EM algoritmus
EM algoritmus (z anglického expectation–maximization – očekávaná (střední) hodnota–maximalizace) je ve statistice iterační metoda pro hledání maximálně věrohodného odhadu nebo odhadu parametrů statistického modelu s maximální aposteriorní pravděpodobností (MAP), který závisí na nepozorovaných skrytých proměnných. Při EM iteracích se pravidelně střídají kroky výpočtu střední hodnoty (očekávání, E) s kroky maximalizace (M). V kroku E se vytváří očekávaná logaritmická věrohodnostní funkce na základě aktuálního odhadu parametrů. V kroku M se počítají parametry maximalizující očekávanou logaritmickou věrohodnostní funkci nalezenou v kroku E. Tyto odhady parametrů se pak používají pro určení rozdělení skrytých proměnných v dalším kroku E.
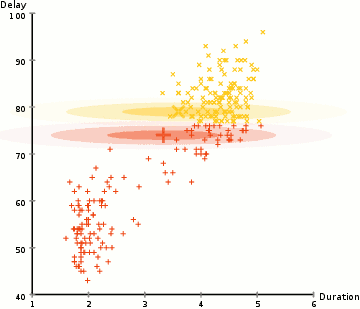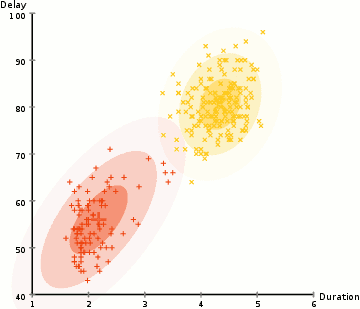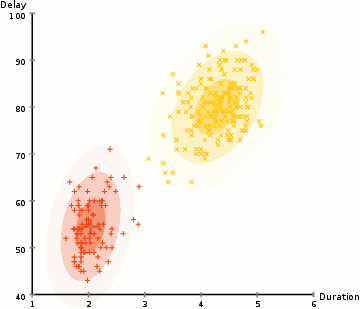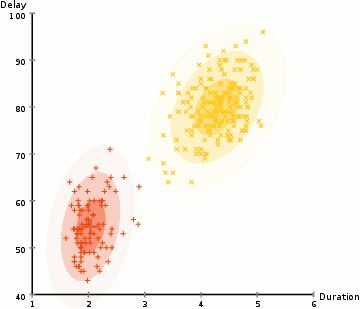
Historie
EM algoritmus popsali, vysvětlili a pojmenovali Arthur P. Dempster, Nan Laird a Donald Rubin v klasickém článku z roku 1977,[1] ve kterém zmínili, že EM algoritmus byl v minulosti „mnohokrát navržen a popsán pro speciální případy“ jinými autory. Jedním z prvních popisů byla metoda počítání genů pro odhadování frekvence alel, kterou popsal Cedric Smith[2]. Velmi podrobný popis EM metody pro exponenciální funkce publikoval Rolf Sundberg ve své diplomové práci a několika odborných článcích[3][4][5] vzniklých při jeho spolupráci s Per Martin-Löfem a Anders Martin-Löfem[6][7][8][9][10].[11][12] Článek Dempstera, Lairda a Rubina z roku 1977 zobecňuje metodu a načrtává analýzu konvergence pro širší třídu problémů. Bez ohledu na dřívější objevy, inovativní článek Dempstera, Lairda a Rubina v Journal of Royal Statistical Society vyvolal nadšenou diskuzi na setkání Royal Statistical Society se Sundberg vedl k označení článku za „brilantní“. Zmiňovaný článek učinil z EM metody důležitý nástroj statistické analýzy.
Později se ukázalo, že analýza konvergence EM algoritmu ve výše zmíněném článku byl chybná; opravenou analýzu konvergence publikoval C. F. Jeff Wu v roce 1983.[13] Jeho důkaz prokázal konvergenci EM metody i mimo rodinu exponenciálních rozdělení, kterou vyžadoval původní článek.[13]
Úvod
EM algoritmus se používá pro hledání (lokální) maximálně věrohodných parametrů statistického modelu v případech, kdy rovnice nelze vyřešit přímo. Tyto modely typicky kromě neznámých parametrů a známých dat pozorování zahrnují skryté proměnné. To znamená, že buď v datech existují chybějící hodnoty nebo lze model formulovat jednodušeji, pokud předpokládáme, že existují další nepozorované datové body. Například smíšený model lze popsat jednodušeji, pokud předpokládáme, že ke každému pozorovanému datovému bodu existuje další nepozorovaný datový bod nebo skrytá proměnná, která popisuje kombinační komponentu, do které každý datový bod patří.
Hledání maximálně věrohodného řešení typicky vyžaduje použití derivace věrohodnostní funkce podle všech neznámých hodnot, parametrů a skrytých proměnných a současně řešení výsledné rovnice. U statistických modelů se skrytými proměnnými to obvykle není možné. Místo toho bývá výsledkem soustava vzájemně propojených rovnic, ve které řešení parametrů vyžaduje hodnoty skrytých proměnných a naopak, přičemž substituce jedné sady rovnic do druhé produkuje neřešitelné rovnice.
EM algoritmus vychází z pozorování, že tyto dvě sady rovnic lze řešit numericky: Je možné vybrat libovolné hodnoty pro jednu ze obou sad neznámých a pomocí nich odhadnout druhou sadu. Pak pomocí nových hodnot najít lepší odhad první sady, a tak pokračovat ve střídání obou kroků dokud výsledné hodnoty nekonvergují k pevným bodům. Lze dokázat, že v tomto kontextu tento postup konverguje, a že v tomto bodě je derivace věrohodnostní funkce libovolně blízko k nule, což znamená, že nalezený bod je buď maximem nebo sedlovým bodem.[13] Obecně však může existovat více maxim, a není záruka, že algoritmus nalezne globální maximum. Některé věrohodnostní funkce mají v sobě také singularity, tj. nesmyslná maxima. Například jedno z řešení, které může EM algoritmus nalézt ve smíšeném modelu, spočívá v tom, že jedna ze složek má nulový rozptyl a střední parametr pro stejnou složku se rovná jednomu z datových bodů.
Popis
Je-li dán statistický model, který generuje množinu pozorovaných dat, množina nepozorovaných skrytých dat nebo chybějících hodnot a vektor neznámých parametrů , spolu s věrohodnostní funkcí , pak maximálně věrohodný odhad (MLE) neznámých parametrů je určen maximalizací marginální věrohodnosti pozorovaných dat





