Binární vyhledávací strom
Binární vyhledávací strom (BST – z angl. Binary Search Tree) je datová struktura založená na binárním stromu, v němž jsou jednotlivé prvky (uzly) uspořádány tak, aby v tomto stromu bylo možné rychle vyhledávat danou hodnotu. To zajišťují tyto vlastnosti:
- Jedná se o binární strom, každý uzel tedy má nanejvýš dva potomky – levého a pravého.
- Každému uzlu je přiřazen určitý klíč. Podle hodnot těchto klíčů jsou uzly uspořádány.
- Levý podstrom uzlu obsahuje pouze klíče menší než je klíč tohoto uzlu.
- Pravý podstrom uzlu obsahuje pouze klíče větší než je klíč tohoto uzlu.

Hlavní výhodou binárních vyhledávacích stromů je vysoká efektivita vyhledávání hodnot v nich, byť proti hašovací tabulce je pomalejší. Lze je využít při dobré implementaci také k efektivnímu řazení hodnot – in-order průchod binárním vyhledávacím stromem vydá seznam uložených hodnot uspořádaný podle velikosti. Ale důležitější jsou na tom postavené intervalové dotazy a průběžné udržování uspořádaných klíčů, protože řadit na místě, tj. efektivněji, umí spousta jiných algoritmů.
Binární vyhledávací stromy jsou zásadní datovou strukturou při konstrukci daleko abstraktnějších datových struktur jako jsou množiny, multimnožiny a asociativní pole.
Pokud BST neumožňuje duplicity hodnot, pak se jedná o strom s unikátními hodnotami, stejně jako matematická množina. Stromy bez duplicit využívají ostrou nerovnost, tedy hodnoty uzlů levého podstromu jsou menší než je hodnota uzlu a pravý podstrom obsahuje pouze hodnoty větší než je hodnota uzlu.
Pokud BST umožňuje duplicity hodnot, pak představuje multimnožinu. Tento typ stromu využívá neostrou nerovnost. Všechny hodnoty uzlů v levém podstromu uzlu jsou menší než je hodnota uzlu, ale všechny hodnoty v pravém podstromu jsou buď větší, nebo shodné s hodnotou uzlu.
Uložení duplicitních hodnot právě v pravém podstromu není povinné. Stejně tak je lze uchovávat i v levém podstromu. Lze též užít neostrou nerovnost v obou podstromech, což usnadní vyvážení stromu obsahujícího mnoho duplicit, ale utrpí efektivita vyhledávání.
Strom se mnohem častěji než na množiny a multimnožiny používá pro asociativní paměť (nepřesně asociativní pole), kde se podle klíče hledá přidružená hodnota. Vyhledávací stromy (včetně nebinárních) mají mnoho implementačních variant (majících vlastní jména a články) případně i s lepšími vlastnostmi. Na druhé straně pro asociativní pole se dají použít i jiné konkrétní datové struktury.
BST Vyhledávací stromy slouží jako ideový základ pro konstrukci složitějších vyhledávacích datových struktur, konkrétně pro složené klíče a dotazy s částečně zadanými klíči.
Složitost operací je, zjednodušeně řečeno, při dobré implementaci logaritmická a obecně lineární vzhledem k počtu reprezentovaných prvků.
Operace
Všechny operace na binárním stromě opakovaně porovnávají hodnoty klíčů. Může se jednat o triviální porovnání dvou čísel či řetězců, ale také o složitější podprogram, pokud úlohu klíče hraje kombinace několika datových položek uzlu. Kromě klíče uzel zpravidla nese další datové položky, které tvoří vlastní obsah datové struktury. Ty však při operacích hrají pouze pasivní úlohu.
BST podporuje intervalové dotazy a sekvenční procházení.
Vyhledávání ve stromu
Vyhledání konkrétní hodnoty v binárním vyhledávacím stromu typicky probíhá rekurzivně. Začíná zpravidla v kořeni. V každém kroku porovná hledanou hodnotu s klíčem zkoumaného uzlu. Pokud jsou si rovny, hodnota byla nalezena. Je-li hledaná hodnota menší, pokračuje hledání v levém podstromu. Je-li větší, bude hledání pokračovat v pravém podstromu. Díky uspořádání stromu je cesta k hledané hodnotě jednoznačně určena.
Může dojít k situaci, kdy vyhledávací algoritmus narazí na neexistující uzel (dotyčný podstrom je prázdný). V takovém případě strom hledanou hodnotu neobsahuje, jinde být nemůže.
Zde je vyhledávací algoritmus v programovacím jazyce Python:
def search_binary_tree(node, key):
if node is None:
return None # klíč nebyl nalezen
elif key < node.key:
return search_binary_tree(node.left, key)
elif key > node.key:
return search_binary_tree(node.right, key)
else: # klíč je ekvivalentní s klíčem uzlu
return node.value # klíč nalezen
Časová složitost vyhledávání závisí na hloubce stromu. V průměrném případě má logaritmickou časovou složitost O(log n), ale pokud je strom nevyvážený a podobá se seznamu, může mít i lineární časovou složitost O(n). Otázka správného vyvážení je z tohoto pohledu kritická a řeší ji například AVL-strom.
