Support vector machines
Support vector machines (SVM) neboli metoda podpůrných vektorů je metoda strojového učení s učitelem, sloužící zejména pro klasifikaci a také pro regresní analýzu. Na jejím vynalezení se podílel zejména Vladimir Vapnik.
Základem metody SVM je lineární klasifikátor do dvou tříd. Cílem úlohy je nalézt nadrovinu, která prostor příznaků optimálně rozděluje tak, že trénovací data náležející odlišným třídám leží v opačných poloprostorech. Optimální nadrovina je taková, že hodnota minima vzdáleností bodů od roviny je co největší. Jinými slovy, okolo nadroviny je na obě strany co nejširší pruh bez bodů (maximální odstup, angl. maximal margin, česky je tento pruh někdy nazýván také pásmo necitlivosti nebo hraniční pásmo). Na popis nadroviny stačí pouze body ležící na okraji tohoto pásma a těch je obvykle málo - tyto body se nazývají podpůrné vektory (angl. support vectors) a odtud název metody.
Důležitou součástí techniky Support vector machines je jádrová transformace (angl. kernel transformation) prostoru příznaků dat do prostoru transformovaných příznaků typicky vyšší dimenze. Tato jádrová transformace umožňuje převést původně lineárně neseparovatelnou úlohu na úlohu lineárně separovatelnou, na kterou lze dále aplikovat optimalizační algoritmus pro nalezení rozdělující nadroviny. Trik je v tom, že nadrovina je popsána a při výpočtech je použitý pouze skalární součin, a skalární součin transformovaných dat <f(x), f(x1)> ve vysokorozměrném prostoru se nepočítá explicitně, ale počítá se K(x, x1), tj. hodnota jádrové funkce K na datech v původním prostoru parametrů.
Používají se různé kernelové transformace. Intuitivně, vyjadřují podobnost dat, tj. svých dvou vstupních argumentů. Výhodou této metody (a jiných metod založených na jádrové transformaci) je, že transformace se dá definovat pro různé typy objektů, nejen body v Rn. Např. pro grafy, stromy, posloupnosti DNA atd.
Lineární SVM
Lineární SVM je jednodušší varianta SVM metody, při které zůstáváme v původním prostoru příznaků a nedochází k žádné jádrové transformaci. Výsledkem potom je čistě lineární klasifikátor.
Separabilní případ
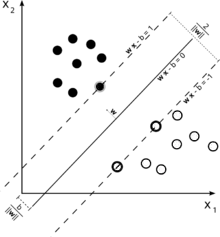
Nejjednodušším případem použití SVM je lineární klasifikátor pro lineárně separabilní data, tedy data, ve kterých lze obě třídy od sebe rozdělit nadrovinou. Mějme množinu trénovacích dat v podobě dvojic , kde je vektor a je informace od učitele nabývající hodnoty +1 nebo -1.



Nadrovinu, rozdělující body do dvou tříd, lze popsat rovnicí
|
(1) |

kde je normála nadroviny, její Eukleidovská norma a vzdálenost nadroviny od počátku souřadnic.



Nejkratší vzdálenosti nejbližších bodů na každé straně nadroviny od ní značíme a . Součet pak představuje šířku hraničního pásma. Cílem trénování SVM pak je nalézt takovou rozdělující nadrovinu, aby hraniční pásmo bylo nejširší možné. Body, ležící na hranici tohoto pásma a jejichž odebráním by se poloha optimální nadroviny změnila, jsou podpůrné vektory (angl. support vectors).



Formulace úlohy
Předpokládejme, že pro všechny body platí
|
(2) |

|
(3) |

což lze sloučit do jediné nerovnice
|
(4) |

Body, pro které platí rovnost v (2), leží na nadrovině .

Body, pro které platí rovnost v (3), leží na nadrovině .

Nadroviny a jsou kolmé na stejný normálový vektor a jejich vzdálenost od rozdělující nadroviny je . Šířka hraničního pásma tedy je a nadroviny s nejširším pásmem můžeme určit minimalizací vzhledem k podmínkám (4).





Pozn.: Z praktických důvodů se místo minimalizuje .

Lagrangeovská formulace
Lagrangeovská formulace úlohy má dvě hlavní výhody:
- Namísto podmínky (4) je omezení na samotné Lagrangeovy multiplikátory, s čímž se lépe pracuje.
- Trénovací data se ve všech výrazech vyskytují jen ve skalárních součinech, což je velmi důležité u nelineárního případu.
Zavedené nezáporné Lagrangeovy multiplikátory , jeden pro každou nerovnost v (4).

Lagrangeova funkce:
|
(5) |

Je třeba minimalizovat vzhledem k , a derivace vzhledem ke všem musejí být nulové, vše za omezení .




Jedná se o konvexní problém kvadratického programování, proto lze místo toho řešit duální problém - hledání maxima za následujících podmínek: že gradient vzhledem k a je nulový, a že .

Aby gradient podle a byl nulový, musí platit
|
(6) |

|
(7) |

Dosazením do (5) se získá duální Lagrangeova funkce ( - primární, - duální)

|
(8) |

Trénování SVM spočívá v maximalizaci vzhledem k , při omezení (8) a , s řešením daným (6).
Máme jedno pro každý trénovací bod, přičemž body, pro které jsou podpůrné vektory a leží v nadrovinách nebo , zatímco všechny ostatní mají a leží buď v jedné z nadrovin, nebo na té straně od nich, pro kterou platí ostrá nerovnost v (4).


Podpůrné vektory jsou nejdůležitějšími body trénovací množiny - pokud by se všechny ostatní body odstranily, novým natrénováním by se získala tatáž rozdělující nadrovina.
Karushovy-Kuhnovy-Tuckerovy podmínky
Karushovy-Kuhnovy-Tuckerovy (KKT) podmínky jsou nutné podmínky pro optimální řešení v úloze nelineárního programování za předpokladu splnění určitých podmínek regularity. Pro konvexní problémy jsou zároveň i postačujícími podmínkami.
SVM představují konvexní problém a podmínky regularity jsou pro ně splněné vždy. KKT podmínky jsou tím pádem nutné a postačující, aby byly řešením.

Pro primární problém KKT podmínky vypadají následovně:

KKT podmínky hrají roli při numerickém řešení SVM úlohy (viz sekce Metody řešení).
Testovací fáze
V testovací fázi klasifikujeme neznámé body, u nichž nevíme, do které třídy skutečně náležejí. Toto zjistíme tak, že spočítáme a výsledné znaménko nám řekne, na které straně rozdělující nadroviny daný bod leží. Podle toho ho přiřadíme do odpovídající třídy.

Neseparabilní případ
Složitější variantou lineárních SVM je případ, kdy se snažíme lineárně oddělit data, která nejsou plně lineárně separovatelná. Například se může jednat o zašuměná data, kde se jednotlivé třídy částečně překrývají a není proto možné najít jednoznačnou hranici. V takovémto případě chceme najít takovou rozdělující nadrovinu, aby k chybné klasifikaci docházelo co nejméně.
V takovéto situaci se provádí zmírnění podmínek (2) a (3) s přidanou cenou za jejich porušení, a to zavedením přídavné proměnné :

|
(14) |

|
(15) |

|
(16) |

Pro přiřazení ceny navíc za chyby se pak minimalizovaná funkce stanoví místo jako , kde je volitelný parametr a větší znamená větší penalizaci chyb.


Duální problém pak je:
Maximalizovat
|
(17) |

za podmínek
|
(18) |

|
(19) |

Řešení je opět
|
(20) |

kde je počet podpůrných vektorů.

Jediný rozdíl oproti předchozímu případu je tedy ten, že nyní jsou shora omezené .
Primární Lagrangeova funkce je
|
(21) |

kde jsou Lagrangeovy multiplikátory zavedené pro zajištění .


KKT podmínky pro primární problém pak jsou
|
(22) |

|
(23) |

|
(24) |

|
(25) |

|
(26) |
|
(27) |
|
(28) |

|
(29) |

|
(30) |

kde jde od 1 do počtu trénovacích bodů, jde od 1 do dimenze dat.


Práh lze určit na základě podmínek (29) a (30) dosazením jednoho z trénovacích bodů.
Nelineární SVM



V lineárním případě se jednalo o data, která byla plně nebo téměř lineárně separovatelná. Obecně toto však často neplatí a z toho důvodu byly zavedeny nelineární SVM. Základní myšlenkou je použití tzv. jádrového triku (anglicky kernel trick), s jehož pomocí se provádí transformace dat z původního prostoru příznaků do prostoru vyšší dimenze, ve kterém již jsou lineárně separabilní.
Jinými slovy, provádíme zobrazení trénovacích dat z původního prostoru do jiného eukleidovského prostoru , ve kterém toto už platit bude:

|
(31) |

Prostor je obvykle mnohem větší, i až nekonečné, dimenze než původní prostor, dále značený , a v většinou neexistuje vektor, jehož obrazem by byl vektor .

Jelikož v rovnicích (17-19) se trénovací data vyskytují jen v podobě skalárních součinů mezi sebou, nemusíme vůbec znát zobrazení , stačí pouze znát vztah pro skalární součin . Využívá se tzv. jádrová funkce (angl. kernel function}) .



V testovací fázi lze použití také obejít - pro určení, do které třídy bod spadá, počítáme funkci signum z výrazu
|
(32) |

kde jsou podpůrné vektory.

Příklady nelineárních SVM
Mezi často používané jádrové funkce patří například:
- Polynom stupně :

|
(33) |

- Radiální bázové funkce:
|
(34) |

- Dvouvrstvá neuronová síť:
|
(35) |

Metody řešení
Problém optimalizace pomocí podpůrných vektorů lze řešit analyticky jen pokud je množství trénovacích dat velmi malé nebo v separovatelném případě pokud je předem známo, která data se stanou podpůrnými vektory. Při většině reálných použití je třeba rovnice (17-19) řešit numericky (se skalárními součiny nahrazenými ).

Pro jednodušší úlohy postačují standardní metody řešení konvexních úloh kvadratického programování s lineárními vazbovými podmínkami, pro složitější úlohy pak existují speciální techniky řešení.
Základní postup:
- Volba jádrové funkce a jejích parametrů.
- Volba parametru reprezentujícího kompromis mezi minimalizací chyby na trénovací množině a maximalizací šířky hraničního pásma.
- Vyřešení duálního problému pomocí vhodné techniky kvadratického programování:
- Určení podmínek optimality (KKT), které musí řešení splňovat.
- Definování strategie dosažení optimality zvyšováním duální váhové funkce vzhledem k vazbovým podmínkám.
- U rozsáhlejších úloh: volba algoritmu dekompozice tak, aby bylo třeba pracovat jen s částí dat najednou.
- Výpočet parametru na základě podpůrných vektorů.
- Klasifikace nových bodů.
Algoritmy dekompozice pro rozměrné úlohy:
Příkladem je "hroudová" metoda (angl. "chunking" method) - SVM se nejdříve natrénuje na malé podmnožině dat, na zbytku se otestuje a udělá se seznam chybných rozhodnutí seřazený podle toho, jak moc byly porušeny KKT podmínky. Další trénovací množina se vytvoří z prvních bodů ze seznamu a ze všech už nalezených podpůrných vektorů, kde je určeno heuristicky. Proces pokračuje dokud pro všechny body není rozhodnuto správně.


Tato metoda vyžaduje, aby počet podpůrných vektorů byl dostatečně malý na to, aby se Hessova matice o rozměru vešla do paměti počítače. Pro ještě rozměrnější úlohy existují jiné algoritmy.

SVM regrese
Kromě klasifikace se SVM využívají také pro regresní analýzu.
SVM regrese využívá -necitlivou ztrátovou funkci (angl. -insensitive loss function) - pokud rozdíl mezi očekávanou a skutečnou hodnotou je méně než , není to považováno za chybu. Tedy chceme, aby platilo

|
(36) |

Opět se minimalizuje a jsou zavedené přídavné proměnné (angl. slack variables) a .


Pro lineární -necitlivou funkci je pak úkolem minimalizovat
|
(37) |

za podmínek



Pro nelineární regresní funkce se používá podobný postup jako u klasifikace - duální Lagrangeova funkce, jádrová transformace, atd.
Namísto pevně daného parametru je také možné stanovit maximální podíl bodů, pro které nebude platit vztah (36).
Uplatnění SVM
Support Vector Machines mají široké uplatnění, zejména pro klasifikaci. Reálné aplikace zahrnují například oblasti zpracování textu, počítačového vidění (např. rozpoznávání obličejů, rozpoznávání ručně psaného textu) nebo bioinformatiky (např. klasifikace proteinů).
Oproti některým srovnatelným typům klasifikátorů mají SVM několik výhod:
- Trénování vždy najde globální řešení. Na rozdíl od například neuronových sítí u SVM neexistují žádná lokální minima, která by nebyla zároveň globálním minimem.
- Reprodukovatelné výsledky, nezávislé na volbě konkrétního algoritmu nebo např. počátečního bodu.
- Malý počet parametrů modelu, které je třeba určit po výběru typu jádrové funkce (může být zároveň i nevýhodou - viz níže).
SVM s sebou nese i problémy či nevýhody:
- Správná funkce SVM z velké části záleží na vhodné volbě jádrové funkce. Jakmile ji stanovíme, máme jen jeden parametr, tedy penaltu chyb. Správnou jádrovou funkci ale nemusí být snadné najít.
- U velmi rozsáhlých úloh (miliony podpůrných vektorů) je problém s rychlostí a paměťovými nároky. Vhodné algoritmy pro jejich řešení jsou stále ještě předmětem výzkumu.
Myšlenky vycházející ze SVM (málo podpůrných vektorů, maximální odstup a jádrové transformace) byly také použity i pro návrh algoritmů pro další úlohy strojového učení, např. úlohy binární klasifikace na zašuměných datech (tzv. soft margin), diskrétní klasifikace (do více tříd), regrese, jádrová analýza hlavních komponent (PCA), ranking, strukturované učení, učení z jedné třídy (one class support vector, single class data description).
Odkazy
Literatura
- Bernhard Schölkopf, Alex Smola: Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond (Adaptive Computation and Machine Learning), MIT Press, Cambridge, MA, 2002, ISBN 0-262-19475-9.
- Ingo Steinwart, Andreas Christmann: Support Vector Machines, Springer, New York, 2008. ISBN 978-0-387-77241-7. 602 pp.
- Nello Cristianini, John Shawe-Taylor: Kernel Methods for Pattern Analysis, Cambridge University Press, Cambridge, 2004, ISBN 0-521-81397-2
- Christopher J. C. Burges: A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and Knowledge Discovery, 2(2):121-167, 1998.
- Vladimir Vapnik: Statistical Learning Theory, Wiley, Chichester, GB, 1998.
- Vladimir Vapnik: The Nature of Statistical Learning Theory, Springer Verlag, New York, NY, USA, 1995.
- K. Bennett, C. Campbell: Support Vector Machines: Hype or Hallelujah?, ACM SIGKDD Explorations Newsletter, 2(2):1-13, New York: ACM, 2000
- R. Freund, F. Girosi, E. Osuna: An Improved Training Algorithm for Support Vector Machines, Neural Networks for Signal Processing [1997] VII. Proceedings of the 1997 IEEE Workshop, pp. 276-285, IEEE, 1997