Překladač
Překladač (též kompilátor, anglicky translator nebo také compiler z to compile – sestavit, zpracovat) je v nejčastějším smyslu slova softwarový nástroj používaný programátory pro vývoj softwaru. Kompilátor slouží pro překlad algoritmů zapsaných ve vyšším programovacím jazyce do jazyka nižšího, nejčastěji strojového, či spíše do strojového kódu. Z širšího obecného hlediska je kompilátor stroj, respektive program, provádějící překlad z nějakého vstupního jazyka do jazyka výstupního. Z matematického hlediska je kompilátor funkce, která mapuje jeden nebo více zdrojových kódů podle překladových parametrů na kód ve výstupním jazyce.
Historie
Prvním programem, který by bylo možno označit jako překladač, byl A-0 System, který v roce 1952 vytvořila Grace Hopperová pro počítač UNIVAC I. Vývoj překladačů pak pokračoval prvním „kompletním“ překladačem pro jazyk Fortran v roce 1957, prvním tzv. self-hosting překladačem pro LISP v roce 1962, až po překladače psané ve vyšších programovacích jazycích po roce 1970.
Vztah jazyk – program – překladač
Číslicový počítač je z technického hlediska stroj, interpretující strojový kód uložený v paměti. Strojový kód tvořící počítačový program si u běžných číslicových počítačů založených na binární logice můžeme představit jako dlouhou posloupnost nul a jedniček. V pionýrských dobách výpočetní techniky bylo třeba nejprve vytvořit algoritmus, poté jej přepsat do symbolicky zapsaného strojového kódu a tento ručně přepsat do strojového kódu. Tato činnost je časově velmi náročná, přičemž v každé fázi tohoto procesu lze udělat mnoho chyb. Prvním zjednodušením byl assembler, který umožňoval převod symbolicky zapsaného strojového kódu do jeho číselného vyjádření. Assembler (ve smyslu překladač assembleru) nebývá řazen mezi kompilátory, přestože by z formálního hlediska mohl být za kompilátor považován. Funkce assembleru je ve srovnání s kompilátorem velmi jednoduchá, zdrojový kód assembleru se považuje pouze za čitelnější formu zápisu strojového kódu, kde jsou adresy proměnných a návěstí označeny symbolickými názvy.
Algoritmy byly v počátcích výpočetní techniky zapisovány formou vývojových diagramů. Vývojové diagramy jsou vhodné pro formální popis algoritmů, avšak jejich tvorba je zdlouhavá a jejich počítačové zpracování je obtížné. Naproti tomu vyšší programovací jazyky umožňují efektivní a jednoznačně definovaný zápis algoritmů. Klasický postup, kdy je algoritmus nejprve zapsán v programovacím jazyce a poté přeložen pomocí kompilátoru do strojového kódu se z velké části používá dodnes, protože takto vytvořené programy využívají velice efektivně strojový čas počítače. Typickým příkladem kompilovaného jazyka je programovací jazyk C.
Když strojový čas počítačů zlevnil (a čas programátorů relativně podražil), začaly se objevovat jazyky, které nejsou zaměřené na vytvoření maximálně efektivního kódu, ale které si kladou za primární cíl přehlednější a pohodlnější zápis algoritmů a zmenšení problémů při přenosu programů mezi různými architekturami počítačů. Díky tomu vznikly interpretované jazyky, které nejsou (a bez zásahu do struktury jazyka nemohou být) kompilovány. Zdrojový kód není překládán přímo do strojového kódu, ale je přímo interpretován pomocí speciálního programu – interpretu. Typickým příkladem interpretovaného jazyka může být např. Smalltalk.
Fáze překladu programu
I když by bylo možné, aby kompilátor překládal zdrojový kód přímo do spustitelného tvaru, obvyklý postup překladu bývá odlišný. Zdrojový kód programu bývá obvykle rozdělen do více jednotek, u velkých programů se může jednat o tisíce souborů se zdrojovými texty. Důvodů pro takovou fragmentaci zdrojového kódu programu je mnoho, např. snadnější údržba zdrojových kódů, možnost znovu-využívání jednotek, nižší nároky na kompilátor atp.
Proto kompilátor překládá jednotky zdrojového kódu do tzv. objektového kódu. Objektový kód jednotky je v podstatě již strojovým kódem cílové architektury, obsahuje však dodatečné informace umožňující přemístění návěstí a proměnných přeložené jednotky a informace o vazbách na externí proměnné a na externí kód. Z jednotlivě přeložených objektových kódů a z funkcí obsažených v knihovnách pak linker sestaví výsledný spustitelný kód.