Přidání nového uzlu
Vložení nového uzlu začíná hledáním jeho pozice ve stromu – postupuje se stejně jako při vyhledávání, jako hledaná hodnota se použije klíč vkládaného uzlu. Tato fáze může vést ke dvěma různým výsledkům:
- klíč byl nalezen, strom tedy dotyčnou hodnotu již obsahuje a není třeba ji vkládat (komplikovanější varianty připouštějící vícenásobný výskyt stejného klíče by pokračovaly dál do podstromu připouštějícího rovnost)
- algoritmus narazil na neexistující uzel, nový uzel bude vložen na toto místo, protože sem podle hodnoty svého klíče patří
Zde je typický příklad vkládání do binárního vyhledávacího stromu v jazyce C++:
/* Vkládá se uzel určený ukazatelem "newNode" do podstromu začínajícího uzlem "treeNode" */
void InsertNode(struct node* &treeNode, struct node *newNode)
{
if (treeNode == NULL)
treeNode = newNode;
else if (newNode->value < treeNode->value)
InsertNode(treeNode->left, newNode);
else if (newNode->value > treeNode->value)
InsertNode(treeNode->right, newNode);
}
Popsaná „destruktivní“ verze mění strom na místě. Paměťová náročnost je sice konstantní, ale předchozí verze stromu je přepsána novou. Program lze obměnit, jak ukazuje následující příklad. Nyní lze rekonstruovat všechny předchůdce vloženého uzlu. Každý odkaz na původní kořen zůstává validní, což ze stromu dělá persistentní datovou strukturu.
def binary_tree_insert(node, key, value):
if node is None:
return TreeNode(None, key, value, None)
if key == node.key:
return TreeNode(node.left, key, value, node.right)
if key < node.key:
return TreeNode(binary_tree_insert(node.left, key, value), node.key, node.value, node.right)
else:
return TreeNode(node.left, node.key, node.value, binary_tree_insert(node.right, key, value))
Takto změněná část programu průměrně využije Θ(log n) a v nejhorším případě Ω(n) paměti.
V obou verzích zabere tato operace v nejhorším případě čas úměrný výšce stromu, to znamená O(log n) času v průměru přes všechny stromy, ale O(n) času v nejhorším případě.
Jiný způsob jak vysvětlit proces vkládání nového uzlu do stromu je následující. Hodnota nového uzlu je nejdříve srovnávána s hodnotou kořene. Pokud je jeho hodnota menší než hodnota kořene, pak je srovnávána s hodnotou levého potomka kořene. Pokud je hodnota větší, je srovnávána s hodnotou pravého potomka kořene. Tento proces pokračuje, dokud není nový uzel srovnáván s uzlem bez potomka v hledaném směru a pak je v tomto směru nový uzel přidán v závislosti na jeho hodnotě.
Existují i další způsoby vkládání uzlů do binárního stromu, ale toto je jediný způsob vkládání uzlů do listů se současným zálohováním BST struktury.
Odstranění uzlu
Zde nastává několik případů ke zvážení.
- Odstranění listu: Odstranění uzlu bez potomků se jednoduše provede odstraněním uzlu ze stromu.
- Odstranění uzlu s jedním potomkem: Provede se nahrazením uzlu uzlem potomka.
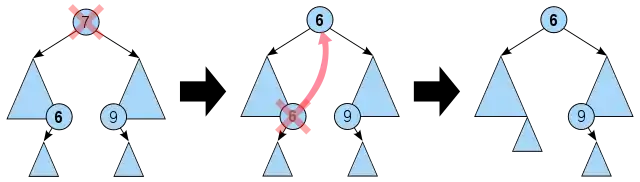
- Odstranění uzlu se dvěma potomky: Nechť se odstraněný uzel nazývá N. Pak je hodnota uzlu N nahrazena nejbližší vyšší (nejlevější uzel pravého podstromu), nebo nižší hodnotou (nejpravější uzel levého podstromu). Takový uzel má nanejvýš jednoho potomka, lze jej tedy ze stromu vyjmout podle jednoho z předchozích pravidel. Obě možnosti ilustruje následující obrázek, kdy je ze stromu odstraněn uzel s klíčem 7. V dobré implementaci je doporučeno obě varianty střídat, jinak dochází k narušení rovnováhy.
