Rychlé řazení
Rychlé řazení[1] nebo rychlé třídění[2], známý také pod anglickým názvem quicksort je jeden z nejrychlejších běžných algoritmů řazení založených na porovnávání prvků. Jeho průměrná časová složitost je pro algoritmy této skupiny nejlepší možná (O(N log N)), v nejhorším případě (kterému se ale v praxi jde obvykle vyhnout) je však jeho časová náročnost O(N2) při obvyklé implementaci. Další výhodou algoritmu je jeho jednoduchost.
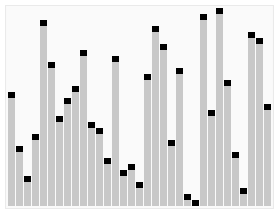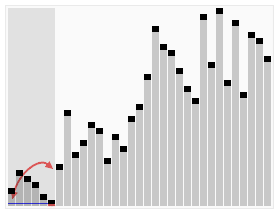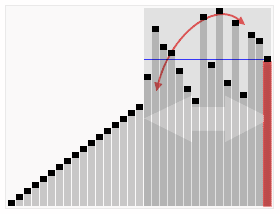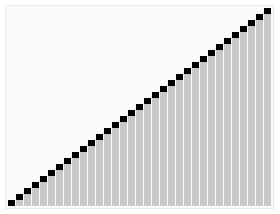
Objevil jej britský počítačový vědec Charles Antony Richard Hoare v roce 1961.
Algoritmus
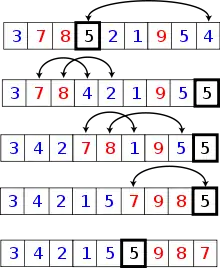
Základní myšlenkou algoritmu rychlého řazení je rozdělení řazené posloupnosti čísel na dvě přibližně stejné části (rychlé řazení patří mezi algoritmy typu rozděl a panuj). V jedné části jsou čísla větší a ve druhé menší, než nějaká zvolená hodnota (nazývaná pivot – anglicky „střed otáčení“). Pokud je tato hodnota zvolena dobře, jsou obě části přibližně stejně velké. Pokud budou obě části samostatně seřazeny, je seřazené i celé pole. Obě části se pak rekurzivně řadí stejným postupem, což ale neznamená, že implementace musí taky použít rekurzi.
Volba pivotu
Největším problémem celého algoritmu je volba pivotu. Pokud se daří volit číslo blízké mediánu řazené části pole, je algoritmus skutečně velmi rychlý. V opačném případě se jeho doba běhu prodlužuje a v extrémním případě je časová složitost O(N2). Přirozenou metodou na získání pivotu se pak jeví volit za pivot medián. Hledání mediánu (a obecně k-tého prvku) v posloupnosti běží v lineárním čase vzhledem k počtu prvků, tím dostaneme složitost O(N log N) algoritmu v nejhorším případě. Nicméně tato implementace není příliš rychlá z důvodu vysokých konstant schovaných v O notaci a v praxi se nepoužívá. Proto existuje velké množství alternativních způsobů, které se snaží efektivně vybrat pivot co nejbližší mediánu. Zde je seznam některých metod:
- První prvek – popřípadě kterákoli jiná pevná pozice. (Pevná volba prvního prvku je velmi nevýhodná na částečně seřazených množinách.)
- Náhodný prvek – často používaná metoda. Průměr přes každá data je O(N log N), přičemž zde se průměr bere přes všechny možné volby pivotů (rozděleno rovnoměrně). Nejhorší případ zůstává O(N2), protože pro každá data může náhoda nebo Velmi Inteligentní Protivník vybírat soustavně nevhodného pivota, např. druhé největší číslo. V praxi většinou není dostupný generátor skutečně náhodných čísel, proto se používá pseudonáhodný výběr.
- Metoda mediánu tří – případně pěti či jiného počtu prvků. Pomocí pseudonáhodného algoritmu (také se používají fixní pozice, typicky první, prostřední a poslední) se vybere několik prvků z množiny, ze kterých se vybere medián, a ten je použit jako pivot.
Pokud by bylo zaručeno, že pivota volíme vždy z 98 % prvků uprostřed a ne z 1 % na některé straně, algoritmus by stále měl nejhorší asymptotickou složitost O(N log N), byť s poněkud větší konstantou v O-notaci.
Praktické zkušenosti a testy ukazují, že na pseudonáhodných nebo reálných datech je algoritmus rychlé řazení nejrychlejší ze všech obecných řadicích algoritmů (tedy i rychlejší než Heapsort a Mergesort, které jsou formálně rychlejší). Rychlost rychlého řazení však není zaručena pro všechny vstupy. Maximální časová náročnost O(N2) algoritmus diskvalifikuje pro kritické aplikace.
