji, integrál z hustoty přes nějakou oblast znaků určuje, s jakou pravděpodobností na náhodně zvoleném objektu z třídy budeme pozorovat znak z oblasti , pro .o


Dále se zpravidla předpokládá modelová situace, že náhodně zvolený objekt pochází z třídy s pravděpodobností pro , takže rozdělení pak mají význam podmíněných rozdělení s podmínkou, že objekt pochází z třídy . Jestliže existují hustoty , pak celková směs má hustotu pro danou jako

- .

Na náhodně zvoleném objektu tedy modelově naměříme znak s pravděpodobností, která je daná hustotou .

Rozhodovací pravidlo
V DA se objekty rozlišují na základě rozhodovacího pravidla.
- Deterministické rozhodovací pravidlo je zobrazení definované na množině všech přípustných znaků pozorovaných na objektech (uvažujeme obecně ), které zobrazuje do množiny tříd, tj. do množiny . Deterministickým pravidlem je tedy rozlišení objektů jednoznačně určeno. Aplikací tohoto pravidla na vektor znaků příslušící nějakému objektu totiž začlení objekt do právě jedné ze tříd. Každé deterministické rozhodovací pravidlo lze charakterizovat uspořádaným souborem (-ticí) disjunktních množin pokrývajících množinu přípustných znaků (dále rozkladem) . Stačí pro dané zobrazení ztotožnit úplný vzor s množinou pro . Množinu všech rozkladů (resp. pravidel) budeme značit .




Ideálním rozhodovacím pravidlem je pravidlo, které začleňuje objekty do tříd, z nichž skutečně pochází. To samozřejmě prakticky téměř nikdy nelze zajistit. Okolí nějakého vektoru (zpravidla rozsáhlá podmnožina ) může mít tu vlastnost, že s významnou pravděpodobností se příslušné znaky (vektory z tohoto okolí) objevují na objektech z více než jedné třídy. Pozorujeme-li objekt se znaky z tohoto okolí, pak se nedokážeme jednoznačně (resp. na nějaké úrovni spolehlivosti) rozhodnout, ze které třídy objekt pochází. Pro lepší představu o rozlišení objektů se proto někdy zavádí následující zobecnění deterministického pravidla.
- Znáhodněné (randomizované) rozhodovací pravidlo je vektorová funkce definovaná také na množině všech znaků zobrazující ale do (tj. do kartézského součinu uzavřených jednotkových intervalů), přičemž jednotlivé složky obrazu vektoru znaků příslušící nějakému objektu odpovídají pravděpodobnostem zařazení tohoto objektu do příslušných tříd.

Deterministické rozhodovací pravidlo je speciálním případem znáhodněného. Lze totiž uvažovat u znáhodněného pravidla pouze vektorové funkce zobrazující do a ztotožnit kanonický vektor s třídou u deterministického pravidla.


