K-means
k-means (anglicky „k průměrů“) je často používaný algoritmus nehierarchické shlukové analýzy. Předpokládá, že shlukované objekty lze chápat jako body v nějakém eukleidovském prostoru a že počet shluků k je předem dán (případně lze vyzkoušet různá k, pro každé spustit algoritmus znovu a výsledky porovnat). Shluky jsou definovány svými centroidy, což jsou body ve stejném prostoru jako shlukované objekty. Objekty se zařazují do toho shluku, jehož centroidu jsou nejblíže. Algoritmus postupuje iterativně tak, že se vyjde z nějakých (obvykle náhodně zvolených) centroidů, přiřadí do nich body, přepočítá centroidy tak, aby šlo o těžiště shluku bodů, pak opět přiřadí body k nově stanoveným centroidům a tak dál, až dokud se poloha centroidů neustálí.
Konvergence algoritmu je zaručena a v praxi bývá obvykle poměrně rychlá. Nemusí však najít globální optimum ve smyslu nejmenšího součtu čtverců vzdáleností od centroidů a navíc pro různé volby počátečních centroidů mohou vzniknout různá řešení.
Pojem k-means poprvé použil James MacQueen roku 1967[1] a myšlenka pochází od Huga Steinhause (1957).[2] Popsaný základní algoritmus navrhl Stuart Lloyd z Bell Labs roku 1957 (publikováno až 1982).[3] Roku 1965 E. W. Forgy uveřejnil stejnou metodu, proto se někdy nazývá Lloydův-Forgyho algoritmus.[4] Efektivnější verzi navrhli a ve Fortranu naprogramovali Hartigan a Wong (1975/1979).[5]
- Demonstrace algoritmu
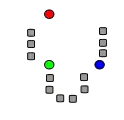 1. k výchozích centroidů (zde je k=3) se náhodně umístí v prostoru dat (shlukované objekty šedé, centroidy barevné)
1. k výchozích centroidů (zde je k=3) se náhodně umístí v prostoru dat (shlukované objekty šedé, centroidy barevné)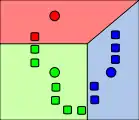 2. Objekty se přiradí nejbližším centroidům, čímž vznikne k shluků. Centroidy tak definují Voroného teselaci prostoru.
2. Objekty se přiradí nejbližším centroidům, čímž vznikne k shluků. Centroidy tak definují Voroného teselaci prostoru. 3. Přepočtou se centroidy shluků tak, aby šlo o těžiště objektů, jež patří do těchto shluků.
3. Přepočtou se centroidy shluků tak, aby šlo o těžiště objektů, jež patří do těchto shluků.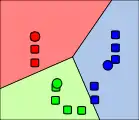 4. Kroky 2 a 3 se opakují, dokud nedojde k ustálení (konvergence).
4. Kroky 2 a 3 se opakují, dokud nedojde k ustálení (konvergence).
Reference
- MacQueen, J. B. (1967). "Some Methods for classification and Analysis of Multivariate Observations" in Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability. 1: 281–297, University of California Press. Retrieved on 2009-04-07.
- STEINHAUS, H. Sur la division des corps matériels en parties. Bull. Acad. Polon. Sci.. 1957, s. 801–804. (French)
- LLOYD, S. P. Least square quantization in PCM. Bell Telephone Laboratories Paper. 1957. (anglicky) Published in journal much later: LLOYD., S. P. Least squares quantization in PCM. IEEE Transactions on Information Theory. 1982, s. 129–137. Dostupné online [cit. 2009-04-15]. DOI 10.1109/TIT.1982.1056489. (anglicky)
- E.W. Forgy. Cluster analysis of multivariate data: efficiency versus interpretability of classifications. Biometrics. 1965, s. 768–769. JSTOR 2528559. (anglicky)
- J.A. Hartigan. Clustering algorithms. [s.l.]: John Wiley & Sons, Inc., 1975. (anglicky)