Syntaktická analýza
Syntaktická analýza (slangově podle angličtiny též parsování nebo parsing) se v informatice a v lingvistice nazývá proces analýzy posloupnosti formálních prvků s cílem určit jejich gramatickou strukturu vůči předem dané (byť ne nutně explicitně vyjádřené) formální gramatice.
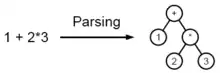
Program, který vykonává tuto úlohu, se nazývá syntaktický analyzátor (slangově parser).
Při syntaktické analýze se vstupní text zpravidla transformuje na určité datové struktury, většinou syntaktický strom nebo méně abstraktní derivační strom, které zachovávají hierarchické uspořádání vstupních symbolů a jsou vhodné pro další zpracování.
Syntaktické analýze zpravidla předchází lexikální analýza, při níž se vstupní text rozděluje na posloupnost lexikálních symbolů neboli tokenů – elementárních nositelů významu v rámci daného formálního jazyka. Při analýze textu v přirozeném jazyce jsou symboly obvykle slovní tvary a interpunkce, v programovacím jazyce identifikátory, literály (čísla, textové řetězce – také jen řetězce), klíčová slova, operátory, oddělovače apod. Pro parser to jsou dále nedělitelné stavební jednotky, které používá při interpretaci vstupních dat.
Existují programy, schopné ze specifikace programovacího jazyka (zapsané např. v Backus–Naurově notaci) vytvořit parser. Mezi nejznámější takovéto generátory parserů patří program Yacc (yet another compiler compiler).
Lidské jazyky
Při některých metodách počítačového zpracování lidského jazyka se používá počítačových programů, které dokáží lidský jazyk syntakticky analyzovat. Tento úkol je dosti ztížen skutečností, že stavba lidského jazyka je zpravidla velmi nejednoznačná.
Pro syntaktickou analýzu lidského jazyka musí být nejprve stanovena příslušná formální gramatika. Volba její syntaxe závisí na záměrech jednak lingvistických, jednak implementačních. Některé analytické systémy například používají lexikálně-funkčních gramatik, ovšem v takovém případě je syntaktická analýza z hlediska složitosti NP-úplným problémem. Další pro syntaktickou analýzu často užívanou lingvistickou formalizací je HPSG gramatika, avšak některé projekty využívají i mnohem jednodušších formalizací (viz např. korpus syntaktických stromů Penn Treebank). Povrchová syntaktická analýza se zaměřuje jen na rozčlenění vstupního textu na hlavní součásti jako jmenné fráze. Jinou často využívanou možností, jak se vyhnout jazykové víceznačnosti, je syntaktická analýza podle dependenční gramatiky.
Moderní syntaktické analyzátory bývají alespoň částečně statistické, tedy opírají se o korpus dat, která byla analyzována ručně. Pomocí takového korpusu může program získat informace o frekvenci výskytu různých gramatických konstrukcí ve specifických kontextech (viz též strojové učení). Používané metody zahrnují pravděpodobnostní bezkontextové gramatiky, metodu maximální entropie a neuronové sítě. Většina úspěšnějších systémů užívá metody lexikální statistiky, tj. posuzuje slova v mj. závislosti na jejich slovním druhu. Takové systémy však mohou podléhat tzv. přeučení (overfitting) a pro dosažení efektivity vyžadují pečlivé doladění.
Algoritmy pro syntaktickou analýzu přirozených jazyků musí zacházet s gramatikami mnohem složitějšími a nepřehlednějšími, než jsou „hezké“ gramatiky umělých programovacích jazyků. Jak již bylo řečeno, některé gramatické struktury jsou pro analýzu výpočetně velmi složité. Obecně se i v případě gramatických struktur, které se nedají vyjádřit bezkontextově, užívá zjednodušených bezkontextových gramatik, pomocí nichž se provádí první krok analýzy. Algoritmy, které využívají bezkontextových gramatik, často spočívají na některé variantě algoritmu CYK, zpravidla doplněného heuristikou, která umožňuje vyřadit nepravděpodobné možnosti a tak ušetřit čas (viz též tabulková analýza). Některé systémy se snaží snížit výpočtovou složitost na úkor přesnosti užitím algoritmů LR analýzy pracujících v lineárním čase. Relativně novou metodou pak je parse reranking, při kterém syntaktický analyzátor navrhne vícero možných analýz, a složitější systém pak vybere, která z nich je nejvhodnější.
Programovací jazyky
Syntaktická analýza je důležitou částí zpracování programů při jejich překladu (kompilaci) nebo interpretaci. Zatímco interpret provádí výpočet (interpretaci) nad datovými strukturami vytvořenými analýzou programu napsaném v určitém programovacím jazyce, kompilátor z těchto datových struktur generuje program v cílovém jazyce, který lze (po dalších úpravách) interpretovat hardwarovým nebo virtuálním procesorem.
Programovací jazyky bývají specifikovány deterministickými bezkontextovými gramatikami, pro které lze vytvořit rychlý a efektivní syntaktický analyzátor. Ten však obvykle nebývá programován ručně, nýbrž generován zvláštním programem, tzv. parser generátorem, na základě předepsané gramatiky.
Bezkontextové gramatiky zpravidla nejsou schopny vyjádřit vše, co jazyk vyžaduje. Zjednodušeně se dá říci, že bezkontextově vyjádřený jazyk má omezenou paměť. Bezkontextová gramatika nemá prostředky k zapamatování předchozího výskytu konstruktu, pokud může být oddělen libovolně dlouhým jiným textem – nedokáže tedy třeba rozpoznat, zda byl identifikátor před použitím deklarován. Mocnější gramatiky, které toto dokáží, zase nemohou být efektivně syntakticky analyzovány. Proto se obvykle používá bezkontextový parser, který rozpoznává nadmnožinu požadovaných jazykových konstruktů (tj. přijal by i některé neplatné), v kombinaci s dalšími nástroji, obvykle tabulkou symbolů.
Proces analýzy
Následující příklad demonstruje obvyklý postup analýzy programovacího jazyka se dvěma úrovněmi gramatiky: lexikální a syntaktickou.
První fází je lexikální analýza, při níž se vstupní text, na který lze pohlížet jako na proud znaků, členěn na symboly (tokeny), zpravidla definované gramatikou regulárních výrazů. Například kalkulátor, který má zpracovávat vstup tvaru 127 * (3+45)^2, jej rozloží na symboly 127, *, (, 3, +, 45, ), ^ a 2, z nichž každý je smysluplným symbolem v aritmetickém výrazu. Scanner obsahuje pravidla, která určují, že znaky *, +, ^, ( a ) označují začátek nového symbolu, takže nebudou uvažované nesmyslné symboly jako 12* nebo (3.
Další fází je syntaktická analýza (parsing), při které se kontroluje, zda posloupnost symbolů tvoří povolený výraz. Na této úrovni je jazyk obvykle popsán bezkontextovou gramatikou, která rekurzivně definuje komponenty, z nichž lze složit výraz, a pořadí, ve kterém se musí objevit. Některá pravidla definující programovací jazyky nemohou být vyjádřena bezkontextovou gramatikou – problémy činí například typová kontrola a deklarace identifikátorů. Tato pravidla mohou být formálně vyjádřena pomocí atributové gramatiky a jejich dodržování se prakticky kontroluje pomocí tabulky symbolů.
Poslední fází je sémantická analýza, která zjišťuje význam jednotlivých částí datové struktury a přiřazuje jim příslušné akce. V případě kalkulátoru mohou být těmito akcemi např. ukládání konstant na zásobník nebo provedení určité aritmetické operace; v případě překladače je akcí generování fragmentů kódu. Pro definování těchto činností lze použít překladovou gramatiku.
Typy syntaktické analýzy
Prakticky rozlišujeme syntaktickou analýzu přirozeného jazyka a počítačových jazyků. Dost podstatné rozlišení je, že přirozené jazyky se popisují obecnými, tj. nedeterministickými bezkontextovými gramatikami, kdežto počítačové jazyky jsou úmyslně navrženy a popsány jednoduššími deterministickými bezkontextovými gramatikami. Z toho plyne, že pro přirozené jazyky se používají nedeterministické analyzátory, které můžou vydat víc různých analýz jednoho slova/věty/vstupu. Samozřejmě jsou implementovány deterministicky, příklad je výše zmíněný CYK. Další část popisuje přístupy používané pro analýzu deterministických bezkontextových jazyků.
Úkolem syntaktického analyzátoru je zjistit, zda a jak je možno vstupní text vygenerovat z počátečního symbolu gramatiky. Tohoto úkolu se analyzátor může zhostit jednou ze dvou základních metod:
- Syntaktická analýza shora dolů – Parser začíná počátečním symbolem a snaží se převést jej na vstup. Schematicky řečeno začíná největšími prvky, které postupně rozbíjí na menší části, dokud se nedostane k terminálním symbolům, které může porovnat se vstupem. Příkladem syntaktické analýzy shora dolů je LL analýza.
- Syntaktická analýza zdola nahoru – Parser začíná vstupním textem a snaží se jej převést na počáteční symbol. Prakticky tedy hledá nejprve pravidla, která obsahují dané terminální symboly, pak pravidla, která mohou takovým pravidlům předcházet atd. Příkladem syntaktické analýzy zdola nahoru je LR analýza. Jiný termín pro tento druh syntaktické analýzy je shift-reduce parsing (doslova „posuň-zmenši“, česky označováno jako „přesun-redukce“).
Další význačné rozlišení je mezi analýzou zleva doprava a analýzou zprava doleva, tedy mezi tím, zda analyzátor – jako například při LL analýze – generuje levou derivaci vstupního textu, nebo – jako například při LR analýze – pravou derivaci (viz článek bezkontextová gramatika).
Další ještě význačnější rozlišení je mezi deterministickou analýzou a nedeterministickou analýzou.
Literatura
- Molnár, Ľudovít – Češka, Milan – Melichar, Bořivoj: Gramatiky a jazyky. Bratislava : Alfa, 1987.
Související články
Externí odkazy
- Parsing Techniques – A Practical Guide[nedostupný zdroj] – kniha podle Dick Grune a Ceriel J.H. Jacobs, 2. vydání, dostupná online v nakladatelství Springer
- Parsing Techniques – A Practical Guide – 1. vydání ke stažení v pdf a ps