Příklad možného postupu překladu programu psaného v jazyce C:
| Zdrojový kód → cílový kód | Překladový nástroj | Poznámka |
|---|---|---|
| jednotka1.c → jednotka1.asm, jednotka2.c → jednotka2.asm, … |
kompilátor jazyka C | klasické kompilátory překládaly zdrojový kód do jazyka symbolických adres; mnohé kompilátory tuto možnost nabízejí i dnes pro případ, že vyvstane potřeba zkontrolovat funkci kompilátoru |
| jednotka1.asm → jednotka1.obj, jednotka2.asm → jednotka2.obj, … |
assembler | vytvoření objektového kódu |
| jednotka1.obj + jednotka2.obj + … + knihovna1.lib + knihovna2.lib + … → output | linker | spojení objektových kódů a kódu z knihoven do spustitelného kódu |
Překladové nástroje zpravidla na požádání generují dodatečné informace (například mapy proměnných, kód s rozvojem maker, informace o vyhodnocení konstant atp.). Tyto informace mohou sloužit pro kontrolu průběhu překladu, nebo jako vstupy pro ladící nástroje.
Struktura překladače
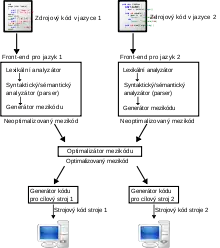
Překladač lze navrhnout mnoha způsoby, často bývá rozdělen na dvě části. První je závislá na vstupním jazyce (tzv. front-end) a druhá závisí na cílové architektuře (tzv. back-end). Překlad nemusí probíhat přímo, může využívat tzv. mezikód (bytekód, resp. mezilehlý kód), tzn. že kód je nejprve překládán do mezikódu a v druhém kroku z mezikódu do strojového jazyka. Tím se rozdělí jeden kompilátor na dva jednodušší kompilátory, přičemž překlad ze zdrojového jazyka do mezikódu může být společný pro více architektur. Rovněž je výhodné, že pokud je potřeba vyrobit překladač pro další jazyk, stačí vytvořit pouze část pro překlad do mezikódu.
O překladači se mluví i v případě, že překládá do vyššího programovacího jazyka. Tímto způsobem se používá C jako tzv. přenositelný assembler, dále běžně na jedné straně assembler a extrémisté na druhé straně Scheme. Z pohledu uživatele tyto fáze nemusí být odděleny a všecko je na jeden knoflík, odborně tlačítko. Uživatel vidí přítulné GUI.
Překlad z mezikódu, např. v integrovaném prostředí, může být odložen, z různých důvodů, a vykonáván dále po částech podle potřeby. Pro to se používá termín JIT, just-in-time kompilace. Důvody jsou… Tento přístup se od interpretace liší v tom, že se do mezikódu zpracuje celý zdroják, tudíž kompilační chyby jsou nalezeny a opraveny před spuštěním. Mezikód může být i interpretován, např. abstraktním neboli virtuálním strojem.
Vlastní běh překladače označujeme jako čas překladu (compile time); spuštění přeloženého programu pak jako čas běhu (run time). Jednoslovným termínem runtime se označují části kódu, které se připojují (přilinkují) k přeloženému kódu a obsahují podpůrné funkce, jako implementaci vestavěných operací, V/V, …
Překladač může dostat kromě zdrojáku i příkazy pro svou činnost prostřednictvím options, například o požadované míře optimalizace nebo o povolených rozšířeních syntaxe, použitých v konkrétním zdrojáku. Taktéž zdroják může obsahovat příkazy nebo informace pro kompilátor, známé jako pragmy. A výstupem nemusí být jen strojový kód, ale i dodatečné informace pro debugger apod.
Části překladače
Z formálního hlediska je možné rozdělit překladač na následující části, ve skutečnosti však nemusí být tyto jednotky vždy striktně oddělené (např. lexikální a syntaktická analýza může splynout):
- lexikální analyzátor
- syntaktická analýza
- sémantický analyzátor
- optimalizace kódu
- generování cílového kódu
Lexikální analyzátor
Lexikální analyzátor je první jednotka překladače, která má za úkol relativně jednoduchým způsobem získat ze vstupního zdrojového textu tzv. lexémy (některý základní prvek příslušného jazyka, např. klíčové slovo „if“) a tu pak zasílá syntaktickému analyzátoru.
Všechny možné lexémy jsou ve vstupním jazyce popsány pomocí regulárních výrazů. V kompilátoru se pro jejich rozpoznávání používá konečný automat. Kromě samotného lexému se do syntaktického analyzátoru posílají další související údaje, např. jakého druhu je daný lexém (operátor, klíčové slovo, identifikátor, …), u identifikátorů odkaz do tabulky identifikátorů (pro urychlení překladu, překladač poté nemusí pracovat s textem, ale pouze s číselným označením) apod. Celý soubor údajů předávaný z lexikálního do syntaktického analyzátoru se označuje anglickým termínem token (známka, odznak).
Syntaktický analyzátor
Syntaktický analyzátor (v angličtině označovaný jako parser, z to parse – rozebrat, oddělovat, udělat větný rozbor) se dá považovat za mozek překladače, protože provádí samotnou analýzu vstupního jazyka. Úkolem syntaktického analyzátoru je rozpoznat, zda je program zapsán správným způsobem, např. zda na úvodní „begin“ bude navazovat někde koncové „end“, ale také určuje, v jakém pořadí se budou provádět jednotlivé části příkazů, např. u „x + y*z“ rozpozná a určí, že nejdříve se bude násobit a pak až sčítat, nebo u vnořených příkazů zajistí, že nejdříve se vyhodnotí parametr funkce a teprve pak se daná funkce zavolá.
Úloha syntaktického analyzátoru je o něco složitější než úloha lexikálního analyzátoru, neboť na rozdíl od regulárního jazyka lexémů musí syntaktický analyzátor rozpoznávat složitější bezkontextový jazyk (typicky LL(1) či LR(1)). Syntaktický analyzátor k tomu musí vyhodnocovat vstup v delším záběru.
Výsledkem práce syntaktického analyzátoru je tzv. syntaktický strom (anglicky „parse tree“), který popisuje strukturu vstupního programu.
Jedním z nejjednodušších způsobů konstrukce syntaktického analyzátoru je tzv. metoda rekurzivního sestupu. V této metodě se pomocí rekurzivních volání konstruuje syntaktický strom, přičemž struktura implementace překladače odráží strukturu příslušné gramatiky. Pokud je v gramatice na daném místě neterminální symbol, v překladači mu odpovídá (rekurzivní) volání funkce reprezentující příslušný neterminál. Tato rekurzivní volání končí u terminálních symbolů (lexémů jazyka), které jsou přečteny a uloženy do syntaktického stromu. K syntaktické analýze se využívá zásobníkového automatu.
Sémantický analyzátor
Sémantický analyzátor zpracovává syntaktický strom a provádí analýzu významu jednotlivých operací. Na rozdíl od syntaktického analyzátoru, který provádí kontrolu správnosti struktury programu čili zápis programového kódu, sémantický analyzátor provádí kontrolu správnosti operací. V tomto mechanismu se odehrává veškerá typová kontrola a různé konverze. Prací sémantického analyzátoru je např. analýza typů výrazů na levé a pravé straně přiřazovacího příkazu, přičemž musí zabránit např. přiřazení hodnoty s plovoucí řádovou čárkou do proměnné s pevnou řádovou čárkou.
Vstupem sémantického analyzátoru je syntaktický strom, který vygeneroval syntaktický analyzátor, výstupem je opět syntaktický strom, ale s doplněnými dodatečnými informacemi a s provedenými konverzemi.
Překladač do mezikódu
V této fázi se ze syntaktického stromu generuje kód, tzn. strukturovaný syntaktický strom se transformuje do lineární posloupnosti instrukcí. Obvykle se však negeneruje přímo kód cílového jazyka, ale kód v nějakém pomocném jazyce, tzv. mezikód. Cílem tohoto kroku je ulehčit následující operace, které by v cílovém jazyce mohly být komplikované. Tohoto přístupu se s výhodou používá pro tvorbu optimalizátorů efektivity kódu. Existují však i překladače bez fáze překladu do mezikódu, překládající přímo do cílového jazyka.
Jednou z možností návrhu mezikódu je tzv. tříadresný kód. Instrukce tříadresného kódu mají jednotnou strukturu, pracují nad adresami dvou vstupních operandů a jednoho výsledkového operandu, např. Id1 = Id2 * 5. Nejtypičtější formou mezikódu však je kód nějakého zásobníkového počítače.
Překladem do mezikódu končí část závislá na zdrojovém programovacím jazyku (front-end), zbytek překladače (back-end) může být dokonce shodný pro překladače různých jazyků (tak je navržen např. překladač GCC).
Jako mezikód se používá i jazyk symbolických adres, někdy též nepřesně nazývaný assembler (ovšem s omezením na cílovou architekturu).
Optimalizátor
Optimalizátor provádí optimalizace pomocí různých transformací mezikódu, jejichž cílem je zlepšení vlastností výsledného kódu (zrychlení běhu, zmenšení velikosti kódu a podobně).
Příkladem optimalizace může být například odstranění cyklického přiřazení:
Id1 = 5 + Id2 Id3 = Id1
takovýto kód optimalizátor přepíše na:
Id3 = 5 + Id2
Také se může vyskytovat tzv. mrtvý kód, tedy kód, který se nikdy nevykoná, například:
while (false) {
…
}
takový kód optimalizátor zcela zahodí. Na výstupu optimalizátoru je stále mezikód.
Generátor kódu
V poslední fázi se z mezikódu generuje výstupní kód, program v cílovém jazyce. Cílovým jazykem nejčastěji bývá přímo strojový kód, často též bajtkód a v poslední době též rozšíření JavaScriptu asm.js (prohlížeče Mozilla Firefox, Google Chrome, Opera[1] a Safari[2]).
Typy překladačů
Překladače můžeme rozdělit na:
- klasický překladač
- konverzační překladač, který se dále dělí na:
- konverzační interpretační překladač
- konverzační kompilační překladač
Klasický překladač
Klasický překladač je nejběžnějším typem překladače. Programátor sestaví celý program ve zdrojovém tvaru, což bývá text či struktura, a pak jej pošle na vstup překladače. Během překladu obvykle není možné zasahovat do činnosti překladače. Překlad probíhá v jednom nebo několika průchodech (viz níže). Postupně probíhá lexikální, syntaktická a sémantická analýza, optimalizace (obvykle ve více průchodech) a generování cílového kódu (podrobněji viz výše).
Konverzační překladač
Konverzační (interaktivní) překladač s uživatelem během překladu komunikuje. Uživatel postupně zapisuje řádky zdrojového kódu, které jsou ihned po dokončení jednotlivě posílány konverzačnímu překladači. Konverzační překladač obvykle obsahuje příkazy metajazyka, které jsou určeny jen překladači (výpis proměnné, ovlivnění chodu překladače, ukončení práce). Konverzační překladače s uživatelským rozhraním mohou mít vlastní menu s metapříkazy, což zjednodušuje analýzu vstupu, protože se překladač nemusí zabývat rozlišením vstupního jazyka a metajazyka. Výhodou tohoto překladače je rozšíření možností ladění. Další výhodou je, že pokud nastane chyba, je to zpravidla u posledního vstupu, což je zpravidla jen jeden řádek.
Konverzační interpretační překladač
Konverzační interpretační překladač postupně přijímá určité příkazy, kontroluje jejich správnost, ukládá a příkaz interpretuje. Je vhodný pro implementaci jednoduchých grafických programů či výukových programů (Logo, Karel).
Konverzační kompilační překladač
Konverzační kompilační překladač postupně načítá určité příkazy, ukládá si je ve zdrojovém kódu, a pak je zpracovává. Tento překladač postupně generuje cílový kód nebo intermediální kód (asi častěji nazývaný bajtkód). Velkou nevýhodou je, že je přístupný pouze příkaz, který se zrovna zpracovává, což způsobuje komplikace při zpracovávání kontextových závislostí. Proto se dá použít jen pro nejjednodušší jazyky.
Průchody překladače
Průchodem překladače se rozumí kompletní načtení celého zdrojového kódu. Průchodem vzniká mezikód pro vnitřní potřebu překladače. Mezikód je vstupem další části nebo dalšího průchodu překladače. Podle počtu průchodů dělíme překladače na:
- jednoprůchodové – jsou jednodušší v oblasti překladače a jazyka; mají nižší režii, protože nevzniká mezikód (spochybněno. Hm, to bude složitejší)
- víceprůchodové – jsou složitější, ale je jednodušší vznik a údržba překladače, jelikož se skládá ze samostatných částí, které spolu nemusí souviset; požaduje nižší nároky na hardware při překladu, protože části překladače zodpovědné za jednotlivé průchody mohou být menší a zpracování může proběhnout postupně
Dneska je relativně dost operační paměti, málokdo píše gigabajtové nebo terabajtové zdrojáky (nebo si je nechá generovat), disky mají taky pohyblivé hlavičky a tudíž dokážou číst kde-co, fai(j)lové systémy se jim přizpůsobily a čtou náhodně, občas i bez chyb, málokdo používá klasickou (sekvenční) děrnou pásku nebo (taky sekvenční) magnetickou pásku, proto počítání průchodu a dělení na jednoprůchodové s jejich virtuálními výhodami je mimo mísu. A to jsem vynechal skriptovací jazyky a děrné štítky.
Některé části překladače, např. statická analýza a s ní související optimalizace, fungují dobře až nejlépe, pokud mají v nějaké formě k dispozici celý program.
Příklad překladače
Následující program implementuje jednoduchý jednoprůchodový překladač napsaný v jazyce C. Tento překladač kompiluje výrazy definované v infixovém zápisu do postfixové notace (reverzní polská notace, zkráceně RNP) a taktéž do jazyka symbolických adres. Tento překladač používá pro vyhodnocování výrazů rekurzivní volání funkcí.
# include <stdlib.h>
# include <stdio.h>
# include <string.h>
# define MODE_POSTFIX 0
# define MODE_ASSEMBLY 1
char lookahead;
int pos;
int compile_mode;
char expression[20+1];
void error() {
printf("Syntax error!\n");
}
void match( char t ) {
if( lookahead == t ) {
pos++;
lookahead = expression[pos];
}
else
error();
}
void digit() {
switch( lookahead ) {
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
if( compile_mode == MODE_POSTFIX )
printf("%c", lookahead);
else
printf("\tPUSH %c\n", lookahead);
match( lookahead );
break;
default:
error();
break;
}
}
void term() {
digit();
while(1) {
switch( lookahead ) {
case '*':
match('*');
digit();
printf( "%s", compile_mode == MODE_POSTFIX ? "*"
: "\tPOP B\n\tPOP A\n\tMUL A, B\n\tPUSH A\n");
break;
case '/':
match('/');
digit();
printf( "%s", compile_mode == MODE_POSTFIX ? "/"
: "\tPOP B\n\tPOP A\n\tDIV A, B\n\tPUSH A\n");
break;
default:
return;
}
}
}
void expr() {
term();
while(1) {
switch( lookahead ) {
case '+':
match('+');
term();
printf( "%s", compile_mode == MODE_POSTFIX ? "+"
: "\tPOP B\n\tPOP A\n\tADD A, B\n\tPUSH A\n");
break;
case '-':
match('-');
term();
printf( "%s", compile_mode == MODE_POSTFIX ? "-"
: "\tPOP B\n\tPOP A\n\tSUB A, B\n\tPUSH A\n");
break;
default:
return;
}
}
}
int main ( int argc, char** argv )
{
printf("Please enter an infix-notated expression with single digits:\n\n\t");
scanf("%20s", expression);
printf("\nCompiling to postfix-notated expression:\n\n\t");
compile_mode = MODE_POSTFIX;
pos = 0;
lookahead = *expression;
expr();
printf("\n\nCompiling to assembly-notated machine code:\n\n");
compile_mode = MODE_ASSEMBLY;
pos = 0;
lookahead = *expression;
expr();
return 0;
}
Nejznámější překladače
- GCC (GNU Compiler Collection)
- Clang
- Intel C++ Compiler (ICC)
- Microsoft Visual Studio (přesněji v něm obsažené překladače C++, C♯, Visual Basic atd.)
- Glasgow Haskell Compiler (GHC)
- Turbo Pascal, následně Delphi
- Borland C++, následně C++Builder
- Free Pascal
- Watcom C/C++
Odkazy
Reference
V tomto článku byly použity překlady textů z článků Compiler na německé Wikipedii a Kompilator na polské Wikipedii.
- http://www.favbrowser.com/chrome-and-opera-optimize-for-asm-js/ Chrome And Opera Optimize For Asm.js
- http://www.macrumors.com/2014/05/12/safari-javascript-ftljit/ Apple Looking to Boost Safari JavaScript Performance with New Accelerator Upgrades
Související články
Externí odkazy
 Obrázky, zvuky či videa k tématu překladač na Wikimedia Commons
Obrázky, zvuky či videa k tématu překladač na Wikimedia Commons  Slovníkové heslo překladač ve Wikislovníku
Slovníkové heslo překladač ve Wikislovníku- Formální jazyky a překladače – materiály z cvičení Katedry informatiky a výpočetní techniky Fakulty aplikovaných věd Západočeské univerzity v Plzni
- Jazyky a překladače (seriál na ABCLinuxu)