Zde je destruktivní příklad odstranění uzlu v jazyce C++:
void DeleteNode(struct node * & node) {
if (node->left == NULL) {
struct node *temp = node;
node = node->right;
delete temp;
} else if (node->right == NULL) {
struct node *temp = node;
node = node->left;
delete temp;
} else {
// Uzel má dva potomky, hledej předchůdce (nejpravější potomek levého podstromu).
struct node **temp = &node->left; // získej levého potomka mazaného uzlu
// najdi nejpravějšího potomka podstromu levého uzlu mazaného uzlu (předchůdce)
while ((*temp)->right != NULL) {
temp = &(*temp)->right;
}
// zkopíruj hodnotu předchůdce do mazaného uzlu
node->value = (*temp)->value;
// nyní smaž předchůdce - jeho hodnota byla přesunuta do původně mazaného uzlu
DeleteNode(*temp);
}
}
Přestože tato operace vždy neprochází strom až ke spodním listům, stát se to může, takže v nejhorším případě je spotřebovaný čas úměrný výšce stromu. Nepotřebuje ho více dokonce ani když má uzel dva potomky, protože stále prochází jednu cestu a nenavštěvuje žádný uzel dvakrát.
Procházení stromu
Průchod binárním vyhledávacím stromem nijak nevyužívá jeho speciální vlastnosti a odpovídá průchodu běžným stromem.
Řazení uzlů
BST může být využit k implementaci jednoduchého, ale neefektivního řadicího algoritmu. Podobně jako v algoritmu heapsort vkládáme všechny hodnoty které chceme seřadit do vhodně uspořádané datové struktury – v tomto případě se jedná o strukturu binárního stromu. Následně stromem projdeme in-order do hloubky a získáme seznam hodnot uspořádaný podle velikosti.
Funkce build_binary_tree spotřebuje v nejhorším případě času, a to pokud se přidávají již seřazené hodnoty. Ty se totiž spojí do seznamu takže strom nemá levé větve. Například build_binary_tree([1, 2, 3, 4, 5]) vytvoří strom (None, 1, (None, 2, (None, 3, (None, 4, (None, 5, None))))).

Existuje několik postupů, jak překonat tyto nedostatky. Nejčastější je samovyvažovací binární strom jehož časová náročnost O(n . log n) je asymptoticky optimální s řazením comparison sort.
V praxi ale špatný výkon vyrovnávací paměti a časová i paměťová režie (obzvlášť pro alokaci uzlů) způsobují, že řazení založené na BST zaostává za ostatními asymptoticky optimálními algoritmy, jako je algoritmus pro řazení rychlé řazení, či řazení haldou pro řazení statických seznamů. Na druhou stranu, je to jedna z nejefektivnějších metod inkrementálního řazení kde přidávání položek do seznamu zachová seznam seřazený.
Typy binárních vyhledávacích stromů
Existuje mnoho variant BST. AVL stromy a červeno-černé stromy představují formy samovyvažovacích binárních stromů. Rozvinutý strom je BST, který automaticky přesune často navštěvované elementy blíže ke kořeni. Podobně se chová splay strom. Ve stromě treap („tree heap“) si každý uzel udržuje informaci o prioritě a rodičovský uzel má pak větší prioritu než jeho potomek.
Porovnání výkonu
D. A. Heger v článku [1] porovnal výkonnost jednotlivých variant binárních vyhledávacích stromů. V průměru nejlepšího výkonu dosáhl treap, zatímco výkon červeno-černého stromu nejméně kolísal.
Optimální binární vyhledávací strom
Pokud se neplánují změny vyhledávacího stromu a přesně víme, jak často bude ke každému uzlu přistupováno, lze vytvořit optimální BST, kde je při vyhledávání průměrná doba vyhledání uzlu minimalizována.
Předpokládejme, že známe jednotlivé prvky a pro každý z nich známe průměrný počet jeho hledání. Pomocí dynamického programování pak lze najít optimální řešení.
I v případě, že známe jen odhad ceny vyhledávání, může takový systém v průměru podstatně zrychlit vyhledání. Například pokud máme BST českých slov použitých v korektoru chyb, je možné vyvážit strom podle frekvence použití slov v textu přemístěním slov jako jsou „a“ a „nebo“ blíže ke kořeni a slova jako „chřástal“ k listům. Strom je podobný Huffmanově stromu v tom, že častější uzly jsou blíže kořeni. Nicméně Huffmanovy stromy udržují datové prvky pouze v listech a ty není nutné řadit.
Pokud neznáme pořadí, v němž budou prvky ve stromě navštěvovány, můžeme použít rozvinutý strom, který je asymptoticky stejně dobrý jako statický vyhledávací strom sestavený pro všechny dílčí sekvence vyhledávacích operací.
Odkazy
- Vizualizace binárních vyhledavacích stromů
- Heger, Dominique A. (2004): A Disquisition on The Performance Behavior of Binary Search Tree Data Structures, European Journal for the Informatics Professional 5 (5)
- Názorná ukázka implementace BVS + flash animace vkládání do stromu (na konci stránky).
Související články
- Cyklický graf
- Samovyvažovací binární strom
- Rozvinutý strom
- Treap
- Binární vyhledávání
Externí odkazy
 Obrázky, zvuky či videa k tématu binární vyhledávací strom na Wikimedia Commons
Obrázky, zvuky či videa k tématu binární vyhledávací strom na Wikimedia Commons