Syntaktický strom
Abstraktní syntaktický strom (také syntaktický strom nebo syntaktický graf) je v informatice stromovou reprezentací abstraktní syntaktické struktury zdrojového kódu napsaného v programovacím jazyce. Jeho vnitřními uzly jsou operátory a listy jsou operandy. Abstraktního syntaktického stromu se využívá primárně pro překlad a optimalizaci kódu. Jako příklad si můžeme představit strom, který reprezentuje booleovský výraz. V tomto stromu může překladač velmi pohodlně optimalizovat – např. pokud je jedna větev disjunkce vždy pravdivá, tak není třeba vyhodnocovat druhou větev. Syntaxe je abstraktní v tom smyslu, že nereprezentuje každý detail, který se vyskytuje v reálné syntaxi. Například seskupující závorky jsou ve stromové struktuře implicitní a syntaktické konstrukce jako if-podmínka-then mohou být označeny jediným uzlem se dvěma větvemi.
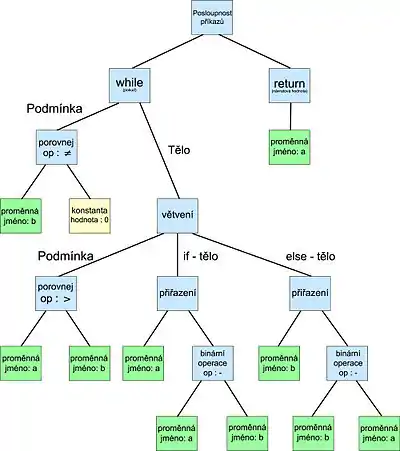
- while b ≠ 0
- if a > b
- a := a − b
- else
- b := b − a
- if a > b
- return a
To činí abstraktní syntaktické stromy odlišné od stromů konkrétních, které jsou tradičně označovány jako derivační stromy. Ty jsou často tvořeny parserem jako součást překladu a kompilace zdrojového kódu. Již postavený syntaktický strom lze doplňovat o dodatečné informace následným zpracováním, například kontextovou analýzou.
Abstraktní syntaktické stromy jsou také používané v programové analýze a v systémech pro transformace programů.
Struktura syntaktického stromu
- vnitřní uzly stromu jsou operátory
- listy stromu jsou jeho operandy
- každá část podstromu je samostatnou logickou jednotkou
Syntaktický strom při interpretaci
Abstraktní syntaktický strom (AST) je vhodný k řízení výkonu programu zejména pro Just-in-time kompilátory, kdy je lepší jako průběžný formát než bytekód. V přístupu řízení podle AST je potřeba analyzovat každou větu pouze jednou. Hlavní výhodou oproti bytekód interpretaci je, že AST udržuje globální program, strukturu a vztahy mezi instrukcemi (což v bytekódu nelze zjistit), a poskytuje kompaktnější reprezentaci. AST také umožňuje provádět lepší analýzu při běhu.
Aplikace v kompilátorech
Abstraktní syntaktický strom (AST) je datová struktura široce používaná v kompilátorech. Umožňuje reprezentovat strukturu programového kódu. AST je obvykle výsledek syntaktické části překladu programu. Většinou slouží jako mezikódová reprezentace programu pro další fáze překladu kompilátorem a má důležitou roli na výsledku kompilace, tedy například spustitelném programu.
Motivace
AST je produkt části překladu, které se říká syntaktická analýza. AST má vlastnosti, které jsou při dalších krocích překladu nezbytné. V porovnání se zdrojovým kódem AST neobsahuje určité prvky, jako například nedůležité interpunkce a oddělovače (závorky, složené závorky, středníky, atd.) Důležitějším rozdílem je to, že AST může být upraveno a vylepšeno vlastnostmi a popisky pro každý prvek, který obsahuje. Takovéto úpravy a vylepšení jsou nemožné bez zdrojového kódu programu, protože by to znamenalo změnit ho. Zatímco AST obvykle obsahuje extra informace o programu, díky tomu, že mu předchází analytická část překladu kompilátorem. Jednoduchým příkladem přidaných informací v AST může být pozice elementu ve zdrojovém kódu. Tato informace se využívá v případě chyby v kódu, k upozornění uživatele, kde se chyba nachází.
Potřeba a uplatnění AST vychází ze zděděné podstaty programovacích jazyků a jejich dokumentace. Jazyky jsou často víceznačné už ze své podstaty. Z důvodů vyhnutí se této víceznačnosti, programovací jazyky jsou často specifikovány jako bezkontextové gramatiky. Nicméně jsou zde často aspekty těchto programovacích jazyků, které nemůže bezkontextová gramatika vyjádřit nebo popsat, ale jsou součástí jazyka a jsou zdokumentovány v jeho specifikacích. Tyto detaily vyžadují kontext k tomu, aby mohlo být rozhodnuto o jejich správnosti a chování. Například pokud jazyk umožňuje definovat nové typy, bezkontextová gramatika nemůže předvídat jméno tohoto typu ani způsob, jak mohou být použity. Dokonce ani když jazyk obsahuje předdefinované typy, vynucení správného použití vyžaduje nějaký kontext. Dalším příkladem je Duck-typing, kde se typ elementu může měnit v závislosti na kontextu. Přetěžování operátorů je další příklad, kde správné použití a výsledná funkce závisí na kontextu. Java nabízí výborný příklad, operátor "+" je zároveň matematickým operátorem sčítání a zároveň operátor pro spojování řetězců.
Ačkoliv jsou zde i další datové struktury spojené s vnitřní prací kompilátoru, AST zastupuje unikátní funkci. Během první fáze překladu, syntaktické analýzy, překladač vytváří syntaktický strom. Tento strom může být použit k interpretaci téměř všech funkcí překladače, co se týká syntaktické části překladu. Ačkoliv tato metoda může vést k efektivnějšímu překladu, jde proti principu softwarového inženýrství při psaní a správě programů. Další výhodou je menší velikost stromu, menší hloubka i počet elementů.
Návrh
Při navrhování AST si musíme být vědomi funkcionality, kterou bude překladač očekávat. Jak již bylo řečeno, nemůžeme ukládat programové deklarace ve zdrojové formě. Zároveň s tím deklarace musí uchovávat typ a jejich umístění. Pořadí vykonávaných částí musí být přesně určeno a dobře definováno. Binární operace si musí pamatovat levé a pravé komponenty. Přiřazovací příkazy musí uchovat identifikátor, který uchová přiřazenou hodnotu. Tyto požadavky mohou být použity pro návrh takovéto datové struktury.
Je známo, že některé operace se vždy budou skládat ze dvou elementů, jako například sčítání. Nicméně některé jazykové konstrukce vyžadují libovolně velké množství potomků, jako například seznam argumentů, předávaných programu. Výsledkem je, že AST musí být dostatečně flexibilní a rychlý, aby umožňoval rychle přidávat libovolné množství potomků.
Dalším hlavním požadavkem návrhu AST je to, že umožní zpětným průchodem z AST opět získat zdrojový kód, který je dostatečně podobný s originálem a jeho vykonání je dostatečně stejné, jako program reprezentovaný AST.
Návrhové vzory
Kvůli složitosti požadavků na AST a následující složitosti překladače, je výhodné aplikovat správné principy vývoje softwaru. Jedním z principů je použít ověřené návrhové vzory ke zlepšení modularity a usnadnění vývoje.
Díky skutečnosti, že různé operace nemusí mít nutně různé datové typy, je důležité mít správnou hierarchii uzlů. To je obzvlášť nutné při vytváření a modifikaci AST během běhu překladače.
Protože překladač strom několikrát prochází, aby určil sémantické vlastnosti, je důležité udělat průchod stromem jednoduchou operací. (S.strom je datová struktura. Každý ji prochází jak chce, musí nebo umí.) Když překladač dojde do uzlu, provede specifikované operace, dle typu čehokoli daného uzlu. Zde se nabízí použití návrhového vzoru Visitor.
Použití
AST je intenzivně používáno během sémantické analýzy, kde kompilátor kontroluje správnost použití elementů programu a jazyka. Také, během této analýzy, kompilátor generuje tabulku symbolů dle AST.[zdroj?] Kompletní průchod stromem umožňuje ověřit správnost (syntaktické) struktury programu.
Po ověření správnosti, AST slouží jako základ pro krok, ve kterém se v kompilátoru generuje strojový kód programu. Často se jedná o případ, kdy AST je použito ke generování „mezikódové reprezentace“, která se poté používá ke generování konečného strojového kódu nebo bajtkódu.
Související články
Externí odkazy
 Obrázky, zvuky či videa k tématu Syntaktický strom na Wikimedia Commons
Obrázky, zvuky či videa k tématu Syntaktický strom na Wikimedia Commons - AST View: an Eclipse plugin to visualize a Java abstract syntax tree
- Good information about the Eclipse AST and Java Code Manipulation
- PMD: uses AST representation to control code source quality
- CAST representation
- eli project: Abstract Syntax Tree Unparsing
- Články
- JONES, Joel. Abstract Syntax Tree Implementation Idioms. www.hillside.net. Dostupné online. (anglicky) (overview of AST implementation in various language families)
- HOWARTH, Nicola. Abstract Syntax Tree Design. www.ansa.co.uk. Dostupné v archivu pořízeném dne 2008-11-20. (anglicky) (note that this merely presents the design of one particular project's AST, and is not generally informative)
- NEAMTIU, Iulian; FOSTER, Jeffrey S.; HICKS, Michael. Understanding source code evolution using abstract syntax tree matching. Department of Computer Science, University of Maryland at College Park: [s.n.], 2005. Dostupné online. (anglicky)
- BAXTER, Ira D., et al. Clone Detection Using Abstract Syntax Trees. www.semanticdesigns.com. Dostupné online. (anglicky)
- FLURI, Beat; WÜRSCH, Michael; PINZGER, Martin; GALL, Harald C. Change Distilling: Tree Differencing for Fine-Grained Source Code Change Extraction. seal.ifi.uzh.ch. Dostupné v archivu pořízeném dne 2009-05-30. (anglicky)
- Michael Würsch: Improving Abstract Syntax Tree based Source Code Change Detection. Diplomová práce. https://web.archive.org/web/20071216050010/http://seal.ifi.unizh.ch/137/
- LUCAS, Jason. Thoughts on the Visual C++ Abstract Syntax Tree (AST) [online]. Dostupné online. (anglicky)
- Tutoriál
- Abstract Syntax Tree Metamodel Standard [online]. Dostupné online. (anglicky)