Formulace úlohy DA
Úloha diskriminační analýzy se obecně skládá z více částí.
V první části předpokládáme, že na malé skupině z velkého počtu daných objektů (na tzv. trénovací množině) jsme schopni určit, z jaké třídy objekty pocházejí, resp. pro libovolnou třídu jsme schopni označit nějakou skupinu objektů, o kterých víme, že pocházejí z této třídy. Přitom uvažujeme, že takový postup přesného zařazení je pro větší skupiny objektů „nákladnější“, nebo časově náročnější, a přesné zařazení všech objektů je z hlediska těchto nákladů nepřípustné. Prvním úkolem DA je proto vhodně zvolit trénovací množinu.
V diskriminační části je úkolem na základě znaků pozorovaných na objektech ve zvolené trénovací množině sestavit rozhodovací pravidlo, tedy prediktor pro třídění zbylých objektů. Po rozhodovacím pravidle se obvykle požaduje, aby následovalo některé z kritérií uvedených v sekci Kritéria rozhodovacích pravidel. V dalších sekcích jsou naznačeny důvody, proč se tato kritéria jeví jako vhodná. V sekci s tradičními přístupy jsou pak popsány nejčastější postupy, kterými se dojde od modelového kritéria k explicitnímu vyjádření rozhodovacího pravidla.
Úkolem klasifikační části je rozčlenění zbylých objektů dle sestaveného rozhodovacího pravila, což je ryze výpočetní záležitost.
Součástí DA (stejně jako každé statistické procedury) by měla být správná interpretace kvality výsledného roztřídění, neboli odhad pravděpodobností chybné klasifikace.
Příklady použití
- V medicíně se DA využívá ke stanovení diagnózy na základě testů. Nejprve se za trénovací množinu vezme skupina pacientů doplněná několika zdravými jedinci. Předpokládá se, že u pacientů již byla nějaká z nemocí diagnostikována dříve, -tá třída znamená, že jedinec z této třídy je zdravý (nebo aspoň nemá žádnou ze sledovaných chorob). Trénovací množina se podrobí sérii různých druhů testů. Na základě výsledků těchto testů pak slouží teorie DA k sestavení pravidla pro určení diagnózy dalších osob na základě série stejných testů. Znáhodněné rozhodovací pravidlo například poskytne po otestování osoby informaci o tom, s jakou pravděpodobností trpí nějakou z chorob a pravděpodobnost, s jakou netrpí na žádnou z těchto chorob. Důležité je určit také spolehlivost pravidla. Pokud budou pacienti testováni takovými testy, jejichž výsledek vůbec nesouvisí s žádnou nemocí, pak sestavené pravidlo ani nemůže být spolehlivé.
- V bance může DA sloužit k rozhodnutí o přidělení úvěru. Pro jeden daný úvěrový produkt se tedy pracuje pouze s třídami. Klienti z první třídy jsou například ti spolehlivější, kteří celý úvěr splatí (s velmi malým rizikem nesplacení, např. 1% až 5%; nesplacení úvěru je pro banku spojeno s náklady). Banka si vede v evidenci u každého klienta několik znaků, jako např. druh zaměstnání, výše platu, apod. Na základě dat z minulosti pak může využít DA k sestavení pravidla, které dokáže rozhodnout o přidělení úvěru na základě dotazovaných znaků.
- Podobně se může škola rozhodovat o přijetí či nepřijetí studenta. Lze například sledovat výsledky z předchozích studií a výsledky přijímacích testů, a jednotlivé třídy pak mohou znamenat rok ukončení studia, a další třídy úspěšné absolvování studia, případně absolvování s vyznamenáním.


Kritéria rozhodovacích pravidel
Nechť je střední hodnota a rozptyl rozdělení znaků v třídě pro .


- Kritérium minimální Mahalanobisovy vzdálenosti zařazuje prvek se znaky do třídy s indexem
- ,

- tedy do takové třídy, která je nejblíže k vektoru ve smyslu Mahalanobisovy vzdálenosti.
Následující dvě kritéria mají smysl, existují-li hustoty rozdělení v třídách pro .
- Kritérium maximální věrohodnosti zařazuje prvek se znaky do třídy s indexem
- .

- Bayesovo kritérium zařazuje prvek se znaky do třídy s indexem
- .

Je ihned patrné, že Bayesovo kritérium je zobecněním kritéria maximální věrohodnosti, které zohledňuje apriorní pravděpodobnosti tříd. Anebo opačně můžeme říci, že kritérium maximální věrohodnosti je speciálním případem Bayesova kritéria, které využívá princip neurčitosti a za odhad apriorních pravděpodobností klade
- .

V následující sekci je demonstrováno, že Bayesovo pravidlo minimalizuje celkovou střední ztrátu vzniklou nesprávnou klasifikací pro konkrétní ohodnocení dílčích ztrát.
- Fisherovo kritérium zařazuje prvek se znaky do třídy s indexem
- ,
- kde pro matici mezitřídní variability a matici vnitrotřídní variability je
- .




Podrobněji se Fisherově metodě věnuje samostatná sekce.
Ekonomické ocenění rozhodovacího pravidla
Cílem sekce je ukázat jakým způsobem se převádí úloha výběru třídy na srovnávání skórů jednotlivých tříd pro daný znak . V této sekci se pracuje s pojmem střední hodnota, která (jednoduše řečeno) vyjadřuje „nejvíce očekávanou“ hodnotu pozorování na nějaké náhodné veličině (resp. náhodném vektoru).
Předpokládejme, že znak pozorovaný na náhodně zvoleném objektu je náhodný vektor , který se řídí distribucí (pravděpodobnostním rozdělením) směsi s hustotou popsané v odstavci s předpoklady, a příslušná podmíněná rozdělení mají hustoty pro . Dále si zvolme nějaké rozhodovací pravidlo dané rozkladem a oceňme ztrátu vzniklou použitím tohoto pravidla.



Označme hodnotu ztráty vzniklé zobrazením objektu pocházejícího z třídy zvoleným pravidlem na třídu . Objekt se znaky zobrazíme na třídu , jestliže . Takže za podmínky, že objekt se znaky pochází ze třídy , je pravděpodobnost zobrazení tohoto objektu na třídu dána jako



- .

Střední hodnota ztráty za podmínky, že objekt se znaky pochází ze třídy , pak má tvar
- .

Protože předpokládáme, že náhodně zvolený objekt pochází z třídy s pravděpodobností pro , je celková střední ztráta dána vztahem
- .

Z ekonomického hlediska je samozřejmě optimální preferovat pravidlo minimalizující celkovou střední ztrátu, tedy pravidlo
- .

Pro se definuje -tý diskriminační skór pro znak jako


- .

Celková střední ztráta vyjádřená pomocí skórů je pak
- .

Pro dané parametry úlohy a dané hodnoty ztrát pro jsou jednotlivé skóry jednoznačně určeny. Pro tyto hodnoty je optimálním pravidlem takové pravidlo, které maximalizuje příslušné integrály správným nastavením integračních oblastí . Tento požadavek lze vždy zajistit volbou takového pravidla, které se řídí dle hodnot nejvyššího skóru (proto také název skór nebo skóre) a objekt se znakem zařazuje do třídy


- .

Opačně lze také snadno ukázat, že pravidlo, které se řídí nejvyšším skórem, nabývá mezi všemi pravidly minimální celkové střední ztráty. Z toho důvodu je „ekonomicky nejvýhodnější“ nejprve pro všechny třídy určit (odhadnout) skóry (jakožto funkce ) a jednotlivé objekty v klasifikační části zařazovat do takové třídy, která má při pozorovaném znaku nejvyšší skór.
Běžně se volí hodnoty ztrát pro a . V takovém případě lze -tý skór dále upravit na tvar



- .

Protože hustota celkové směsi je v každém skóru stejná pro , je srovnávání skórů pro daný znak ekvivalentní srovnávání výrazů pro , což přesně odpovídá Bayesovu kritériu z předchozí sekce.


Fisherova DA
Uvažujme, že na náhodně zvoleném objektu naměříme náhodný vektor znaků . Idea Fisherova postupu spočívá v nalezení takové lineární transformace vektoru , při které se maximalizuje poměr součtu čtverců mezi třídami ku součtu čtverců uvnitř tříd. Jinými slovy, chceme nalézt takovou lineární funkci, která nejvíce eliminuje chybovou složku a umožní co nejlépe rozlišit objekty mezi jednotlivými třídami.

Z (mnohorozměrné) analýzy rozptylu (ANOVA, analysis of variance) víme, že celková variabilita vektoru , (ko)varianční matice (total variability), lze rozložit na součet matice mezitřídní variability (between-classes variability) a matice variability uvnitř tříd (within-classes variability). Obdobně pro rozptyly (jednorozměrné) náhodné veličiny platí následující vztah


- .

Fisherova lineární diskriminační funkce je taková funkce, která maximalizuje Fisherův poměr, tj. splňuje
- .

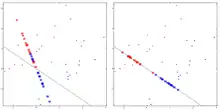
Na obrázku vpravo jsou znázorněna pozorování dvou znaků () na objektech ze dvou tříd (). Na objektech z jedné třídy jsou pozorované znaky znázorněné modře a na objektech z druhé třídy červeně. V levé části jsou znaky projektovány na přímku s nějakým náhodně zvoleným směrem. V pravé části jsou znaky projektovány na přímku se směrem odpovídajícím vektoru . Projekce vpravo mezi všemi možnými projekcemi umožňuje nejlépe rozlišit naměřené znaky.


Označíme-li počet prvků v trénovací množině pocházejících z třídy pro a celkový počet prvků v trénovací množině, pak jednotlivé matice se odhadují takto


- ,
- ,
- ,



kde jsou prvky z třídy pro a


- pro .

Je-li vlastní vektor příslušící největšímu vlastnímu číslu matice (místo vlastní číslo a vlastní vektor se také používají názvy charakteristické číslo a charakteristický vektor, vizte spektrální rozklad matice), pak lze ukázat, že maximalizuje Fisherův poměr, takže můžeme vždy položit , pro libovolný nenulový násobek .




Fisherovo diskriminační kritérium pak zařazuje objekt se znaky do takové třídy, jejíž obraz střední hodnoty znaků v transformaci je nejblíže obrazu (měří se vzdálenost na přímce), neboli do třídy
- .
Fisherův poměr je analogií technického pojmu poměr signálu a šumu (SNR, signal to noise ratio). Na přiloženém obrázku je znázorněno pro jednorozměrný případ (), jak ovlivňuje nastavení hranice rozlišující nějaký signál od šumu (jiného signálu, který nás nezajímá) poměr správných klasifikací signálu (hits), správných zamítnutí, že jde o signál (correct rejections), nesprávné klasifikace, že jde o signál, jedná-li se o šum (false alarms), a nesprávné klasifikace, že jde o šum, jedná-li se skutečně o signál (misses). Zelenou barvou je v obrázku znázorněna hustota výskytu signálu, který sledujeme, a červenou barvou hustota nějakých jiných signálů (šumu). Zmíněná hranice (criterion) je znázorněna svislou čarou. Příchozí události, které vykazují hodnoty (znaky) vpravo od svislé čáry pravidlo klasifikuje jako signál, hodnoty vlevo jako šum. Pravidlo na obrázku (dané svislou čarou) je vychýlené od pravidla, které bychom získali DA. Obrázek je výstupem kódu pro program Mathematica. Bližší informace o demonstraci (kódu) lze získat kliknutím na následující odkaz.

Wilksovo lambda
Wilksovo lambda je testová statistika, která se používá v mnohorozměrné analýze rozptylu k testování hypotézy odlišnosti průměrů znaků v jednotlivých třídách. Wilksovo lambda nabývá hodnot z intervalu , přičemž vyšší hodnoty znamenají, že průměry se liší méně. Při značení z předchozího odstavce se Wilksovo lambda definuje jako

- .

Čím nižší jsou hodnoty Wilksova lambda, tím spolehlivější je výsledek diskriminační části DA. Hodnota tedy odpovídá „perfektní diskriminaci“ objektů a hodnota znamená, že výsledek (lineární) DA nemá význam, protože objekty na základě pozorovaných znaků prakticky není možné rozlišit (lineární funkcí).


Další tradiční přístupy a speciální případy DA
Tato sekce se zaměřuje na diskriminační část DA. Nechť trénovací množina obsahuje prvků. Pokud apriorní pravděpodobnosti tříd nejsou známé, lze použít jejich odhad pro pomocí relativních četností


- ,

kde je počet prvků v trénovací množině pocházejících z třídy . V některých případech ale trénovací množina nemusí věrně reprezentovat skutečné relativní zastoupení prvků z příslušných tříd, například pokud do ní objekty nevybíráme náhodně. V takovém případě volíme odhad
- .
Dále v úloze DA v zásadě rozlišujeme dva základní přístupy.
- Parametrický přístup předpokládá, že pro jsou rozdělení znaků v třídě některá ze známých typů rozdělení charakterizovaných nějakým vektorem parametrů, a spočívá tedy v odhadu těchto parametrů. Nejčastěji se pracuje s normálními rozděleními, která jsou charakterizovaná střední hodnotou a rozptylem. K odhadu těchto parametrů se standardně využívají výběrový průměr a výběrová varianční matice, tedy pro klademe
- ,
- kde pro jsou prvky z třídy pro . Pokud předpokládáme rovnost variančních matic ve všech třídách , pak používáme odhad
- .
- Jestliže tedy předpokládáme normalitu všech rozdělení, pak příslušné hustoty pro odhadneme dosazením odhadnutých parametrů, tj pro
- .
- Dosazením získaných odhadů do některého z kritérií již získáme explicitně vyjádřené rozhodovací pravidlo.





- Neparametrický přístup používáme, pokud nemáme žádnou apriorní informaci o rozděleních . V této situaci se nabízí využít neparametrické metody odhadu hustot, např. jádrový odhad hustot. Pro další informace o neparametrickém přístupu v DA vizte článek M. Forbelské[4].