Kód algoritmu v jazyce Pascal
procedure rychlerazeni(l, r: integer);
var
i, j, pivot, pom: integer;
begin
i := l; j := r;
pivot := akt[(l + r) div 2];
repeat
while (i < r) and (akt[i] < pivot) do i := i + 1;
while (j > l) and (pivot < akt[j]) do j := j - 1;
if i <= j then
begin
pom := akt[i];
akt[i] := akt[j];
akt[j] := pom;
i := i + 1;
j := j - 1;
end;
until i > j;
if j > l then rychlerazeni(l, j);
if i < r then rychlerazeni(i, r);
end;
Kód algoritmu v jazyce C
void rychlerazeni(int array[], int levy_zacatek, int pravy_zacatek)
{
int pivot = array[(levy_zacatek + pravy_zacatek) / 2];
int levy_index, pravy_index, pom;
levy_index = levy_zacatek;
pravy_index = pravy_zacatek;
do {
while (array[levy_index] < pivot && levy_index < pravy_zacatek)
levy_index++;
while (array[pravy_index] > pivot && pravy_index > levy_zacatek)
pravy_index--;
if (levy_index <= pravy_index) {
pom = array[levy_index];
array[levy_index++] = array[pravy_index];
array[pravy_index--] = pom;
}
} while (levy_index < pravy_index);
if (pravy_index > levy_zacatek) rychlerazeni(array, levy_zacatek, pravy_index);
if (levy_index < pravy_zacatek) rychlerazeni(array, levy_index, pravy_zacatek);
}
Omezení hloubky rekurze
Tento algoritmus vyžaduje více než jiné pečlivou implementaci. Zde uvedená základní rekurzivní verze algoritmu může být pro nasazení v praxi nevhodná, výše uvedený algoritmus pouze demonstruje funkční princip rychlého řazení. Jde o rekurzivní algoritmus a každé rekurzivní volání spotřebovává paměť zásobníku. Ve výše zmiňovaném nejhorším případě (opakovaná volba nejmenšího prvku za pivota) by spotřeba paměti rostla lineárně, což by mohlo dokonce způsobit pád aplikace. Problém s hlubokou rekurzí se nemusí při ladění projevit, protože hloubka rekurze závisí na řazených datech. Avšak zabránit hluboké rekurzi je možné. Po pivotizaci lze
- nejdříve řadit menší část za použití rekurze
- poté řadit větší část sekvence již nerekurzivně
Tím je zaručeno, že hloubka rekurze neroste nikdy lineárně, je nejvýše .

Nerekurzivní verze algoritmu
Implementace se, například kvůli rychlosti, může vyhnout použití rekurze a ošetřuje si zásobník sama. Také průmyslový standard MISRA C používaný pro vestavěné systémy použití rekurze zakazuje. Na zásobník se ukládají hranice ještě nezpracovaných částí. Důležitý trik pro zmenšení zásobníku je na zásobník uložit (pouze) tu větší část a dále, tedy dřív, zpracovávat vždy menší z rozdělených části. To zaručí, že stačí zásobník velikosti , tj. například pro miliardu prvků stačí hloubka 30 položek. Bez této optimalizace by byla paměť potřebná pro zásobník až lineární. Jedná se o postup ekvivalentní zabránění hluboké rekurze.
Algoritmus při běžné implementaci prochází prvky v poli sekvenčně (v obou směrech) a tak je přívětivý ke keši a využívá keš podobně jako cache-oblivious algoritmy.
Shrnutí
- rychlost výpočtu je vynikající , avšak při nejhorším případě časová náročnost roste na .
- při správné implementaci prakticky nepotřebuje dodatečnou paměť, řadí prvky přímo v poli
- jde o nestabilní algoritmus, způsob volby pivota může mít vliv na výsledek řazení
- vzhledem k nejhoršímu případu nemusí být vždy vhodný pro vestavěné systémy běžící na slabším hardware
- v průměru jde o nejrychlejší známý univerzální algoritmus pro řazení polí v operační paměti počítače
- k omezení pravděpodobnosti nejhoršího případu slouží různé postupy volby pivota
- jde o rekurzivní algoritmus, ale hloubku rekurze lze omezit; s použitím zásobníku jej lze převést na nerekurzivní
- nerekurzivní verze algoritmu je efektivnější (je rychlejší a spotřebuje méně paměti)
- bývá implementován v systémových knihovnách (např. v jazyku C funkce qsort z knihovny stdlib.h)


Reference
- Algoritmizace inženýrských výpočtů - podklady ke studiu. fast10.vsb.cz [online]. [cit. 2019-11-09]. Dostupné online.
- Quicksort. people.fjfi.cvut.cz [online]. [cit. 2019-11-09]. Dostupné online.
Související články
- merge sort
- řazení haldou (jiný algoritmus na řazení prvků)
Externí odkazy
- Informace o rychlém třídění (České vysoké učení technické v Praze, Fakulta jaderná a fyzikálně inženýrská)
- Recepty z programátorské kuchařky. Rozděl a panuj - informace o rychlém třídění
Rozděl a panuj
Literatura
Wirth, N.: Algoritmy a štruktúry údajov, Alfa, Bratislava, 1989