Hašovacia tabuľka
Hašovacia tabuľka alebo hašovacia mapa alebo tabuľka výpočtu adresy transformáciou (kľúča) je v informatike údajová štruktúra, ktorá asociuje kľúče s hodnotami. Primárna efektívne podporovaná operácia je vyhľadávanie: pri zadaní kľúča (napr. meno osoby) nájsť zodpovedajúcu hodnotu (napr. telefónne číslo tejto osoby). Pracuje vďaka transformácii kľúča hašovacou funkciou na haš, číslo, ktoré tabuľka používa na nájdenie požadovanej hodnoty.
Hašovacie tabuľky sa často používajú na implementáciu asociatívnych polí, množín a rýchlych vyrovnávacích pamätí (cache). Rovnako ako polia, hašovacie tabuľky poskytujú vyhľadávanie s konštantným časom O(1) v priemernom prípade, nezávisle od počtu položiek v tabuľke. Ale zriedkavý najhorší prípad môže byť až O (n). V porovnaní s inými údajovými štruktúrami asociatívnych polí sú hašovacie tabuľky najužitočnejšie pre uloženie veľkého množstva údajov.
Hašovacie tabuľky ukladajú údaje na pseudonáhodných miestach, preto prístup k údajom utriedeným spôsobom je veľmi časovo náročná operácia. Iné údajové štruktúry ako samovyvažovacie binárne vyhľadávacie stromy sú vo všeobecnosti oveľa pomalšie (keďže zložitosť vyhľadávania majú O (log n)) a sú skôr zložitejšie na implementáciu ako hašovacie tabuľky, ale udržiavajú si neustále utriedenú štruktúru položiek. Pozri porovnanie hašovacích tabuliek a samovyvažovacích binárnych vyhľadávacích stromov.
Prehľad
Základné operácie, ktoré hašovacie tabuľky vo všeobecnosti podporujú sú:
vlož(kľúč, hodnota)nájdi(kľúč)ktorá vrátihodnotu
Väčšina, ale nie všetky hašovacie tabuľky podporujú zmaž(kľúč). Môžu existovať aj iné služby ako iterovanie tabuľkou, zväčšenie tabuľky, vyprázdnenie tabuľky. Niektoré tabuľky umožňujú uloženie viacerých hodnôt pod rovnakým kľúčom.
Kľúčom môže byť v podstate čokoľvek – číslo, reťazec, objekt; niektoré tabuľky ukladajú dokonca aj odkaz na hodnotu. Jedinou požiadavkou je existencia hašovacej funkcie pre použité kľúče (pozri nižšie).
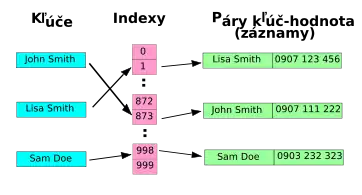
Hašovacie tabuľky používajú pole, ktoré sa tiež niekedy mätúco nazýva hašovacia tabuľka. Každý element poľa môže obsahovať jeden pár kľúč-hodnota nazývaný záznam.
Pretože počet platných kľúčov je zvyčajne oveľa väčší ako rozsah platných indexov do poľa, je potrebné definovať spôsob konverzie každého kľúča na platný index. Toto vykonáva hašovacia funkcia, čo je funkcia, ktorá berie ako argument kľúč a vracia index do poľa. Indexovaný element poľa by zasa mal obsahovať záznam asociovaný s daným kľúčom.
Ale preto, že existuje viac potenciálnych kľúčov ako indexov do poľa, možno dokázať (?Dirichletovym princípom), že dva alebo viac potenciálnych kľúčov budú mať rovnaký haš; toto sa nazýva kolízia. Hašovacia funkcia by mala byť navrhnutá tak, aby minimalizovala množstvo kolízií pre akýkoľvek vrátený index.
Keďže v jednom elemente poľa je možné uložiť iba jednu položku, musí byť použitá stratégia riešenia kolízií. Napríklad sa kolízny záznam uloží do nasledujúceho voľného elementu alebo môžu elementy poľa ukladať spájaný zoznam záznamov.
Hoci sa nejaké kolízie vyskytnú, s dobrými hašovacími funkciami a tabuľkou plnou asi na 80 % budú kolízie relatívne zriedkavé a výkon veľmi dobrý, keďže priemerne sa vykoná veľmi málo porovnaní. Ale ak sa tabuľka príliš zaplní, výkon bude nízky a bude potrebné zväčšiť hašovaciu tabuľku. Zväčšenie tabuľky (Zmena veľkosti tabuľky) znamená, že sa budú musieť znova pridať všetky záznamy.
Väčšina implementácií hašovacích tabuliek nie sú perzistentnými údajovými štruktúrami v zmysle, že neexistuje spôsob ako ich aktualizovať a zároveň si udržať prístup k predchádzajúcej kópii hašovacej tabuľky (hoci sú perzistentné v zmysle uloženia na disku). Niektoré implementácie hašovacích tabuliek ako tie, ktoré používajú VList, sú perzistentné, ale v praxi sa zriedkavo používajú a nie sú také výkonné ako normálne hašovacie tabuľky kvôli zvýšenému času na indexáciu.
Bežné využitie hašovacích tabuliek
Hašovacie tabuľky sa bežne využívajú pre tabuľky symbolov, rýchle vyrovnávacie pamäte a množiny.
Hašovacie tabuľky nie sú vo všeobecnosti perzistentnými údajovými štruktúrami v tom zmysle, že neexistuje jednoduchý a vzhľadom na úložný priestor efektívny spôsob, ako aktualizovať hašovaciu tabuľku a zároveň si udržať prístup k jej predchádzajúcej kópii. Je to však možné implementovaním VListu, čím sa stane perzistentnou, ale nepriaznivo to ovplyvní výkon. hašovacie tabuľky môžu byť „perzistentné“ v inom zmysle – môžu byť uložené na disku. Databázové indexy bežne používajú diskové údajové štruktúry založené na hašovacích tabuľkách.
V počítačovom šachu sa hašovacia tabuľka bežne používa na implementáciu transpozičnej tabuľky.
Voľba dobrej hašovacej funkcie
Dobrá hašovacia funkcia má zásadný vplyv na výkon hašovacej tabuľky. Kolízie hašu sa vo všeobecnosti riešia určitou formou metódy lineárnych pokusov, takže ak hašovacia funkcia zvykne vracať podobné hodnoty, výsledkom bude pomalé vyhľadávanie.
Ideálna hašovacia funkcia by pri každej zmene jednotlivého bitu kľúča (vrátane rozšírenia a skrátenia kľúča) zmenila polovicu bitov hašu a táto zmena by bola nezávislá od zmien spôsobených inými bitmi kľúča. Pretože môže byť ťažké navrhnúť dobrú hašovaciu funkciu, alebo ju výpočtovo náročné vykonávať, boli do veľkej miery skúmané stratégie riešenia kolízií, ktoré zmierňujú dopad slabého hašovacieho výkonu. Ale žiadna z nich nie je taká efektívna ako využitie dobrej hašovacej funkcie.
Je žiadúce používať rovnakú hašovaciu funkciu pre polia akejkoľvek mysliteľnej veľkosti. Aby sme to dosiahli, index do poľa hašovacej tabuľky sa vo všeobecnosti počíta v dvoch krokoch:
- Vypočíta sa všeobecná hodnota hašu, ktorá zaplní veľkosť strojového celého čísla
- Táto hodnota sa redukuje na platný index poľa nájdením jeho modula s ohľadom na veľkosť poľa.
Veľkosti poľa hašovacej tabuľky sa často volia tak, aby boli prvočíslami. Robí sa to, aby sme sa vyhli výskytu spoločných deliteľov hašu a veľkosti tabuľky, ktoré by boli príčinou kolízií po operácii modulo. Ale ani prvočíselná veľkosť tabuľky nie je náhradou za dobrú hašovaciu funkciu.
Bežnou alternatívou k prvočíselným veľkostiam je použitie veľkosti, ktorá je mocninou čísla dva a dosahovať operáciu modulo maskovaním bitov. Maskovanie bitov býva výpočtovo významne rýchlejšie ako operácia delenia. V každom prípade je dobrý nápad zariadiť, aby všeobecná hodnota hašu bola zostavená pomocou prvočísel, ktoré nezdieľajú spoločných deliteľov (napr. ako coprime) s dĺžkou tabuľky.
Prekvapivo bežným problémom, ktorý sa môže vyskytnúť pri hašovaní je klastrovanie. Klastrovanie sa vyskytuje, keď štruktúra hašovacej funkcie spôsobuje, že bežne používané kľúče padajú blízko vedľa seba alebo dokonca po sebe do hašovacej tabuľky. To môže spôsobiť významné zníženie výkonu ako sa tabuľka plní a používajú sa isté stratégie riešenia kolízií ako lineárne reťazenie.
Počas debugovania obsluhy kolízií v hašovacej tabuľke je niekedy užitočné použiť hašovacu funkciu, ktorá vždy vracia konštantnú hodnotu, napr. 1, ktorá spôsobí kolíziu po takmer každom vložení.
V prostrediach, kde sa záškodník môže pokúšať spomaliť algoritmus tým, že zadáva nepriaznivý vstup, býva dobrým riešením univerzálne hašovanie, schéma, kde náhodne volíme hašovaciu funkciu na začiatku algoritmu. Pretože záškodník nebude vedieť, akú hašovaciu funkciu používame, nebude vedieť určiť, ktorý vstup je nepriaznivý.
Riešenie kolízií
Ak hašovacia funkcia vráti pre dva rôzne kľúče rovnaký index, zodpovedajúce záznamy nemožno uložiť na to isté miesto. Keďže je už obsadené, musíme nájsť iné miesto pre uloženie záznamu a zabezpečiť, aby sme ho našli, keď ho neskôr vyhľadáme.
Pre predstavu dobrej stratégie riešenia kolízií si predstavte nasledovný výsledok odvodený použitím narodeninového paradoxu. Aj za predpokladu, že naša hašovacia funkcia vracia indexy rovnomerne rozložené v poli aj pre pole s 1 miliónom záznamov, existuje 95% pravdepodobnosť aspoň jednej kolízie predtým, ako bude obsahovať 2 500 záznamov.
Existuje niekoľko techník riešenia kolízií, ale najpoužívanejšími sú reťazenie a otvorené adresovanie. Súhrnný prehľad vypracoval Morris v roku 1968.
Na rozptyľovanie záznamov v tabuľke, aby sa zabránilo kolíziám, môže slúžiť generátor krížových odkazov.
Reťazenie
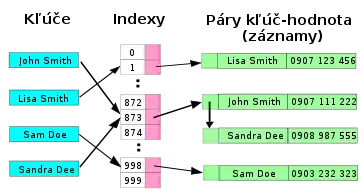
V najjednoduchšej technike zreťazenej hašovacej tabuľky každé miesto v poli odkazuje na zreťazený zoznam vložených záznamov, pre ktoré hašovanie kľúča koliduje na rovnakú hodnotu. Pre vloženie je potrebné nájsť správne miesto a pridať ho na jeden koniec; pre mazanie je potrebné prehľadávanie zoznamu a odstránenie.
Zreťazené hašovacie tabuľky majú výhodu v porovnaní s tabuľkami s otvorenou adresáciou, že operácia odstránenia je jednoduchá a zmenu veľkosti tabuľky je možné odkladať oveľa dlhšie, pretože výkon sa znižuje oveľa pomalšie aj ak je miesto obsadené. Vlastne mnohé zreťazené hašovacie tabuľky nepotrebujú zmenu veľkosti vôbec, pretože degradácia výkonu je lineárna so zapĺňaním tabuľky. Napríklad zreťazená hašovacia tabuľka obsahujúca dvojnásobok odporúčanej dátovej kapacity by bola priemerne iba asi dvakrát pomalšia ako rovnaká tabuľka s odporúčanou kapacitou (za podmienky dobrej distribúcie kľúčov).
Zreťazené hašovacie tabuľky dedia nevýhody spojových zoznamov. Ak sa ukladajú malé záznamy, režijné náklady spojového zoznamu môžu byť významné. Ďalšou nevýhodou je, že prechádzanie spojovým zoznamom má nízky cache výkon.
Namiesto zoznamov je možné pre reťazenie použiť alternatívne údajové štruktúry. Napríklad použitím samovyvažovacieho stromu je možné znížiť teoretický čas najhoršieho prípadu z O(n) na O(log n). Ale preto, že každý zoznam by mal byť krátky, tento prístup zvyčajne nevedie k zvýšeniu výkonu, iba ak by bola tabuľka navrhnutá na fungovanie pri plnej kapacite alebo vykazovala nezvyčajne vysoké množsto kolízií. Je tiež možné použiť dynamické polia pre zníženie režijných nákladov a zvýšenie výkonnosti cache pri malých záznamoch.
Niektoré implementácie reťazenia používajú optimalizáciu pri uložení prvého záznamu každej reťaze v tabuľke. Hoci to môže zvýšiť výkon, vo všeobecnosti sa to neodporúča: zreťazené tabuľky s rozumnými hodnotami zaťaženia obsahujú veľký pomer voľného miesta a viac miesta spôsobuje väčšie mrhanie pamäťou.
Otvorené adresovanie
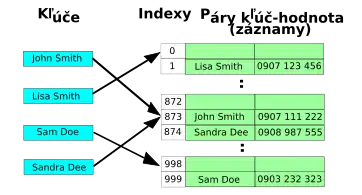
Hašovacie tabuľky s otvoreným adresovaním môžu ukladať záznamy priamo v poli. Kolízia hašu sa rieši skúšaním – prehľadávaním alternatívnych miest v poli (skúšacia sekvencia), pokým sa buď nenájde cieľový záznam alebo voľné miesto, čo indikuje, že sa v tabuľke daný kľúč nenachádza. Medzi známe sekvencie pokusov patria:
- lineárne pokusy
- v ktorom je interval medzi skúškami fixný -- často 1,
- kvadratické pokusy
- v ktorom interval medzi skúškami rastie lineárne (takže indexy sú opísané kvadratickou funkciou),
- dvojité hašovanie
- v ktorom je interval medzi skúškami fixný pre každý záznam, ale počíta sa inou hašovacou funkciou
Hlavné rozdiely medzi týmito metódami sú, že metóda lineárnych pokusov má najlepší cache výkon ale je najcitlivejšia na klastrovanie, kým dvojité hašovanie má nízky cache výkon ale nevykazuje v podstate žiadne klastrovanie (môže vyžadovať viac výpočtov ako iné formy hašovania); kvadratické hašovanie spadá v oboch oblastiach do stredu.
Pri kvadratickom hašovaní môže vzniknúť situácia, že sa pri pridávní prvkov nenájde voľné miesto, hoci v tabuľke existuje. Pri prvočíselnej veľkosti N tabuľky sa však prehľadá aspoň N/2 záznamov, takže táto nevýhoda sa prejaví iba v prípade, že je tabuľka takmer plná.
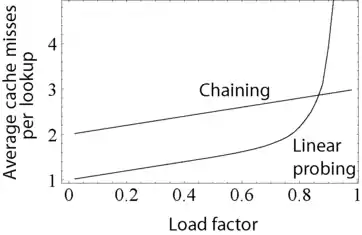
Kritický vplyv na výkon hašovacej tabuľky s otvoreným adresovaním má koeficient zaťaženia; pomer miest v poli, ktoré sa používajú. Ako sa zaťaženie zvyšuje k 100 %, stúpa dramaticky aj počet skúšok, ktoré môžu byť potrebné na nájdenie alebo vloženie daného kľúča. Keď sa tabuľka zaplní, skúšacie algoritmy dokonca nemusia skončiť. Aj s dobrou hašovacou funkciou je koeficient zaťaženia zvyčajne obmedzený na 80 %. Nevhodná hašovacia funkcia môže vykazovať nízky výkon aj pri nízkych zaťaženiach tým, že spôsobuje výrazné klastrovanie. Čo spôsobuje, že hašovacie funkcie klastrujú nie je dobre známe a je ľahké neúmyselne napísať hašovaciu funkciu, ktorá spôsobuje ťažké klastrovanie.
Otvorené adresovanie verzus reťazenie
Zreťazené hašovacie tabuľky majú v porovnaní s otvoreným adresovaním nasledujúce výhody:
- Dajú sa jednoducho implementovať s pomocou iba základných údajových štruktúr
- Z pohľadu písania vhodných hašovacích funkcií sú zreťazené hašovacie tabuľky necitlivé na klastrovanie a majú iba minimum kolízií. Otvorené adresovanie závisí na lepších hašovacích funkciách, aby sa zabránilo klastrovaniu. Toto je obzvlášť dôležité, ak programátori začiatočníci môžu pridať svoje vlastné hašovacie funkcie. Ale aj skúsení programátori môžu byť prekvapení nečakaným klastrovacím účinkom.
- Jemnejšie sa degraduje ich výkon. Hoci sa reťaze predlžujú so zaplňovaním tabuľky, zreťazená hašovacia tabuľka sa nemôže „zaplniť“ a nevykazuje náhle zvýšenia vyhľadávacích časov pri takmer zaplnenej tabuľke s otvoreným adresovaním (pozri vpravo).
- Ak hašovacia tabuľka ukladá veľké záznamy, asi 5 alebo viac slov na záznam, reťazenie vyžaduje menej pamäte ako otvorené adresovanie.
- Ak je hašovacia tabuľka riedka (t. j. veľké pole s mnohými voľnými miestami), reťazenie používa menej pamäte ako otvorené adresovanie už aj pre malé záznamy 2 – 4 slová na záznam kvôli vnútornému spôsobu uloženia.
Pre malé veľkosti záznamu (niekoľko slov a menej) sú výhody otvoreného adresovania oproti reťazeniu nasledovné:
- Môže byť priestorovo efektívnejšie ako reťazenie, pretože nie je potrebné ukladať žiadne pointre alebo alokovať ďalšie miesto mimo hašovacej tabuľky. Jednoduché spojové zoznamy potrebujú navyše jedno slovo na každý záznam.
- Vkladania nemajú pokutu za alokáciu pamäte a dajú sa implementovať dokonca bez použitia alokátora pamäte.
- Pretože používa vnútorné ukladanie, vyhýba sa otvorené adresovanie ďalšej referencii, ktorú potrebuje externé uloženie pri reťaziach. Má tiež lepšiu lokalitu referencie, obzvlášť pri lineárnych pokusoch. Pri malých veľkostiach záznamov prinášajú tieto činitele lepší výkon v porovnaní s reťazením, obzvlášť pri vyhľadávaní.
- Je možné ich jednoduchšie serializovať, pretože nepoužívajú pointre.
Na druhej strane je normálne otvorené adresovanie zlá voľba pri veľkej veľkosti prvku, keďže tieto prvky zaplnia celé riadky cache (čím sa neguje výhoda cache) a na veľké prázdne miesta v tabuľke sa mrhá miestom. Ak tabuľka s otvoreným adresovaním ukladá iba referencie na prvky (externé uloženie), používa miesto porovnateľné s reťazením aj pri veľkých záznamoch, ale stráca výhodu rýchlosti.
Vo všeobecnosti je otvorené adresovanie lepšie použiť pre tabuľky s malými záznamami, ktoré je možné uložiť v rámci tabuľky (vnútorné uloženie) a ktoré sa vojdú do riadka cache. Sú obzvlášť vhodné pre elementy s dĺžkou jedno slovo alebo menej. V prípadoch, kedy sa očakáva vyšší koeficient zaťaženia tabuľky, záznamy sú veľké alebo s premenlivou dĺžkou, dosahujú často rovnako dobrý alebo lepší výkon zreťazené hašovacie tabuľky.
Nakoniec, pri rozumnom použití je zvyčajne každý algoritmus hašovacej tabuľky dostatočne rýchly; a pomer strojového času stráveného v kóde hašovacej tabuľky je nízky. Použité množstvo pamäte sa zriedka považuje za nadbytočné. Preto vo väčšine prípadov sú rozdiely medzi týmito algoritmami hraničné a prihliada sa na iné kritériá.
Zjednotené hašovanie
Hybrid zreťazeného a otvoreného adresovania – zjednotené hašovanie – spája reťaze uzlov v rámci samotnej tabuľky. Ako otvorené adresovanie dosahuje využitie priestoru a (o niečo zmenšené) výhody cacheovania v porovnaní s reťazením. Ako reťazenie nevykazuje klastrovanie; v skutočnosti je možné zaplniť tabuľku efektívne do vysokej hustoty. Na rozdiel od reťazenia nemôže mať viac prvkov ako má tabuľka miest.
Dokonalé hašovanie
Ak sú dopredu známe všetky kľúče, ktoré sa budú používať, je možné použiť dokonalé hašovanie na vytvorenie dokonalej hašovacej tabuľky, v ktorej nebudú nastávať kolízie. Pri použití minimálneho dokonalého hašovania je možné tiež použiť každé miesto v hašovacej tabuľke.
Pravdepodobnostné hašovanie
Snáď najjednoduchším riešením kolízie je vymeniť hodnotu, ktorá sa už na danom mieste nachádza za novú hodnotu, alebo o niečo menej bežne, vyhodiť záznam, ktorý sa má vložiť. V neskorších vyhľadávaniach to môže viesť k nenájdenému záznamu. Táto metóda je obzvlášť užitočná pre implementáciu cacheovania.
Ešte efektívnejším (vzhľadom na úložný priestor) je podobné riešenie, ktoré si necháva zakaždým iba jeden bit indikujúci, či na toto miesto bola alebo nebola vložená hodnota. False negatives cannot occur, but false positives can, pretože keď sa pri hľadaní nájde bit nastavený na jednotku, tvrdí iba, že hodnota bola nájdená, aj keď je to iba ďalšia hodnota náhodou hašovaná na rovnaké miesto. V skutočnosti je takáto hašovacia tabuľka špecifickým typom Bloomovho filtra.
Zmena veľkosti tabuľky
S dobrou hašovacou funkciou môže hašovacia tabuľka obsahovať zvyčajne asi 70 – 80 % prvkov z celkového množstva voľných miest. V závislosti na mechanizme riešenia kolízií môže začať výkon trpieť buď postupne alebo naraz. Aby sme zamedzili tejto degradácii, potom ako koeficient zaťaženia prekročí určitú prahovú hodnotu, alokujeme novú, väčšiu tabuľku a pridáme do nej obsah pôvodnej tabuľky. Napríklad v Jave v triede HashMap je predvolená prahová hodnota koeficientu zaťaženia 0,75 %.
Toto môže byť veľmi drahá operácia a to, že je potrebná, je jednou z nevýhod hašovacej tabuľky. V skutočnosti niektoré zle implementované metódy ako zväčšovanie tabuľky po každom pridaní prvku redukujú výkon natoľko, že maria zmysel hašovacej tabuľky. Ak však zväčšujeme tabuľku o nejakú pevne danú veľkosť ako 10 % alebo 100 %, je pomocou amortizovanej analýzy možné ukázať, že tieto zmeny veľkosti sú také zriedkavé, že priemerný vyhľadávací čas zostáva konštantný. Na dôkaz uvažujme hašovaciu tabuľku so zreťazením začínajúcu na minimálnej veľkosti 1, ktorej veľkosť zdvojnásobíme zakaždým, keď sa zaplní na 100 %. Ak na konci obsahuje n prvkov, celkový počet operácií pridania pre všetky zmeny veľkosti je
- 1 + 2 + 4 + ... + n = 2n - 1
Pretože náklady na zmenu veľkosti tvoria geometrický rad, celkové náklady sú O(n). Ale predovšetkým tiež vykonávame n operácií na pridanie n prvkov, takže celkový čas pridania n prvkov je O(n), amortizovaný čas O(1) na každý prvok. Na druhej strane, niektoré implementácie hašovacej tabuľky, obzvlášť v systémoch pre výpočty v reálnom čase, si nemôžu dovoliť cenu operácie zmeny veľkosti hašovacej tabuľky naraz, pretože by mohla prerušiť operácie s vysokou prioritou. Jedným jednoduchým prístupom je na začiatku alokovať hašovaciu tabuľku miestom pre očakávaný počet prvkov a zamedziť pridaniu príliš veľkého počtu prvkov. Inou užitočnou metódou, ktorá je však náročná na pamäť, je postupná zmena veľkosti:
- Alokovať novú hašovaciu tabuľku, ale ponechať si starú a počas vyhľadávania kontrolovať obe
- Pri každom vkladaní pridať prvok do novej tabuľky a zároveň presunúť k prvkov zo starej tabuľky do novej tabuľky
- Po odstránení všetkých prvkov zo starej tabuľky sa táto dealokuje
Aby sa zabezpečilo, že stará tabuľka sa kompletne prekopíruje predtým, ako sa nová zaplní, je potrebné zväčšiť veľkosť tabuľky aspoň o (k + 1)/k.
Iným spôsobom zníženia nákladov na zmenu veľkosti tabuľky je zvoliť si hašovaciu funkciu tak, aby sa väčšina hodnôt nezmenila po zmene veľkosti tabuľky. Tento prístup zvaný konzistentné hašovanie prevažuje v diskových distribuovaných hašoch, kde je zmena veľkosti príliš nákladná.
Príklady v pseudokóde
Nasledujúci pseudokód je implementáciou hašovacej tabuľky s otvoreným adresovaním a metódou lineárnych pokusov s posunom o jedno miesto, bežný postup, ktorý je účinný pri dobrej hašovacej funkcii. Každá z funkcií vyhľadanie, nastavenie a odstránenie používa spoločnú internú funkciu nájdiMiesto, ktorá vyhľadá miesto v poli, ktoré obsahuje alebo by malo obsahovať daný kľúč.
záznam pár { kľúč, hodnota }
premenná pár pole miesto[0..početMiest-1]
funkcia nájdiMiesto(kľúč) {
i := haš(kľúč) modulus početMiest
opakuj {
ak miesto[i] nie je obsadené alebo miesto[i].kľúč = kľúč
vráť i
i := (i + 1) modulus početMiest
}
}
funkcia vyhľadaj(kľúč)
i := nájdiMiesto(kľúč)
ak miesto[i] je obsadené // kľúč je v tabuľke
vráť miesto[i].hodnota
inak // kľúč nie je v tabuľke
vráť nenájdený
funkcia nastav(kľúč, hodnota) {
i := nájdiMiesto(kľúč)
ak miesto[i] je obsadené
miesto[i].hodnota := hodnota
inak {
ak tabuľka je takmer zaplnená {
zväčši tabuľku (pozn. 1)
i := nájdiMiesto(kľúč)
}
miesto[i].kľúč := kľúč
miesto[i].hodnota := hodnota
}
}
- pozn. 1
- Zmena veľkosti tabuľky vyžaduje alokovanie väčšieho poľa a rekurzívne použitie operácie nastav na vloženie všetkých prvkov starého poľa do nového, väčšieho poľa. Je bežné zväčšiť veľkosť poľa exponenciálne, napríklad zdvojnásobením veľkosti starého poľa.
funkcia odstráň(kľúč)
i := nájdiMiesto(kľúč)
if miesto[i] je voľné
vráť // kľúč nie je v tabuľke
j := i
opakuj
j := (j+1) modulus početMiest
if miesto[j] je voľné
koniec slučky
k := haš(miesto[j].kľúč) modulus početMiest
ak (j > i a (k ≤ i or k > j)) alebo
(j < i a (k ≤ i a k > j)) (pozn. 2)
miesto[i] := miesto[j]
i := j
označ miesto[i] ako voľné
- pozn. 2
- Pre všetky záznamy v klastri platí, že nesmie existovať prázdne miesto medzi ich prirodzenou haš polohou a ich aktuálnou polohou (inak by sa vyhľadanie skončilo pred nájdením záznamu). Na tomto mieste v pseudokóde je i prázdne miesto, ktoré ruší platnosť tejto vlastnosti pre nasledujúce záznamy v klastri. j je pre nasledujúci záznam. k je samotný neupravený haš, kde by záznam j prirodzene pristál v hašovacej tabuľke, ak by nenastali kolízie. Tento test zisťuje, či záznam na j je teraz neplatne umiestnený vzhľadom na požadované vlastnosti klastra, keďže záznam i je prázdny.
Inou metódou odstránenia je jednoducho označiť dané miesto ako zmazané. To však vyžaduje prebudovanie tabuľky jednoducho na odstránenie zmazaných záznamov. Už uvedené metódy majú zložitosť O(1) pre aktualizáciu a odstraňovanie existujúcich záznamov s prípadným prebudovaním ak sa tabuľka blíži zaplneniu.
Už uvedená metóda odstránenia s O(1) je iba možná v hašovacej tabuľke s otvoreným adresovaním a metódou lineárnych pokusov. V prípade, kedy sa má naraz zo systému vymazať väčšie množstvo záznamov môže byť výkonnejšie označenie záznamov na zmazanie a prebudovanie.
Problémy hašovacích tabuliek
Hoci hašovacie tabuľky potrebujú na vyhľadanie v priemere konštantný čas, skutočne strávený čas môže byť významný. Vyhodnotenie dobrej hašovacej funkcie môže byť pomalá operácia. Obzvlášť v prípadoch, kde je možné použiť jednoduché indexované pole, je to zvyčajne rýchlejšie.
Hašovacie tabuľky vo všeobecnosti vykazujú zlú lokalitu referencie –- t. j. údaje, ku ktorým pristupujeme sú zdanlivo náhodne rozložené v pamäti. Pretože hašovacie tabuľky používajú prístupové vzory, ktoré skáču z miesta na miesto, môže to spôsobovať cache misses procesora a tým veľmi zdržovať (pozri cache CPU). Kompaktné údajové štruktúry ako polia, ktoré sa prehľadávajú lineárne, môžu byť rýchlejšie, ak je tabuľka pomerne malá a porovnanie kľúčov je lacná operácia ako pri celých číslach. Podľa Moorovho zákona sa veľkosti cache zväčšujú exponenciálne, takže veľkosť „malej tabuľky“ sa môže časom zväčšovať. Hranica optimálneho výkonu sa mení od systému k systému; napríklad test na Parrote ukazuje, že jeho hašovacie tabuľky sú výkonnejšie ako lineárne pokusy vo všetkých okrem najtriviálnejších prípadov (jeden až tri záznamy).
Významnejšie je, že hašovacie tabuľky sú náročnejšie na implementáciu a používanie. Hašovacie tabuľky závisia na návrhu efektívnej hašovacej funkcie pre každý typ kľúča, ktorú je zvyčajne ťažšie navrhnúť a zdĺhavejšie testovať ako čistú funkciu porovnania, ktorú vyžadujú samovyvažovacie binárne vyhľadávacie stromy. V tabuľkách s otvoreným adresovaním je ešte jednoduchšie navrhnúť zlú hašovaciu funkciu.
Navyše v niektorých aplikáciách môže útočník, ktorý pozná hašovaciu funkciu, zámerne dodávať informácie, ktoré spôsobujú najhorší prípad kvôli nadmerným kolíziám, čo sa odrazí na slabom výkone (napr. DoS útok). V kritických aplikáciách môže byť výhodnejšia štruktúra s lepšou zárukou pre najhorší prípad. Pozri aj Crosby a Wallach: Denial of Service via Algorithmic Complexity Attacks.
Implementácie
Kým mnohé programovacie jazyky už poskytujú funkcionalitu hašovacích tabuliek, exituje niekoľko nezávislých implementácií hodných spomenutia:
- Projekt Google Sparse Hash obsahuje niekoľko implementácií hašovacích máp, ktoré používa Google, s rôznymi výkonnostnými charakteristikami vrátane implementácie optimalizujúcej využitie miesta (iba 2 bity na záznam) a optimalizácie na rýchlosť.
- Množstvo štandardných a/alebo runtime knižníc programovacích jazykov používajú hašovacie tabuľky na implementáciu asociatívnych polí kvôli ich výkonnosti.
Pozri aj
- Bloomov filter
- Distribuovaná hašovacia tabuľka
- Hašovacia funkcia
- Rabin-Karpov algoritmus
- Hašovací zoznam
- Hašovací strom
- Trie
Externé odkazy
- NIST entry on hash tables
- Open addressing hash table removal algorithm from ICI programming language, ici_set_unassign in set.c (and other occurrences, with permission).
- The Perl Wikibook – Perl Hash Variables
Referencie
- Wirth, N.: Algoritmy a štruktúry údajov. Bratislava, Alfa 1989
- Donald Knuth. The Art of Computer Programming, Volume 3: Sorting and Searching, Third Edition. Addison-Wesley, 1997. ISBN 0-201-89685-0. Section 6.4: Hashing, pp. 513–558.
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Chapter 11: Hash Tables, pp. 221–252.
- Michael T. Goodrich and Roberto Tamassia. Data Structures and Algorithms in Java, 4th edition. John Wiley & Sons, Inc. ISBN 0-471-73884-0. Chapter 9: Maps and Dictionaries. pp. 369–418
Poznámky pod čiarou
^ Morris, R.: Scatter Storage Techniques. , Comm. ACM 1968, s. 38-34
Zdroje
Tento článok je čiastočný alebo úplný preklad článku Hash table na anglickej Wikipédii.