Pro DA pracující s diskrétními rozděleními se používá název diskriminační korespondenční analýza.[5]
Problémem parametrických modelů bývá citlivost na malé porušení předpokladu o rozdělení dat, které může výrazně ovlivnit výsledek DA. Jde především o odlehlá pozorování (vzniklá například nepřesným měřením), která mají vliv na hodnotu výběrového průměru i rozptylu. Jednou z alternativ je pak užití robustních metod, jejichž cílem je tyto nepříznivé vlivy eliminovat. V souvislosti s aplikací těchto metod v DA hovoříme o robustní diskriminační analýze, které se podrobněji věnuje diplomová práce E. Horákové[6].
Kvadratická diskriminační analýza (QDA)
Pokud v úloze DA předpokládáme, že rozdělení znaků v jednotlivých třídách pro jsou regulární -rozměrná normální rozdělení a pro diskriminaci objektů volíme Bayesovo kritérium, pak mluvíme o úloze kvadratické diskriminační analýzy. Dosazením hustoty lze Bayesovo kritérium upravit logaritmováním a odečtením konstanty (vzhledem k ).



Pro se výraz


nazývá -tý kvadratický diskriminační skór. Objekt s pozorovanými znaky tedy v kvadratické DA zařazujeme do třídy , jestliže
- .

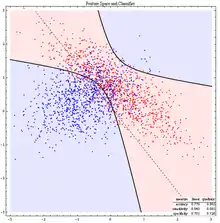
Jeden z možných výsledků kvadratické diskriminační analýzy ukazuje obrázek vpravo. Jsou na něm zakreslena pozorování dvou znaků () na objektech ze dvou tříd (). Znaky pozorované na objektech první třídy jsou zakresleny červenými body, znaky druhé modrými body. Za výsledek se v obrázku považuje rozklad roviny , kde označuje červenou oblast, modrou. Pokud bychom v klasifikační části DA pozorovali objekt s vektorem znaků , který patří do červené oblasti , zařadili bychom takový objekt podle výsledného pravidla do první (červené) třídy . Jak je vidět, hranicí mezi oběma oblastmi je kuželosečka. Ve vyšší dimenzi by obecněji byla hranicí vždy kvadrika. Přerušovaná čára pak naznačuje hranici mezi oblastmi, které by byly výsledkem aplikace lineární diskriminační analýzy na stejný soubor pozorování, vizte dále.





Lineární diskriminační analýza (LDA)
Lineární diskriminační analýza je speciálním případem kvadratické DA, kde navíc předpokládáme, že normální rozdělení v jednotlivých třídách mají stejnou kovarianční strukturu, tj. . V tomto případě lze pokračovat v úpravě rozhodovacího z předchozího odstavce roznásobením a odečtením výrazů nezávislých na , čímž dostaneme kritérium v následující podobě
- .

Pro se výraz

nazývá -tý lineární diskriminační skór. Objekt s pozorovanými znaky v lineární DA zařazujeme do třídy , pokud platí
- .
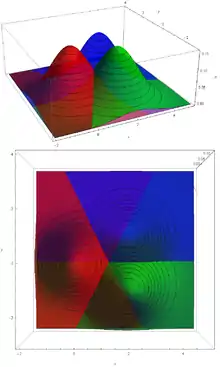
Na obrázku jsou vidět hustoty dvourozměrných normálních rozdělení () se stejnou jednotkovou varianční maticí a různými středními hodnotami. Matematicky zapsáno, červená, zelená a modrá hustota postupně přísluší třídám s rozděleními


- .

Při pohledu shora lze vidět barevně rozlišené jednotlivé části roviny , které by odpovídaly pravidlu získanému použitím kritéria maximální věrohodnosti. Toto pravidlo totiž zařazuje objekt se znaky do takové třídy, která má v bodě nejvyšší hustotu. Kdybychom tedy například měli na základě tohoto pravidla klasifikovat objekt, na kterém pozorujeme znaky (vektor) , zařadili bychom jej do třídy , protože náleží do červené oblasti . Z obrázku je taky patrné, proč se používá název lineární DA. Důvod je ten, že pravidlo získané LDA rozlišuje každé dvě třídy pomocí lineární funkce (zobrazující z do ), takže jednotlivé dvojice tříd jsou odděleny vždy nadrovinou v , speciálně v přímkou, v bodem.