Tato hodnota je však často nevyčíslitelná (například pokud je posloupnost událostí, poroste počet hodnot exponenciálně s délkou posloupnosti, takže přesný výpočet sumy bude extrémně obtížný).
EM algoritmus se snaží najít MLE marginální věrohodnosti iterativním používáním následujících dvou kroků:
- E krok (Expectation): Definujeme jako očekávanou hodnotu logaritmické věrohodnostní funkce , vzhledem k aktuálnímu podmíněnému rozdělení pravděpodobnosti pro dané a aktuální odhady parametrů :



- M krok (Maximalizace): Najdeme parametry, které maximalizují následující výraz:

Typické modely, na které se EM aplikuje, používají jako skrytou proměnnou, což udává příslušnost k jedné z následujících situací:
- Pozorované datové body mohou být diskrétní (hodnoty tvoří konečnou nebo spočetně nekonečnou množinu) nebo spojité (hodnoty tvoří nespočetně nekonečnou množinu). Každému bodu dat může být přiřazen vektor pozorování.
- Chybějící hodnoty (nazývané také skryté proměnné) jsou diskrétní, vybírané z pevného počtu hodnot a s jednou skrytou proměnnou na pozorovanou jednotku.
- Parametry jsou spojité a jsou dvou druhů: Parametry, které jsou přiřazené k všem datovým bodům, a parametry přiřazené určité hodnotě skryté proměnné (tj. přiřazené ke všem datovým bodům, jejichž odpovídající skrytá proměnná má tuto hodnotu).
EM je však možné aplikovat i na jiné třídy modelů.
Motivace je následující: Pokud jsou známé hodnoty parametrů , lze hodnotu skryté proměnné obvykle nalézt maximalizací logaritmické věrohodnostní funkce přes všechny možné hodnoty , buď jednoduše iterováním přes nebo pomocí nějakého algoritmu, například Baumova–Welchova algoritmu pro skryté Markovovy modely. Pokud naopak známe hodnoty skryté proměnné , můžeme nalézt odhad parametrů docela snadno, typicky jednoduchým seskupováním pozorovaných datových bodů podle hodnoty příslušných skrytých proměnných a průměrováním hodnot, nebo nějaké funkce hodnot, bodů z každé skupiny. V případě, když i jsou neznámé, nabízí se použít iterativní algoritmus:
- Nejdříve inicializovat parametry na nějaké náhodné hodnoty.
- Spočítat pravděpodobnost každé možné hodnoty pro dané .
- Pak, použít právě vypočtené hodnoty pro vypočítání lepšího odhadu parametrů .
- Opakovat kroky 2 a 3 dokud nekonvergují.
Právě popsaný algoritmus se monotónně přibližuje lokálnímu minimu nákladové funkce.
Vlastnosti
Označení krok očekávání (E) je poněkud nevhodné pojmenování. V prvním kroku se počítají pevné parametry funkce Q (závislé na datech). Jakmile jsou parametry Q známé, je Q plně určena a ve druhém (M) kroku EM algoritmu se provádí její maximalizace.
Ačkoli EM iterace skutečně zvyšuje (marginální) hodnotu věrohodnostní funkce na pozorovaných datech, není záruka, že posloupnost konverguje k odhadu maximální věrohodnosti. Pro multimodální distribuce to znamená, že EM algoritmus může konvergovat k lokálnímu maximu pozorované věrohodnostní funkce, v závislosti na počátečních hodnotách. Pro únik z lokálního maxima existuje množství heuristik a metaheuristik, například gradientní algoritmus s opakovaným náhodným startem (začíná s několika různými náhodnými počátečními odhady θ(t)) nebo použití metod simulovaného žíhání.
EM algoritmus je zvláště užitečný, když věrohodnost patří do rodiny exponenciálních rozdělení: v kroku E se použije suma očekávání dostačujících statistik a v kroku M se maximalizuje lineární funkce. V takovém případě je obvykle možné odvodit tvaru analytické řešení aktualizací v každém kroku pomocí Sundbergova vzorce (který publikoval Rolf Sundberg na základě nepublikovaných výsledků Per Martin-Löfa a Anders Martin-Löfa).[4][5][8][9][10][11][12]
V původním článku od Dempstera, Lairda a Rubina byla uvedena úprava EM metody pro výpočet maximálního aposteriorního odhadu (MAP) pro Bayesovské vyvozování.
Existují i jiné metody pro hledání maximálně věrohodných odhadů, jako například metoda gradientního spádu, metoda sdružených gradientů nebo varianty Gaussova–Newtonova algoritmu. Na rozdíl od EM však tyto metody typicky vyžadují vyhodnocování první nebo druhé derivace věrohodnostní funkce.
Důkaz korektnosti
EM algoritmus se snaží zlepšit , místo toho, aby přímo zlepšoval . Ukážeme, že vylepšení prvního znamená také vylepšení druhého.[14]

Pro jakékoli s nenulovou pravděpodobností , můžeme psát


Vezměme očekávání přes možné hodnoty neznámých dat podle aktuálního odhadu parametru , znásobíme obě strany a sečteme (nebo zintegrujeme) podle . Levá strana je očekávaná hodnota konstanty, takže dostáváme:



kde je definované jako opačná hodnota součtu, který nahrazuje. Tato poslední rovnice platí pro každou hodnotu , včetně ,



a odečtením této poslední rovnice od předchozí rovnice dává

Jensenova nerovnost nám však říká, že , z čehož můžeme vyvodit, že


Neboli výběr pro zlepšení způsobí, že se zlepší nejméně o totéž.
Jako postup maximalizace maximalizace
EM algoritmus lze chápat jako dva střídající se kroky maximalizace, tj. jako příklad vzestupu podle souřadnice.[15][16] Uvažujme funkci:

kde q je libovolné rozdělení pravděpodobnosti nepozorovaných dat z a H(q) je entropie rozdělení q. Tuto funkci lze zapsat jako

kde je podmíněné rozdělení pravděpodobnosti nepozorovaných dat, jsou-li dána pozorovaná data , a je Kullbackova–Leiblerova divergence.



Pak na kroky v EM algoritmu můžeme pohlížet jako:
- Expectation krok: Zvolíme , které maximalizuje :
- Maximalizační krok: Zvolíme , které maximalizuje :





Aplikace
EM se často používá pro shlukovou analýzu ve strojovém učení a počítačovém vidění. Při zpracování přirozeného jazyka se velmi často používají dvě varianty EM algoritmu – Baumův–Welchův algoritmus pro skryté Markovovy modely a inside-outside algoritmus pro učení pravděpodobnostních bezkontextových gramatik bez učitele.
EM se často používá pro odhad parametrů smíšených modelů,[17][18] především v kvantitativní genetice[19].
V psychometrice je EM algoritmus téměř nepostradatelný pro odhadování parametrů položek a skrytých schopností modelů teorie odpovědi na položku.
Díky schopnosti pracovat s chybějícími daty a pozorovat neidentifikované proměnné se EM stává užitečným nástrojem pro oceňování a správu rizik portfolia.
EM algoritmus (a jeho rychlejší varianta OSEM Ordered subset expectation maximization) se často používá při vytváření obrazu v zobrazovacích metodách v lékařství, zvláště pro pozitronovou emisní tomografii a jednofotonovou emisní výpočetní tomografii. Rychlejší varianty EM jsou popsány dále.
Ve strukturálním inženýrství je algoritmus STRIDE Structural Identification using Expectation Maximization[20] pouze výstupní metoda pro identifikaci přirozených vibračních vlastností strukturálního systému pomocí senzorových dat (viz operační modální analýza).
EM algoritmy pro filtrování a vyhlazování
Kalmanův filtr se typicky používá pro online odhad stavu a vyhlazování s minimálním rozptylem může být použito pro offline nebo dávkový odhad stavu. Nicméně tato řešení s minimálním rozptylem vyžadují odhady parametrů modelu stavového prostoru. EM algoritmy lze používat pro řešení problémů sdružených stavů a odhady parametrů.
Filtrovací a vyhlazovací EM algoritmy vznikají opakováním následujícího dvoukrokového postupu:
- krok E
- Použít Kalmanův filtr nebo vyhlazování s minimálním rozptylem navržený s odhady aktuálních parametrů pro získání odhadů aktualizovaných stavů.
- krok M
- Použití filtrovaných nebo vyhlazených odhadů stavu pro výpočet maximální věrohodnosti pro získání odhadů aktualizovaných parametrů.
Předpokládejme, že Kalmanův filtr nebo vyhlazování s minimálním rozptylem pracuje s měřeními systému s jediným vstupem a jediným výstupem, který je ovlivněn aditivním bílým šumem. Aktualizovaný odhad měření rozptylu šumu lze získat z výpočtu maximální věrohodnosti

kde jsou odhady skalárního výstupu vypočítané filtrem nebo vyhlazováním z N skalárních měření . Výše uvedená aktualizace může také být aplikována na aktualizaci Poissonovo měření intenzity šumu. Podobně pro autoregresivní proces prvního řádu lze vypočítat odhad rozptylu aktualizovaného šumu procesu podle vzorce



kde a jsou skalární odhady stavu vypočítané filtrem nebo vyhlazování. Aktualizovaný odhad koeficientů modelu je získaný podle vzorce


Konvergence odhadů parametrů obdobných jako jsou uvedeny výše jsou dobře studované.[21][22][23][24]
Varianty
Bylo navrženo několik metod pro zrychlení někdy pomalé konvergence EM algoritmu, například metody používající sdružený gradient a modifikace Newtonovy metody (Newtonova–Raphsonova metoda)[25]. EM lze také používat pro metody omezeného odhadu.
Algoritmus Parameter-expanded expectation maximization (PX-EM) vede často ke zrychlení díky „použití `nastavení kovariance' pro opravu analýzy kroku M, přičemž využívá zvláštní informace zachycené v přisuzovaných úplných datech“[26].
Expectation conditional maximization (ECM) nahrazuje každý M krok v posloupností kroků podmíněné maximalizace (CM), ve kterých se každý parametr θi maximalizuje samostatně, když se ostatní parametry nemění.[27] Rozšířením tohoto algoritmu je Expectation conditional maximization either (ECME).[28]
Uvedený přístup lze dále rozšířit na algoritmus generalized expectation maximization (GEM), u kterého se hledají pouze přírůstky účelové funkce F jak v kroku E tak v kroku M, jak je popsané v části Jako postup maximalizace maximalizace.[15] GEM se dále vyvíjí v distribuovaném prostředí a vykazuje slibné výsledky.[29]
Je také možné považovat EM algoritmus za podtřídu MM algoritmu (Majorize/Minimize nebo Minorize/Maximize, podle kontextu),[30][31] a používat pro něj všechny techniky vyvinuté pro obecnější případ.
α-EM algoritmus
Funkce Q používaná v EM algoritmu je založena na logaritmické věrohodnostní funkci. Proto je považována za log-EM algoritmus. Použití logaritmické věrohodnostní funkce lze zobecnit na použití α-logaritmu poměru věrohodností. Potom lze α-log poměru věrohodností pozorovaných dat přesně vyjádřit jako rovnost použitím funkce Q aplikované na α-logaritmus poměru věrohodností a α-divergence. Získání této funkce Q je zobecněný krok E. Jeho maximalizace je zobecněný krok M. Výsledný algoritmus se nazývá α-EM algoritmus. [32] α-EM algoritmus, jehož autorem je Yasuo Matsuyama je zobecněním log-EM algoritmu. Není potřeba žádný výpočet gradientu nebo matice Hessianů. Při výběru vhodného α vykazuje α-EM algoritmus rychlejší konvergenci než log-EM. α-EM algoritmus vede k rychlejší verzi algoritmu α-HMM odhadu skrytých Markovových modelů. [33]
Vztah k variačním Bayesovským metodám
EM je částečně nebayesovská metoda založená na maximální věrohodnosti. Její konečný výsledek dává rozdělení pravděpodobnosti přes skryté proměnné (v Bayesovském stylu) spolu s bodovým odhadem θ (buď maximálně věrohodný odhad anebo v a posterior režimu). Může být požadována jeho plně Bayesovská verze, která dává rozdělení pravděpodobnosti podle θ a skryté proměnné. Při Bayesovském přístupu k inference bychom jednoduše považovali θ za další skrytou proměnnou. Při tomto přístupu mizí rozdíl mezi kroky E a M. Při použití faktorizované aproximace Q popsané výše (variační Bayesovská metoda) může řešení iterovat přes každou skrytou proměnnou (včetně θ) a optimalizovat je po jedné. Nyní je potřeba k kroků pro každou iteraci, kde k je počet skrytých proměnných. Pro grafické modely je to snadné udělat, protože nové Q pro každou proměnnou závisí pouze na jeho Markovově blanketu, takže pro efektivní inference lze používat lokální předávání variačních zpráv (Variational message passing, VMP).
Geometrická interpretace
V informační geometrii jsou kroky E a M interpretovány jako projekce pod duální afinní konexe, nazývané e-spojení a m-spojení; Pomocí těchto termínů lze pohlížet na Kullbackovu–Leiblerovu divergenci.
Příklady
Smíšené normální rozdělení
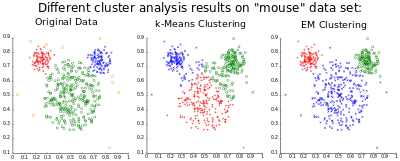
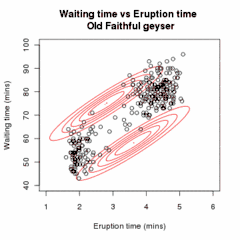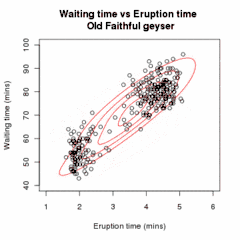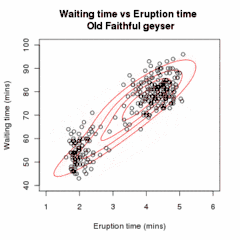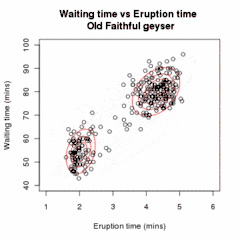
Nechť jsou vzorky nezávislých pozorování z kombinace dvou vícerozměrných normálních rozdělení dimenze a nechť jsou skryté proměnné, které určují komponentu, z nichž pozorování pochází[16].




- a


kde
- a


Cílem je odhadnout neznámé parametry reprezentující mísení hodnot dvou normálních rozdělení a střední hodnoty a kovariance obou:

kde Věrohodnostní funkce věrohodnosti pro neúplná data je
- ,

a Věrohodnostní funkce věrohodnosti pro úplná data je

nebo

kde je charakteristická funkce a je hustota pravděpodobnosti vícerozměrného normálního rozdělení.


V poslední rovnosti se pro každé i jedna hodnota charakteristické funkce rovná nule a jedna jedničce. Vnitřní součet tedy má vždy pouze jeden člen.

Krok E
Máme-li aktuální odhad parametrů θ(t), bude podmíněné rozdělení pravděpodobnosti Zi určeno Bayesovou větou, aby to byla proporcionální výška normální hustoty vážená parametrem τ:
- .

Tyto hodnoty, které jsou obvykle považovány za výstup kroku E (přestože to není funkce Q popsaná níže), se nazývají „členské pravděpodobnosti“.
Tento E krok odpovídá nastavení této funkce pro Q:

Střední hodnota („očekávání“) v sumě se bere vzhledem k hustotě pravděpodobnosti , která může být pro každé z trénovací množiny jiná. Před provedením kroku E jsou známé všechny potřebné hodnoty kromě , které se počítají podle rovnice na začátku kroku E.




Tuto plně podmíněnou střední hodnotu není třeba počítat v jednom kroku, protože τ a μ/Σ se vyskytují ve zvláštních lineárních členech a mohou být tedy maximalizovány nezávisle.
Krok M
Protože Q(θ | θ(t)) je kvadratická funkce, je určování maximalizujících hodnot θ relativně přímočaré. Také τ, (μ 1,Σ1) a (μ 2,Σ2) mohou být vesměs maximalizovány nezávisle, protože se všechny vyskytují v samostatných lineárních členech.
Pro začátek uvažujme τ s omezením τ1 + τ2=1:

což má stejný tvar jako MLE pro binomické rozdělení, takže
- .

Pro další odhady (μ 1,Σ1):
- .

což má stejný tvar jako vážené MLE pro normální rozdělení, takže
- a


a díky symetrii
- a .


Ukončení
Iterativní proces ukončíme, jakmile pro předem zvolenou hodnotu .


Zobecnění
Výše popsaný algoritmus lze zobecnit pro kombinaci více než dvou vícerozměrných normálních rozdělení.
Zkrácená a cenzurovaná regrese
EM algoritmus byl implementován pro případ, kdy existuje podkladový model lineární regrese, který vysvětluje variace určité velikosti, ale skutečně pozorované hodnoty jsou cenzurovanou nebo zkrácenou verzí hodnot reprezentovaných v modelu.[34] Speciální případy tohoto modelu zahrnují cenzurované nebo zkrácené pozorování z jednoho normální rozdělení.[34]
Alternativy
EM algoritmus typicky konverguje k lokální optimu. Toto lokální optimum však nemusí být globálním optimem, a také nemáme jakýhokoli odhad rychlosti konvergence. V mnoharozměrném prostoru může být konvergence libovolně špatná a může existovat exponenciální počet lokálních optim. Proto existuje potřeba pro alternativní metody pro zaručené učení, zvláště v mnohadimanzionálních prostředích. Vedle algoritmu EM existují i jiné algoritmy, které lépe zaručují konzistenci. Tyto algoritmy využívají přístupy založené na momentech[35] nebo tak zvané spektrální techniky[36][37]. Zájem o algoritmy pro učení parametrů pravděpodobnostního modelu používající momenty se v poslední době stále zvyšuje, protože za určitých podmínek mohou na rozdíl od EM algoritmu, jehož velkým problémem je uváznutí v lokálním optimu, zaručit například globální konvergenci. Algoritmy se zaručeným učením mohou být odvozeny pro několik důležitých modelů, jako jsou smíšené modely, skryté Markovovy modely atd. V těchto spektrálních metodách, se neobjevují žádná nepravá lokální optima, a skutečné parametry lze při splnění určitých podmínek regularity konzistentně odhadnout.
Odkazy
Reference
V tomto článku byl použit překlad textu z článku Expectation–maximization algorithm na anglické Wikipedii.
- DEMPSTER, A.P.; LAIRD, N.M.; RUBIN, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of Royal Statistical Society, Series B. 1977. JSTOR 2984875.
- CEPPELINI, R.M. The estimation of gene frequencies in a random-mating population. Ann. Hum. Genet.. 1955. DOI 10.1111/j.1469-1809.1955.tb01360.x. PMID 13268982.
- SUNDBERG, Rolf. Maximum likelihood theory for incomplete data from an exponential family. Scandinavian Journal of Statistics. 1974. JSTOR 4615553.
- SUNDBERG, Rolf. Maximum likelihood theory and applications for distributions generated when observing a function of an exponential family variable. , 1971. disertační práce. Institute for Mathematical Statistics, Stockholm University. .
- SUNDBERG, Rolf. An iterative method for solution of the likelihood equations for incomplete data from exponential families. Communications in Statistics – Simulation and Computation. 1976. DOI 10.1080/03610917608812007.
- Viz uznání od Dempstera, Lairda a Rubina na stránkách 3, 5 a 11.
- KULLDORFF, G. Contributions to the theory of estimation from grouped and partially grouped samples. [s.l.]: Almqvist & Wiksell, 1961.
- MARTIN-LÖF, Anders. Utvärdering av livslängder i subnanosekundsområdet (Evaluace sub-nanosekondových dob života). [s.l.]: [s.n.], 1963.
- MARTIN-LÖF, Per. Statistics from the point of view of statistical mechanics. [s.l.]: Matemathical Institute, Aarhus University., 1966. Za autora „Sundbergova vzorce“ se považuje Anders Martin-Löf.
- MARTIN-LÖF, Per. Statistika Modeller (Statistical Models): Anteckningar från seminarier läsåret 1969–1970. [s.l.]: [s.n.], 1970. S asistencí Rolfa Sundberga, Stockholm University („Sundbergův vzorec“).
- MARTIN-LÖF, P. The notion of redundancy and its use as a quantitative measure of the deviation between a statistical hypothesis and a set of observational data. With a discussion by F. Abildgård, A. P. Dempster, D. Basu, D. R. Cox, A. W. F. Edwards, D. A. Sprott, G. A. Barnard, O. Barndorff-Nielsen, J. D. Kalbfleisch and G. Rasch and a reply by the author. 1. vyd. Aarhus: Dept. Theoret. Statist., Inst. Math., Univ. Aarhus, 1974.
- MARTIN-LÖF. The notion of redundancy and its use as a quantitative measure of the discrepancy between a statistical hypothesis and a set of observational data. Scand. J. Statist.. 1974.
- WU, C. F. Jeff. On the Convergence Properties of the EM Algorithm. Annals of Statistics. Mar 1983. DOI 10.1214/aos/1176346060. JSTOR 2240463.
- LITTLE, Roderick J.A.; RUBIN, Donald B. Statistical Analysis with Missing Data. New York: John Wiley & Sons, 1987. (Wiley Series in Probability and Mathematical Statistics). ISBN 978-0-471-80254-9.
- NEAL, Radford; HINTON, Geoffrey. A view of the EM algorithm that justifies incremental, sparse, and other variants. Cambridge, MA: MIT Press, 1999. Dostupné online. ISBN 978-0-262-60032-3.
- HASTIE, Trevor; TIBSHIRANI, Robert; FRIEDMAN, Jerome. The Elements of Statistical Learning. New York: Springer, 2001. ISBN 978-0-387-95284-0. Kapitola The 8.5 EM algorithm.
- LINDSTROM, Mary J; BATES, Douglas M. Newton—Raphson and EM Algorithms for Linear Mixed-Effects Models for Repeated-Measures Data. Journal of the American Statistical Association. 1988. DOI 10.1080/01621459.1988.10478693.
- VAN DYK, David A. Fitting Mixed-Effects Models Using Efficient EM-Type Algorithms. Journal of Computational and Graphical Statistics. 2000. DOI 10.2307/1390614. JSTOR 1390614.
- DIFFEY, S. M; SMITH, A. B; WELSH, A. H; CULLIS, B. R. A new REML (parameter expanded) EM algorithm for linear mixed models. Australian & New Zealand Journal of Statistics. 2017. DOI 10.1111/anzs.12208.
- MATARAZZO, T. J.; PAKZAD, S. N. STRIDE for Structural Identification using Expectation Maximization: Iterative Output-Only Method for Modal Identification. Journal of Engineering Mechanics. 2016. Dostupné online.
- EINICKE, G.A.; MALOS, J.T.; REID, D.C. Riccati Equation and EM Algorithm Convergence for Inertial Navigation Alignment. IEEE Trans. Signal Process.. Lednu 2009. DOI 10.1109/TSP.2008.2007090. Bibcode 2009ITSP...57..370E.
- EINICKE, G.A.; FALCO, G.; MALOS, J.T. EM Algorithm State Matrix Estimation for Navigation. IEEE Signal Processing Letters. Květnu 2010. DOI 10.1109/LSP.2010.2043151. Bibcode 2010ISPL...17..437E.
- EINICKE, G.A.; FALCO, G.; DUNN, M.T. Iterative Smoother-Based Variance Estimation. IEEE Signal Processing Letters. Květnu 2012. DOI 10.1109/LSP.2012.2190278. Bibcode 2012ISPL...19..275E.
- EINICKE, G.A. Iterative Filtering and Smoothing of Measurements Possessing Poisson Noise. IEEE Transactions on Aerospace and Electronic Systems. Sep 2015. DOI 10.1109/TAES.2015.140843. Bibcode 2015ITAES..51.2205E.
- JAMSHIDIAN, Mortaza; JENNRICH, Robert I. Acceleration of the EM Algorithm by using Quasi-Newton Methods. Journal of Royal Statistical Society, Series B. 1997. DOI 10.1111/1467-9868.00083.
- LIU, C. Parameter expansion to accelerate EM: The PX-EM algorithm. Biometrika. 1998. DOI 10.1093/biomet/85.4.755.
- MENG, Xiao-Li; RUBIN, Donald B. Maximum likelihood estimation via the ECM algorithm: A general framework. Biometrika. 1993. DOI 10.1093/biomet/80.2.267.
- LIU, Chuanhai; RUBIN, Donald B. The ECME Algorithm: A Simple Extension of EM and ECM with Faster Monotone Convergence. Biometrika. 1994. DOI 10.2307/2337067. JSTOR 2337067.
- Accelerating Expectation-Maximization Algorithms with Frequent Updates. Proceedings of the IEEE International Conference on Cluster Computing. 2012. Dostupné online.
- LANGE, Kenneth. The MM Algorithm [online]. Dostupné online.
- HUNTER, DR; LANGE, K. A Tutorial on MM Algorithms [online]. 2004 [cit. 2019-12-10]. Dostupné v archivu pořízeném dne 2011-07-20.
- MATSUYAMA, Yasuo. The α-EM algorithm: Surrogate likelihood maximization using α-logarithmic information measures. IEEE Transactions on Information Theory. 2003. DOI 10.1109/TIT.2002.808105.
- MATSUYAMA, Yasuo. Hidden Markov model estimation based on alpha-EM algorithm: Discrete and continuous alpha-HMMs. International Joint Conference na Neural Networks. 2011.
- WOLYNETZ, M.S. Maximum likelihood estimation in a linear model from confined and censored normal data. Journal of Royal Statistical Society, Series C. 1979. DOI 10.2307/2346749. JSTOR 2346749.
- PEARSON, Karl. Contributions to the Mathematical Theory of Evolution. Philosophical Transactions of the Royal Society of London A. 1894. ISSN 0264-3820. DOI 10 vycházející z moment.1098/rsta.1894.0003. JSTOR 90667. Bibcode 1894RSPTA.185...71P.
- SHABAN, Amirreza; MEHRDAD, Farajtabar; BO, Xie; LE, Song; BYRON, Boots. Learning Latent Variable Models by Improving Spectral Solutions with Exterior Point Method. UAI. 2015. Dostupné v archivu pořízeném dne 2016-12-24.
- BALLE, BORJA QUATTONI, ARIADNA CARRERAS, XAVIER. Local Loss Optimization in Operator Models: A New Insight into Spectral Learning. [s.l.]: [s.n.], 2012-06-27. OCLC 815865081
Související články
- Kombinační rozdělení
- Složené rozdělení
- Odhad hustoty rozdělení
- Spektroskopie s úplnou absorpcí
- MM algoritmus
Literatura
- HOGG, Robert; MCKEAN, Joseph; CRAIG, Allen. Introduction to Mathematical Statistics. Upper Saddle River, NJ: Pearson Prentice Hall, 2005.
- DELLAERT, Frank. The Expectation Maximization Algorithm. [s.l.]: [s.n.], 2002. dává jednodušší vysvětlení EM algoritmu jako maximalizace se spodní mezí.
- BISHOP, Christopher M., 2006. Pattern Recognition and Machine Learning. [s.l.]: Springer. ISBN 978-0-387-31073-2.
- GUPTA, M. R.; CHEN, Y. Theory and Use of the EM Algorithm. Foundations and Trends in Signal Processing. 2010. DOI 10.1561/2000000034. Dobře napsaná krátká kniha o EM včetně podrobného odvození EM pro GMMs, skryté Markovovy modely a Dirichlet.
- BILMES, Jeff. A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models. [s.l.]: [s.n.], 1998. obsahuje zjednodušené odvození EM rovnice pro gaussovské Kombinace a gaussovské Kombinace skrytých Markovových Modelů.
- Einicke, G.A. Smoothing, Filtering and Prediction: Estimating the Past, Present and Future. Rijeka, Croatia: Intech, 2012. Dostupné online. ISBN 978-953-307-752-9. DOI 10.5772/2706.
- MCLACHLAN, Geoffrey J.; KRISHNAN, Thriyambakam. The EM Algorithm and Extensions. 2. vyd. Hoboken: Wiley, 2008. ISBN 978-0-471-20170-0.
Externí odkazy
- Různé 1D, 2D a 3D ukázky EM se smíšenými modely poskytnutý jako materiál pro SOCR Statistics Online Computational Resource činnosti a aplety. Tyto aplety a aktivity ukazují empirické vlastnosti EM algoritmu pro odhad parametrů při různých nastaveních.
- k-MLE: Rychlý algoritmus učení statistickým smíšeným modelům
- Hierarchie tříd v C++ (GPL) včetně gaussovských kombinací
- The on-line textbook: Information Theory, Inference, and Learning Algorithms Online učebnice: informační teorie, inferenční a učicí algoritmy, od Davida MacKaye obsahuje jednoduché příklady EM algoritmu jako například clustering pomocí měkkého k-means algoritmu a zdůrazňuje variační pohled na EM algoritmus, jak je popsané v kapitole 33.7 verze 7.2 (čtvrté vydání).
- Variační Algoritmy pro přibližné Bayesovské vyvozování, M. J. Beala obsahuje porovnání EM na variačních Bayesovských EM a odvození několika modelů včetně variačních Bayesovských skryté Markovovy modely (kapitoly).
- Expectation Maximization Algoritmus: Krátký tutorial, kompletní odvození EM algoritmu od Seana Bormana.
- EM Algoritmus, autor: Xiaojin Zhu.
- EM algoritmus a varianty: neformální tutoriál Alexise Roche. Podrobný a velmi jasný popis EM algoritmu a mnoha zajímavých variant.