Chyby typu I a II
Chyba typu I (neboli chyba prvního druhu) a Chyba typu II (neboli chyba druhého druhu) jsou přesné technické pojmy používané statistiky k popsání konkrétních chyb v testovacím procesu, kde (zjednodušeně řečeno) něco, co mělo být přijato, bylo odmítnuto, a kde něco, co mělo být odmítnuto, bylo přijato.
Naneštěstí jsou tyto pojmy používány mnohem obecnějším způsobem v sociálních vědách a jiných (obvykle bez jakéhokoliv vysvětlení jejich významu) k poukázání na chyby v úsudku. Tento článek je věnován čistě statistickým termínům a technickým problémům statistických chyb, které tyto pojmy popisují.
Teorie statistického testu
V teorii statistických testů je pojem statistická chyba nedílnou součástí testování statistických hypotéz. Test vyžaduje jednoznačný výrok nulové hypotézy, která obvykle koresponduje s obvyklým „přirozeným stavem“. Například „tento člověk je zdravý“, „tento obviněný je nevinen“ nebo „tento výrobek není rozbitý“. Alternativní hypotéza je negací nulové hypotézy, například „tento člověk není zdravý“ atd… Výsledek testu může být relativně negativní vzhledem k nulové hypotéze (nezdravý, vinen, rozbitý) nebo pozitivní (zdravý, nevinen, nerozbitý). Pokud výsledek testu koresponduje se skutečností, pak bylo učiněno správné rozhodnutí. Nicméně pokud výsledek nekoresponduje se skutečností, pak nastala chyba. Kvůli statistické povaze testu se chyba ve výsledku, až na vzácné případy, nedá zcela vyloučit. Rozlišujeme dva typy chyb: chyba typu I a chyba typu II.
Chyba typu I
Chyba typu I, jinak známá jako chyba prvního druhu, je chybné rozhodnutí učiněno poté, co test odmítne pravdivou nulovou hypotézu(H0). Chyba typu I může být přirovnána k takzvané falešné pozitivitě v jiných testových situacích. Zjednodušeně řečeno, vyšetřovatel může hlásit falešný poplach bez hrozby na dohled, lidově řečeno „sýčkovat“, kdy (H0: žádná hrozba). Chyba typu I může být vyjádřena jako chyba nadměrného skepticismu.[1]
Míra chyby typu I se nazývá hladina (významnosti) testu a značí se řeckým písmenem α (alfa). Obvykle se rovná úrovni významnosti testu. V případě jednoduché nulové hypotézy je α pravděpodobnost chyby typu I. Pokud je nulová hypotéza složená, je α maximum (supremum) možných pravděpodobností chyby typu I.
Chyba typu II
Chyba typu II, také známá jako chyba druhého druhu (též anglicky false negative), je chybné rozhodnutí učiněné, když test selže v odmítnutí falešné nulové hypotézy. Chyba typu II může být přirovnána k takzvané falešné negativitě v jiných testových situacích, může být vyjádřena jako chyba nadměrné důvěryhodnosti/důvěřivosti.[1] Zjednodušeně řečeno, vyšetřovatel může přehlédnout hrozbu (nespustit poplach). H0: žádná hrozba.
Míra chyby typu II se značí řeckým písmenem β (beta) a vztahuje se k síle testu (která se rovná 1 − β).
Co ve skutečnosti nazýváme chybou typu I a II, záleží přímo na nulové hypotéze. Negace nulové hypotézy způsobuje prohození chyb typu I a II.
Cílem testu je rozhodnout, zda může být nulová hypotéza odmítnuta. Statistický test může buď odmítnout (prokázat za nepravdivou) nebo selhat v odmítnutí (selhat v prokázání za nepravdivou) nulové hypotézy, ale nikdy ji prokázat za pravdivou (jinými slovy selhání v odmítnutí nulové hypotézy ji neprokazuje za pravdivou).