Regularizovaná diskriminační analýza (RDA)
Regularizovaná diskriminační analýza je DA vzniklá kombinací LDA a QDA, kde se optimalizuje kombinace rozptylových matic. Tato metoda byla uvedena J.H. Friedmanem v roce 1988[7] a patří mezi často používané metody DA.
Odhady pravděpodobností správné klasifikace
Samotný výsledek diskriminační části DA, tj. samotné rozhodovací pravidlo, je bezcenný, pokud nemáme dodatečné informace o jeho spolehlivosti.
- Základní odhad pravděpodobnosti správného zařazení získáme aplikací sestaveného rozhodovacího pravidla na všech objektů z trénovací množiny. Označme počet prvků trénovací množiny pocházejících z třídy , které rozhodovací pravidlo zařazuje do třídy . Potom matice relativních četností



- dává odhady příslušných pravděpodobností. Na diagonále matice jsou postupně odhady pravděpodobností správné klasifikace pro jednotlivé třídy, takže stopa matice (součet prvků na diagonále) pak udává optimistický odhad celkové pravděpodobnosti správného zařazení náhodně zvoleného prvku. Samozřejmě každý z objektů se byť malou měrou podílí na konstrukci rozhodovacího pravidla, což „zvyšuje jeho šanci“ na správné zařazení tímto pravidlem.
- Křížový odhad (Cross Validation) spočívá v náhodném rozdělení trénovací množiny na dva soubory. Na první soubor aplikujeme diskriminační část DA, kterou získáme rozhodovací pravidlo. Na druhém souboru pak prověřujeme kvalitu získaného pravidla základním postupem (z předchozího odstavce). Tento postup sice oproti předchozímu „nezvýhodňuje“ objekty při klasifikaci, ale klade pro srovnatelnou hodnotu odhadu vyšší nároky na velikost trénovací množiny. Tento postup se používá pouze pro odhad pravděpodobností správné klasifikace, vlastní rozhodovací pravidlo se utvoří podle celé trénovací množiny, tj. stejně jako u následující metody.
- Metoda Jackknife pro každý z objektů trénovací množiny vytvoří rozhodovací pravidlo na základě zbylých objektů, a příslušný vynechaný prvek pak tímto pravidlem testuje, zda je správně zařazen. Celkem je tedy nutné -krát použít diskriminační část DA, což může být výpočetně náročný proces. Dále se postupuje analogicky jako u základního odhadu. Ke klasifikaci se pak používá rozhodovací pravidlo utvořené na základě všech prvků trénovací množiny, které se pro velká „významně neliší“ od každého z pravidel získaných vynecháním jednoho objektu.

Odkazy
Reference
Odstavec o historii je volnou parafrází diplomové práce[6], doplněnou o některé informace z anglické wikipedie. Matematická část byla zpracována převážně na základě přednášky Mnohorozměrná statistická analýza konané na MFF UK vedené Doc. RNDr. Janem Hurtem, CSc.
- Fisher, R.A.: The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7: 179-188; 1936.
- Tatsuoka, M.M.; Tiedeman, D.V.: Discriminant Analysis. Review of Educational Research, Vol. 24, No. 5, 402-420; 1954.
- Klecka, W.R.: Discriminant Analysis (Quantitative Applications in the Social Sciences). Sage Publications; 1980. ISBN 978-0-8039-1491-9.
- Forbelská, M.: Neparametrická diskriminační analýza. Sborník prací 11. letní školy ROBUST 2000. Praha; Jednota českých matematiků a fyziků, 2001. str. 50-58. ISBN 80-7015-792-5.
- Abdi, H.: Discriminant Correspondence Analysis. Neil Salkind (Ed.): Encyclopedia of Measurement and Statistics, Thousand Oaks (CA): Sage; 2007.
- Horáková, E.: Robustní metody v diskriminační analýze. (Diplomová práce); 2008.
- Friedman, J.H.: Regularized Discriminant Analysis. Journal of the American Statistical Association, 84(405):165-175, 1989.
Externí odkazy
Srozumitelné vysvětlení základních postupů DA v pracovním textu k přednášce na ZČU v Plzni:
- DA-přednáška[nedostupný zdroj]
Názorné příklady použití DA na stránkách demonstrations.wolfram.com (vše anglicky):
- Signal Detection Theory
- Fisher Discriminant Analysis
- Pattern Recognition Primer
- Pattern Recognition Primer II
Prezentace Doc. Hurta pro uživatele systému Mathematica:
Mnoho vědeckých článků o DA (v angličtině) je dostupných v pdf na sciencedirect.com: