GLR analyzátor
GLR analyzátor nebo Tomitův analyzátor je metoda syntaktické analýzy pro bezkontextové gramatiky, která je zobecněním LR(k) metod. Zkratka GLR(k) znamená zobecněný LR analyzátor (anglicky Generalized LR(k)).
Východiskem GLR-analyzátoru je vytváření tabulky LR(k)-metody. Pro gramatiky, které nemají LR(k)-charakteristiku (včetně nejednoznačných gramatik), vede tyto proces k nejednoznačnostem, tzv. konfliktům:
- Konflikt přesun-redukce: je možné načíst další vstupní symbol na zásobník analyzátoru nebo nahradit rozpoznanou pravou stranu přepisovacího pravidla levou stranou pravidla.
- Konflikt redukce-redukce: existují dvě nebo více přepisovacích pravidel, kterými může být provedena redukce.
Algoritmus GLR tyto konflikty pseudoparalelně sleduje. Jako datová struktura slouží tzv. grafový zásobník (anglicky ''graph structured stack), což je orientovaný acyklický graf, který zachycuje všechny dílčí operace syntaktické analýzy.
Zásobník
Použitá reprezentace výsledků syntaktické analýzy se děje – podobně jako u tabulkového analyzátoru – pomocí orientovaného acyklického grafu.
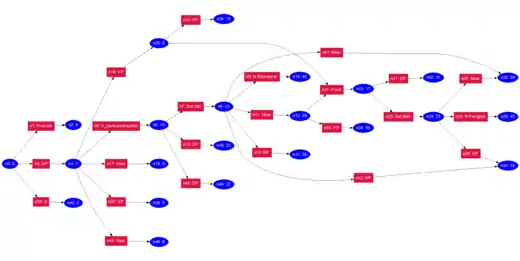
Obr. 1 ukazuje jeden takový graf po dokončení průběhu syntaktické analýzy pro ukázkovou větu „Sie beobachtet den Einbrecher mit dem Fernglas“ (Sleduje zloděje (s) dalekohledem).
Přitom je použita následující nejednoznačná gramatika:
- S → DP VP
- VP → Vbar
- VP → VP PP
- Vbar → Vtrans DP
- DP → Det NP
- DP → Pron
- NP → Nbar
- Nbar → N
- Nbar → Nbar PP
- PP → P DP
Tato gramatika zachycuje nejednoznačnost dané věta, která dovoluje dvě různé analýzy. Kvůli této nejednoznačnosti není gramatika LR(k), což znamená, že v tabulka analyzátoru obsahuje konflikty.
Každý uzel má unikátní jméno uzlu (které začíná písmenem „n“). Červené uzly obsahují prvky ze slovníku gramatiky, tedy pravidla s neterminálním symbolem na levé straně a slovy věty (terminálními symboly) pravé straně. Modré uzly obsahují čísla stavů LR-tabulky analýzy. Je dobře vidět, jak jsou v uzlu n21 dvě do té doby různé analýzy při začleňování předložkové fráze „mit“ spolu zkombinovány. Následující předložková fráze „mit dem Fernglas“ je tedy analyzována pouze jednou.
Algoritmus syntaktické analýzy
Stejně jako u LR(k)-metod se proces syntaktické analýzy skládá z řádek od řízený tabulkou přesunový případně redukční pravidla. Při přesunu je slovo ze vstupu odstraněno a uloženo na zásobník. Při krok redukce je pravá strana (γ) přepisovacího pravidla A → γ, které je uložena pozpátku na zásobníku, nahrazena levou stranou pravidla (A). Na rozdíl od LR(k)-metod však není redukovaná část ze zásobníku odstraněna, ale ponechána na zásobníku. To znamená, že zásobník neustále roste.
Proces je řízený GLR(k)-tabulkou. V každém okamžiku se syntaktický analyzátor nachází v definovaném stav (viz zásobníkový automat). S tímto stav a dalším symbolem nebo symboly na vstupu je použita GLR(k)-tabulka a další operace (shift, reduce, accept, error) a nový stav nastaven. Případné nejednoznačnosti (konfliktu) jsou kvaziparalelně sledovány. Následující operace přesunu však mohou tato vlákna paralelního zpracování znovu synchronizovat; to je důležité pro časovou složitost metody.
Vztah k jiným metodám syntaktické analýzy
GLR analyzátor lze považovat za předkompilovaný tabulkový analyzátor.
Odkazy
Reference
V tomto článku byl použit překlad textu z článku Tomita-Parser na německé Wikipedii.
Literatura
- GRUNE, Dick; JACOBS; CERIEL, J.H. Parsing Techniques. [s.l.]: Springer Science+Business Media, 2008. ISBN 978-0-387-20248-8.
- Masaru Tomita. LR parsers for natural languages. In: Coling 1984: 10th International Conference on Computational Linguistics. [s.l.]: [s.n.], 1984.
- Masaru Tomita. An efficient context-free parsing algorithm for natural languages. In: International Joint Conference on Artificial Intelligence. [s.l.]: [s.n.], 1985.