Příklad
V praxi může být chyba typu I vyjádřena jako „usvědčení nevinného člověka“ (prohlášen za viníka) a chyba typu II jako „nechat pachatele na svobodě“.
Chyba typu II nastává, když je nulová hypotéza nepravdivá, což v přeneseném smyslu slova znamená např.: přidávání fluoridu do zubní pasty je skutečně efektivní proti zubnímu kazu, ale data jsou taková, že nulová hypotéza nemůže být odmítnuta, takže se nedá prokázat jeho existující efekt.
Tabularizované vztahy mezi pravdivostí/nepravdivostí nulové hypotézy a výsledky testu:
| Nulová hypotéza (H0) je pravdivá | Nulová hypotéza (H0) je nepravdivá | |
|---|---|---|
Falešně pozitivní | Pravdivě pozitivní | |
Pravdivě negativní | Falešně negativní |
Pochopení chyb typu I a II
Z Bayesova úhlu pohledu je chyba typu I taková, která se dívá na informaci, která by sice neměla výrazně změnit něčí prioritní předpoklad pravděpodobnosti, ale změní. Chyba typu II je taková, která se dívá na informaci, která by měla změnit něčí předpoklad, ale nezmění.
Testování hypotéz je umění testování, zda odchylka mezi dvěma distribucemi může být vysvětlena náhodou nebo ne. V mnoha praktických aplikacích jsou chyby typu I více choulostivé než chyby typu II.
V těchto případech je pozornost obvykle soustředěna na minimalizování výskytu této statistické chyby. Pokud předpokládáme, že pravděpodobnost chyby typu I je 1%, pak je zde 1% šance, že pozorovaná variace není pravdivá. Toto se nazývá úroveň významnosti, značí se řeckým písmenem α (alfa). Zatímco 1% může být přijatelná úroveň významnosti pro jednu aplikaci, jiná aplikace může vyžadovat úplně jinou úroveň. Například standardní cíl six sigma je dosáhnout přesnosti na 4.5 standardních odchylek nad nebo pod průměrem. To znamená, že pouze 3.4 díly z milionu v procesu s normálním rozdělením mohou být vadné.
Záměna významů výsledků
Jak už bylo řečeno, klíčová je volba otázky:
- V lékařství se typicky dělají testy na nemoce. Hypotézou-otázkou tedy bývá, zda pacient má danou chorobu. Apriori tedy emočně „pozitivní výsledek testu“, potvrzení nemoci, vnímáme negativně.
- Při technickém testování je pozitivní hlášení naopak vytouženým výsledkem: „Všechny systémy hlásí zelenou, kapitáne!“
Tedy už pouhé položení „otázky“, tedy zda se testuje „hrozba“, nebo naopak ověřuje „soulad“, dává pojmům „false positive“ / „false negative“ opačné významy: V hovoru je snadno lze zaměnit. Proto je pro správné porozumění vždy lépe podávat celé hlášení, podobně jako ve školách nutí „odpovídat celou větou“:
- „Náš test na přítomnost XY vyšel pozitivně, XY byl detekován.“
- místo krátké odpovědi „test vyšel pozitivně“, s implicitním uvažováním předpokladu, že protistrana, příjemce zprávy, přece ví, co se tím myslí.
Příjemce konkrétní technicky ověřovanou hypotézu totiž v praxi často nezná, zajímá ho až výsledek z jeho vlastního pohledu, ne z pohledu řešitele.
Zdroj nedorozumění
Minimalisticky čisté by bylo výsledek v hlášení ani vůbec nevyhodnocovat, pouze konstatovat fakt „XY byl detekován“. To proto, že:
- zadavatelovo (byť subjektivní) ohodnocování takového výsledku nemusí být řešitelem nijak předjímáno, vyhodnocení nemuselo být součástí objednávky;
- a řešitelovo ohodnocování výsledku by zadavatele navíc mohlo zmást, ani zadavatele nemusí zajímat: Zadavatel totiž pro své účely může používat svou vlastní sadu kritérií pro ohodnocení, úplně jiná než by řešitel čekal, navíc před řešitelem často i úmyslně skrytá (ad obchodní tajemství).
Potvrzení hypotézy nijak nesouvisí s pozitivním/negativním vnímáním takové zprávy zadavatelem: Ačkoli se slova „pozitivní“ / „negativní“ v reportu výsledků zadavateli mohou objevovat, nemají ještě nic společného s důsledky, které zadavateli taková zpráva přináší, což ale v běžném životě může být zdrojem nedorozumění. Takovým bývá například těhotenský test.
Následky chyb typu I a II
Oba typy chyb jsou problémy pro jedince, společnosti a analýzu dat. Falešně pozitivní (s nulovou hypotézou „zdravý“) v medicíně způsobuje nepotřebné obavy nebo léčbu, zatímco falešně negativní dává pacientovi nebezpečnou iluzi dobrého zdraví a nemusí se mu dostat potřebné léčby. Falešně pozitivní v kontrole kvality výroby (s nulovou hypotézou, že produkt je kvalitní) vyhodí produkt, který je ve skutečnosti kvalitní, zatímco falešně negativní označí pokažený produkt jako funkční. Falešně pozitivní (s nulovou hypotézou bez žádného účinku) ve vědeckém výzkumu hlásí účinek, který ve skutečnosti neexistuje, zatímco falešně negativní selže ve zjištění účinku, který ve skutečnosti existuje.
Založeno na následcích chyby ve skutečném životě, jeden typ může být vážnější než jiný. Například NASA inženýři by preferovali vyhodit elektronický obvod, který je ve skutečnosti v pořádku (nulová hypotéza H0: nerozbitý; skutečnost: nerozbitý; akce: vyhozen; chyba: typ I, falešně pozitivní), než aby na vesmírném plavidle použili rozbitý (nulová hypotéza H0: nerozbitý; skutečnost: rozbitý; akce: použit; chyba: typ II, falešně negativní). V takové situaci chyba typu I zvedá rozpočet, ale chyba typu II by ohrozila celou misi.
Stejně tak soudy nastavují vysoký práh pro důkazy a proces a někdy raději pustí někoho, kdo je vinen (nulová hypotéza: nevinen; skutečnost: vinen; výsledek testu: nevinen; akce: propustit; chyba: typ II, falešně negativní), než aby usvědčil někoho, kdo je nevinen (nulová hypotéza: nevinen; skutečnost: nevinen; výsledek testu: vinen; akce: usvědčit; chyba: typ I, falešně pozitivní). Každý systém činí svoji vlastní volbu, pokud jde o to, kde udělat mez.
Minimalizování chyb v rozhodnutí není jednoduchý úkol; pro jakoukoli danou velikost vzorku snaha snížit jeden typ chyby obecně vede ke zvýšení druhého typu chyby. Jediný způsob, jak minimalizovat oba typy chyb bez vylepšení testu je zvětšit velikost vzorku, což může nebo nemusí být proveditelné.
Etymologie
V roce 1928 Jerzy Neyman (1894–1981) a Egon Sharpe Pearson (1895–1980), oba vynikající statistici diskutovali o problémech spojených s „rozhodováním, zda daný vzorek může nebo nemůže být chápán jako náhodně vybraný z určité populace“ [2]p. 1: a jak Florence Nightingale David poznamenala, „je nutné si zapamatovat, že slůvko 'náhodný' by se mělo aplikovat na metodu výběru vzorku a ne na vzorek samotný“.[3]
Určili „dva zdroje chyby“, jmenovitě:
- (a) chyba odmítnutí hypotézy, která by měla být přijata a
- (b) chyba přijetí hypotézy, která by měla být odmítnuta.[2]p.31
V roce 1930 rozvinuli tyto dva zdroje chyby, poznamenajíc, že:
- ...v testovacích hypotézách musí být brány v potaz dvě úvahy, (1) musíme být schopni redukovat šanci odmítnutí pravdivé hypotézy na tak malou hodnotu jako si přejeme; (2) test musí být vymyšlen tak, aby odmítl testovanou hypotézu, která je pravděpodobně nepravdivá.[4]
V roce 1933 zpozorovali, že tyto „problémy jsou vzácně prezentovány v takové formě, že dokážeme s jistotou rozlišovat mezi pravdivou a nepravdivou hypotézou“ (p. 187). Také si všimli, že v rozhodování, zda přijmout nebo odmítnout určitou hypotézu mezi „řadou alternativních hypotéz“ (p. 201), je velmi snadné udělat chybu:
- ...[a] tyto chyby jsou dvou druhů:
- (I) odmítneme H0 [testovanou hypotézu] když je pravdivá,
- (II) přijmeme H0, zatímco některá alternativní hypotéza Hi je pravdivá.[5]p.187
Ve všech spisech napsaných společně Neymanem a Pearsonem výraz H0 vždy značí „testovanou hypotézu“ (viz [5] p. 186).
Ve stejném spisu[5]p. 190 nazývají tyto dva zdroje chyby, chybami typu I a chybami typu II.
Příbuzné pojmy
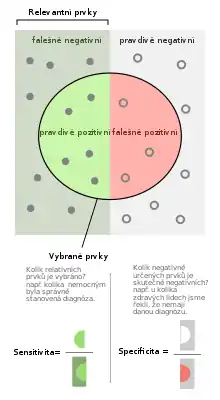
Falešně pozitivní míra
Falešně pozitivní míra je poměr chybějících událostí, které ustupují pozitivnímu výsledku testu.
Falešně pozitivní míra je rovna úrovni významnosti. Specificita testu se rovná 1 minus falešně pozitivní míra.
V testování statistických hypotéz, se tomuto pojmu přiřazuje řecké písmeno α, a 1 − α je definováno jako specificita testu. Zvyšování specificity testu snižuje pravděpodobnost chyb typu I, ale zvyšuje pravděpodobnost chyb typu II (falešně negativní, které odmítnou alternativní hypotézu, zatímco je pravdivá).
Falešně negativní míra
Falešně negativní míra je poměr událostí, které jsou testovány, kterým ustupují negativní výsledky testu.
V testování statistických hypotéz se tomuto pojmu přiřazuje řecké písmeno β. „Síla“ (neboli „sensitivita“) testu se rovná 1 − β.
Nulová hypotéza
Pro statistiky je běžnou praxí provádět testy, aby se mohlo určit, zda „spekulativní hypotéza“ týkající se pozorovaného fenoménu ve světě může nebo nemůže být podpořena. Výsledky takového testování rozhodují, zda určitá sada výsledků rozumně souhlasí nebo nesouhlasí se spekulovanou hypotézou.
Na základě předpokladu statistické konvence, že spekulovaná hypotéza je chybná a takzvané „nulové hypotézy“, že pozorovaný fenomén se jednoduše objeví náhodně, test rozhodne, zda tato hypotéza je správná nebo chybná. Proto je testovaná hypotéza často nazývána nulovou hypotézou, protože je to tato hypotéza, která má být buď anulována nebo neanulována testem. Když je nulová hypotéza anulována, je možné se domnívat, že data podporují „alternativní hypotézu“ (která je tou původní spekulovanou).
Důsledná aplikace Neymanovy a Pearsonovy konvence reprezentace „hypotézy k otestování“ (nebo „hypotézy k anulování“) s výrazem H0 statistiky vedla k okolnostem, kde mnozí rozumí pojmem „nulová hypotéza“ pojem „nil hypotéza“ – prohlášení, že pochybovaným výsledkům vzrostly šance. Toto není nezbytně nutné – klíčové omezení podle Fishera (1966), je takové, že „nulová hypotéza musí být přesná, je prosta nejasností a rozporů, protože musí podporovat bázi 'problému distribuce', jejímž řešením je test významnosti.“[6] Jako následek je v experimentální vědě nulová hypotéza obecně prohlášení, že určité opatření nemá žádný efekt; v pozorovací vědě to znamená, že není rozdílu mezi hodnotou konkrétní měřené proměnné a hodnotou experimentálního předpokladu.
Rozsah, ve kterém pochybovaný test ukazuje, že „spekulovaná hypotéza“ byla (nebo nebyla) anulována, se nazývá statistická významnost; a čím vyšší je úroveň významnosti, tím menší je pravděpodobnost, že pochybovaný fenomén by mohl být způsoben čistě náhodou. Britský statistik Sir Ronald Aylmer Fisher (1890–1962) řekl, že „nulová hypotéza“:
- ... není nikdy prokázána nebo uznána, ale je možné ji vyvrátit v procesu experimentování. O každém experimentu se dá říci, že existuje pouze za účelem poskytnout faktům šanci vyvrátit nulovou hypotézu. (1935, p.19)
Bayesova věta
Možnost, že pozorovaný pozitivní výsledek je falešně pozitivní, může být vypočítána použitím Bayesovy věty.
Klíčový koncept Bayesovy věty je, že pravdivé míry falešně pozitivních a falešně negativních nejsou funkcí přesnosti pouze testu samotného, ale také skutečnou mírou nebo frekvencí výskytu uvnitř testované populace.
Teorie systémů
V teorii systémů je navíc často definována chyba typu III[7]: typ III (δ): položení špatné otázky a použití chybné nulové hypotézy.
David
Florence Nightingale David (1909–1993) [8], občasná kolegyně Neymana a Pearsona na University College London, udělala humornou poznámku na konci její práce z roku 1947, která říká, že v případě jejího vlastního výzkumu by možná Neymanovy s Pearsonovy „dva zdroje chyby“ mohly být rozšířeny o třetí:
- Byla jsem zainteresovaná snahou vysvětlit, co považuji za základní myšlenky [mé „teorie podmíněných výkonových funkcí“], a předejít možné kritice, že upadám do chyby (třetího druhu) a že volím test záměrně falešně, aby vyhovoval významu vzorku. (1947, p.339)
Mosteller
V roce 1948 Frederick Mosteller (1916–2006) argumentoval, že „třetí typ chyby“ je vyžadován k popsání okolností, které pozoroval, jmenovitě:
- Chyba typu I: „odmítnutí nulové hypotézy, zatímco je pravdivá“.
- Chyba typu II: „přijmutí nulové hypotézy, zatímco je falešná“.
- Chyba typu III: „správné odmítnutí nulové hypotézy z chybného důvodu“. (1948, p. 61)
Kaiser
Podle Henry F. Kaisera (1927–1992) v jeho práci z roku 1966 rozšířil Mostellerovu klasifikaci jako chybu třetího druhu, což mělo za následek nesprávné rozhodnutí o směru následujícím odmítnutý „dvouocasý“ test hypotéz. V jeho diskuzi (1966, pp. 162–163) Kaiser také mluví o α chybách, β chybách, a γ chybách pro chyby typu I, typu II a typu III (C.O. Dellomos).
Kimball
V roce 1957 Allyn W. Kimball, statistik pro Oak Ridge National Laboratory, předložil jiný typ chyby, která stojí za „prvním a druhým typem chyby v teorii testování hypotéz“. Kimball definoval tuto novou „chybu třetího druhu“ jako „chybu způsobenou podáním správné odpovědi na nesprávný problém“ (1957, p. 134).
Matematik Richard Hamming (1915–1998) vyjádřil svůj pohled na věc jako „Je lepší vyřešit problém chybnou cestou, než řešit nesprávný problém správnou cestou“.
Harvardský ekonom Howard Raiffa popisuje událost, kdy také on „spadl do pasti pracování na nesprávném problému“ (1968, pp. 264–265).
Mitroff a Featheringham
V roce 1974 Ian Mitroff a Tom Featheringham rozšířili Kimballovu kategorii, argumentujíc, že „jeden z nejdůležitějších činitelů řešení problému je, jak byl tento problém především prezentován nebo formulován“.
Definovali chyby typu III jednak jako „chybu vyřešení nesprávného problému, zatímco bychom měli řešit správný problém“ nebo jako „chybu zvolení špatné prezentace problému, zatímco bychom měli zvolit správnou prezentaci problému“ (1974), p. 383.
V roce 2009 kniha Dirty rotten strategies od Iana I. Mitroffa a Abrahama Silverse popsala chyby typu III a IV, poskytujíc mnoho příkladů obou, rozvíjejíc dobré odpovědi na špatné otázky (III) a úmyslně vybírajíc špatné otázky pro intenzivní a zkušené vyšetřování (IV). Většina příkladů nemá nic co do činění se statistikou, spíše se týkají problémů veřejné politiky nebo obchodních rozhodnutí.[9]
Raiffa
V roce 1969 harvardský ekonom Howard Raiffa v žertu navrhl „kandidáta na chybu čtvrtého druhu: vyřešení správného problému příliš pozdě“ (1968, p. 264).
Marascuilo a Levin
V roce 1970 L. A. Marascuilo a J. R. Levin předložili „čtvrtý typ chyby“ – „chybu typu IV“ – kterou definovali po Mostellerově způsobu jako omyl v „nesprávné interpretaci správně odmítnuté hypotézy“; která, jak navrhli, je ekvivalentem k „lékařově správné diagnóze nemoci, následované receptem na nesprávný lék“ (1970, p. 398).
Příklady použití
Statistické testy vždy zahrnují kompromis mezi:
- (a) přijatelnou úrovní falešně pozitivních (ve které shoda je vyjádřena jako neshoda) a
- (b) přijatelnou úrovní falešně negativních (ve které není shoda detekována).
Prahová hodnota může být pozměněna, aby byl test více restriktivní nebo více sensitivní; u více restriktivních testů stoupá riziko odmítnutí správně pozitivních a u více senzitivních testů stoupá riziko přijetí falešných pozitivních.
Kontrola zásob
Automatizovaný systém kontroly skladu, který odmítne zásilku zboží vysoké kvality způsobí chybu typu I, zatímco systém, který přijme nekvalitní zboží způsobí chybu typu II.
Počítače
Představa „falešně pozitivních“ a „falešně negativních“ má širokou obecnost ve světě počítačů a počítačových aplikací.
Počítačová bezpečnost
Slabá místa zabezpečení je důležité zvážit, aby všechna data v počítačích byla v bezpečí, zatímco udržujeme přístup k těmto datům pro povolané uživatele (viz Počítačová bezpečnost). Moulton (1983), upozorňuje na důležitost:
- vyhnutí se chybám typu I (nebo falešně pozitivním), které identifikují ověřené uživatele jako podvodníky.
- vyhnutí se chybám typu II (nebo falešně negativním) které identifikují podvodníky jako ověřené uživatele (1983, p. 125).
Filtrace spamu
Falešně pozitivní nastává, když „spam filtering“ nebo „spam blocking“ techniky špatně klasifikují legitimní emailovou zprávu jako spam a ve výsledku ovlivňují jeho doručení. Ačkoli většina anti-spamových taktik dokáže blokovat nebo filtrovat vysoké procento nevyžádané pošty, učinit tak bez vytváření podstatných falešně-pozitivních výsledků je mnohem náročnější úkol.
Falešně negativní nastává, když spam není detekován jako spam, ale je vyhodnocen jako „non-spam“. Malý počet falešně negativních je ukazatelem efektivnosti metod filtrování spamu.
Malware
Termín falešně pozitivní se také používá když antivirový software nesprávně vyhodnotí nezávadný soubor jako vir. Nesprávné zjištění může být způsobeno heuristikou nebo nesprávným podpisem viru v databázi. Podobné problémy mohou nastat i u anti-trojanových nebo anti-spywarových softwarů.
Optické rozeznávání znaků (OCR)
Detekční algoritmy všech druhů často vytváří falešně pozitivní. Optical character recognition (OCR) software může najít „a“ tam, kde jsou jen nějaké tečky, které se použitému algoritmu zdají být „a“ .
Bezpečnostní screening
Falešně pozitivní se běžně objevují každý den na letištích na bezpečnostním screeningu. Instalované bezpečnostní alarmy mají zabránit pronesení zbraní na palubu letadla; jsou ale často nastaveny na tak vysokou citlivost, že mnohokrát za den vyvolají poplach kvůli malým předmětům, jako jsou klíče, přezky na opasku, mobilní telefony a hřebíčky v botách (viz metal detector.)
Poměr falešně pozitivních (identifikování nevinného cestujícího jako teroristu) k pravdivě pozitivním (detekování „možného“ teroristy) je tedy velmi vysoký; a protože téměř jakýkoliv alarm je falešně pozitivní, je pozitivní prediktivní hodnota těchto screeningových testů velmi nízká.
Relativní cena falešně negativních výsledků určuje pravděpodobnost, že tvůrci testu dovolí, aby tyto události nastaly. Jelikož cena falešně negativní v tomto scénáři je extrémně vysoká (nezjištění bomby pronesené na palubu letadla by mohlo vyústit ve smrt stovek lidí) zatímco cena falešně pozitivní je relativně nízká (jednoduše se vykoná detailnější prohlídka), je nejvhodnější test takový, který má nízkou statistickou specificitu ale vysokou senzitivitu (povolí vysokou míru falešně pozitivních výměnou za minimum falešně negativních).
Biometrie
Biometrické porovnávání, jako třeba otisk prstu, rozpoznávání obličeje nebo duhovky, je náchylné k chybám typu I a II. Nulová hypotéza je taková, že vstup identifikuje někoho ze seznamu hledaných lidí, z čehož vyplývá:
- pravděpodobnost výskytu chyby typu I se nazývá „Míra falešného odmítnutí – False Reject Rate“ (FRR),
- zatímco pravděpodobnost výskytu chyby typu II se nazývá „Míra falešného přijetí – False Accept Rate“ (FAR)[10]
Pokud je systém navržen tak, aby jen vzácně našel shodu s podezřelým, pak se pravděpodobnost chyby typu II nazývá „Míra falešného poplachu“. Na druhou stranu pokud je systém používán pro ověřování a přijmutí je běžné, pak je FAR měřítkem bezpečnosti systému, zatímco FRR je ukazatelem úrovně uživatelských potíží.
Lékařský screening
V lékařské praxi je velký rozdíl mezi aplikacemi určenými ke screeningu a testování:
- Screening zahrnuje relativně levné testy dostupné široké veřejnosti, žádný z nich však neukazuje jakoukoli zjevnou známku nemoci.
- Testování zahrnuje mnohem dražší, často invazivní metody, které jsou podávány pouze těm, kteří vykazují jasnou známku nemoci a jsou nejčastěji používány k potvrzení diagnózy.
Většina států v USA například vyžaduje, aby novorozenci podstoupili vyšetření na fenylketonurii, hypothyroidismus a jiné vrozené poruchy. I když vykazují vysokou míru falešně pozitivních, screeningové testy jsou považovány za cenné, jelikož vysoce zvyšují pravděpodobnost nálezu těchto poruch již v rané fázi.
Jednoduché krevní testy, používané pro kontrolu potenciálních dárců krve kvůli HIV a hepatitidě, mají významný podíl falešně pozitivních; nicméně lékaři používají mnohem dražší a přesnější testy k určení, zda je člověk skutečně nakažen některým z těchto virů.
Ideální screeningový test by měl být levný, snadný na vykonání a neprodukovat žádné falešně negativní, pokud je to možné. Takové testy obvykle produkují více falešně pozitivních, které mohou být následně vyřazeny sofistikovanějším (a dražším) testováním.
Lékařské testování
Falešně negativní a falešně pozitivní jsou v lékařském testování význačným problémem.
Falešně negativní mohou poskytnou lživou zprávu pacientovi a lékaři, že je pacient zdravý, zatímco není. To občas vede k nesprávné léčbě pacienta i nemoci. Běžným příkladem je spoléhání se na test měření krevního tlaku ke zjištění zúžení srdečních cév (Ateroskleróza), i když měření krevního tlaku pouze zjistí omezení krevního toku v koronární tepně vzhledem k aortální stenóze.
Falešně negativní způsobují vážné problémy, obzvláště pokud hledaný stav je zcela běžný. Pokud test s falešně' negativní mírou jen 10% je použit k otestování populace se skutečnou mírou výskytu 70%, spousta „negativních“ nalezených testem bude falešná. (viz Bayesova věta)
Falešně pozitivní mohou také způsobovat vážné problémy, když hledaný stav je vzácný. Když má test falešnou pozitivní míru jednoho z tisíce, ale jen jeden z milionu vzorků (nebo lidí) je skutečně pozitivní, většina „pozitivních“ nalezených testem bude falešná. Pravděpodobnost, že pozorovaný pozitivní výsledek je falešně pozitivní, může být vypočítána užitím Bayesovy věty.
Odkazy
Reference
V tomto článku byl použit překlad textu z článku Type I and type II errors na anglické Wikipedii.
- SHERMER, Michael. The Skeptic Encyclopedia of Pseudoscience 2 volume set. [s.l.]: ABC-CLIO, 2002. Dostupné online. ISBN 1576076539. S. 903. (anglicky)
- NEYMAN, J.; PEARSON, E.S. Joint Statistical Papers. [s.l.]: Cambridge University Press, 1967. Kapitola On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference, Part I, s. 1–66. (anglicky)
- DAVID, F.N. Probability Theory for Statistical Methods. [s.l.]: Cambridge University Press, 1949. S. 28. (anglicky)
- PEARSON, E.S.; NEYMAN, J. Joint Statistical Papers. [s.l.]: Cambridge University Press, 1967. Kapitola On the Problem of Two Samples, s. 100. (anglicky)
- NEYMAN, J.; PEARSON, E.S. Joint Statistical Papers. [s.l.]: Cambridge University Press, 1967. Kapitola The testing of statistical hypotheses in relation to probabilities a priori, s. 186–202. (anglicky)
- Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
- P.J. Boxer 1994 Notes on Checkland's Soft Systems Methodology. www.brl.com [online]. [cit. 23-02-2005]. Dostupné v archivu pořízeném dne 23-02-2005.
- www.agnesscott.edu – david
- Ian I. Mitroff and Abraham Silvers, Dirty rotten strategies: How We Trick Ourselves and Others into Solving the Wrong Problems Precisely, Stanford Business Press (2009), hardcover, 210 pages, ISBN 978-0-8047-5996-0
- WILLIAMS, G.O. Iris Recognition Technology [online]. debut.cis.nctu.edu.tw, 1996 [cit. 2010-05-23]. S. 56. Dostupné v archivu pořízeném dne 2011-04-26. (anglicky)
Literatura
- Betz, M.A. & Gabriel, K.R., „Type IV Errors and Analysis of Simple Effects“, Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., „A Power Function for Tests of Randomness in a Sequence of Alternatives“, Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., „False Positives on Newborns' Disease Tests Worry Parents“, Health Day, (5 June 2006). 34471.html
- Kaiser, H.F., „Directional Statistical Decisions“, Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., „Errors of the Third Kind in Statistical Consulting“, Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., „The Interpretation of Significant Interaction“, Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., „Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors“, American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., „On Systemic Problem Solving and the Error of the Third Kind“, Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., „A k-Sample Slippage Test for an Extreme Population“, The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., “Network Security”, Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison-Wesley, (Reading), 1968.
Související články
- statistika
- testování statistických hypotéz – nulová hypotéza
- testování softwaru
Externí odkazy
- (anglicky) Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh