Rýchla vyrovnávacia pamäť procesora
Rýchla vyrovnávacia pamäť procesora je rýchla vyrovnávacia pamäť (skratka: RVP; angl. cache) používaná procesorom počítača na zníženie priemernej doby prístupu do hlavnej pamäte. Vyrovnávacia pamäť je menšia a rýchlejšia pamäť, ktorá ukladá kópie najčastejšie používaných dát hlavnej pamäte. V prípade, že sa častejšie využívajú kópie dát z vyrovnávacej pamäte procesora ako z hlavnej pamäte, je priemerná latencia pamäťového prístupu bližšia latencii vyrovnávajúcej pamäte ako latencii hlavnej pamäte.
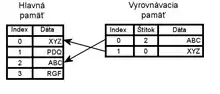
Diagram napravo zobrazuje dve pamäte – hlavnú pamäť a rýchlu vyrovnávaciu pamäť. V oboch má každé pamäťové miesto priradenú hodnotu (riadok rýchlej vyrovnávacej pamäte, angl. cache line), ktorej veľkosť sa pohybuje podľa rôznych konštrukčných návrhov od 8 do 512 bajtov. Veľkosť riadku RVP je zvyčajne väčšia ako veľkosť bežného prístupu, ktorý sa pohybuje od 1 do 16 bajtov. Každé pamäťové miesto v oboch pamätiach má index – jedinečné číslo určené na označenie tohto miesta. Index pamäťového miesta v hlavnej pamäti sa nazýva adresa. Každé miesto v rýchlej vyrovnávacej pamäti má navyše štítok, ktorý obsahuje index hodnoty hlavnej pamäte, ktorá bola uložená v RVP. V rýchlej vyrovnávacej pamäti procesora sú tieto záznamy nazývané riadkami alebo blokmi RVP.
Keď chce procesor čítať alebo zapisovať na pamäťové miesto v hlavnej pamäti, najprv skontroluje, či je dané pamäťové miesto v cache. To sa dosiahne porovnaním adresy pamäťového miesta so všetkými štítkami v cache, ktoré môžu danú adresu obsahovať. Ak procesor nájde dané pamäťové miesto v cache, hovoríme tomu cache hit, inak hovoríme o cache miss. Po zistení, že sa požadované dáta nachádzajú vo vyrovnávacej pamäti je ešte potrebné overiť ich platnosť, ktorú udáva tzv. valid bit. V prípade cache hitu procesor okamžite prečíta, alebo zapíše údaje do cache line. Pomer prístupov, ktorých výsledkom bol cache hit ku cache miss, nazývame hit rate a je meradlom efektívnosti cache.
V prípade cache miss, väčšina druhov cache alokuje nový záznam, ktorý obsahuje práve zmeškaný tag a kópiu dát z pamäte. Potom je možné sa odkázať na nový záznam ako v prípade cache hit. Cache miss je pomalý, pretože je potrebné preniesť dáta z hlavnej pamäte. Tento prenos spôsobuje zdržanie preto, že hlavná pamäť je omnoho pomalšia ako cache pamäť.
Niektoré detaily fungovania
Aby sa vytvorilo miesto pre nový záznam v prípade cache miss, cache musí vo všeobecnosti "vyhodiť" jeden z existujúcich záznamov. Heuristika, ktorú na to používa na toto vyhodenie, sa nazýva politika nahrádzania (angl. replacement policy). Fundamentálny problém každej politiky nahrádzania je predpovedať, ktorý existujúci záznam v cache bude v budúcnosti použitý s najmenšou pravdepodobnosťou. Predpovedanie budúcnosti je náročné, obzvlášť pre hardvérové cache, ktoré musia byť implementované obvodmi, takže existuje množstvo politík nahrádzania a žiaden dokonalý spôsob, ako medzi nimi vybrať. Jedna z populárnych politík nahrádzania, LRU (Least Recently Used), nahrádza najdlhšie nepoužitý záznam.
Keď sa dáta zapíšu do cache, je tiež potrebné ich niekedy zapísať do hlavnej pamäte. Časovanie tohto zápisu sa riadi tzv. politikou zapisovania (write policy). Vo write-through cache spôsobí každý zápis do cache zápis do hlavnej pamäte. Vo write-back cache sa zápisy nezrkadlia v pamäti okamžite. Namiesto toho sa cache sleduje, ktorých miesta sa prepísali (tieto miesta sa označia ako špinavé - príznak dirty bit). Dáta z týchto miest sa zapíšu do hlavnej pamäte, keď sa dáta vyhadzujú z cache. Z tohto dôvodu cache miss vo write-back cache často bude vyžadovať dva prístupy do pamäte.
Sú aj kompromisné politiky. Cache môže byť write-through, ale zápisy sa môžu v zápisovom fronte držať dočasne, zvyčajne tak, aby sa viacnásobné zápisy vykonali súčasne (čo môže zlepšiť využitie zbernice).
Dáta v hlavnej pamäti, ktoré sú cacheované môžu byť časom nahradené inými entitami, čo znamená, že dáta v cache "vychladli" (angl. out-of-date alebo stale). A zasa keď CPU aktualizuje dáta v cache, kópie týchto dát v iných cache vychladnú. Komunikačné protokoly medzi správcami cache, ktoré slúžia na udržiavanie konzistencie dát sa nazývajú koherenčné protokoly.
Záleží aj na čase, ktorý je potrebný na prinesenie dáta z pamäte (latencia čítania), pretože CPU často počas čakania na dáta nebude mať čo robiť. Tento stav CPU sa nazýva stall. Ako sa novšie CPU neustále zrýchľujú, stalls z dôvodu cache miss predstavujú stále väčšie straty výpočtového potenciálu; moderné CPU sú schopné vykonať stovky inštrukcií v čase, ktorý je potrebný na prinesenie jediného dáta z pamäte. Na zamestnanie CPU v tomto čase boli vyvinuté rozličné techniky. CPU s Out-of-order (napr. Pentium Pro a novšie návrhy od Intelu) sa pokúšajú vykonávať nezávislé inštrukcie nasledujúce po inštrukcii, ktorá čaká na cache miss dáta. Pentium 4 používa simultánny multithreading (v terminológii Intelu Hyper Threading), aby dovolil druhému programu používať CPU kým prvý čaká na dáta z hlavnej pamäte..
Asociativita
Takže politika nahrádzania rozhoduje, kde do cache sa uloží kópia určitého záznamu z hlavnej pamäte. Ak necháme voľbu, do ktorého záznamu cache sa kópia uloží, na politike nahrádzania, nazývame takúto cache plne asociatívna (fully associative). Opačným extrémom je, keď každý záznam z hlavnej pamäte môže ísť iba na jediné miesto v cache—cache sa mapuje priamo (direct mapped). Mnohé cache implementujú kompromis a označujú sa ako množinovo asociatívne (set associative). Napríklad dátová cache prvej úrovne (L1) v AMD Athlon je dvojcestne množinovo asociatívna (2-way set associative), čo znamená, že každý záznam z hlavnej pamäte môže byť cacheovaný v ktoromkoľvek z dvoch miest v dátovej cache prvej úrovne.
Ak každá z adries v hlavnej pamäti môže byť cacheovaná na dvoch adresách v cache, logickou otázkou je na ktorých dvoch? Najjednoduchšia a najbežnejšia schéma, zobrazená na diagrame vpravo hore, je použiť najnižšie bity indexu adresy hlavnej pamäte ako index do cache pamäte a mať dvojcestné záznamy pre každý index. Dobrou vlastnosťou tejto schémy je, že štítky uložené v cache nemusia obsahovať časť adresy hlavnej pamäte, ktorá je špecifikovaná indexom cache. Keďže štítky cache majú menej bitov, zaberajú menej miesta a je možné ich rýchlejšie čítať a porovnávať.
Boli navrhnuté aj iné schémy ako skewed cache, kde je index pre cestu 0 priamy, ale index pre cestu 1 je daný hash funkciou. Dobrá hash funkcia má vlastnosť, že adresy, ktoré sú v konflikte s priamym mapovaním nie s v konflikte s hash funkciou, a tak je menej pravdepodobné, že program bude trpieť neočakávaným množstvom konfliktných cache misses z dôvodu patologického prístupového vzoru.
Asociativita je obetovaním niečoho na úkor niečoho iného. Ak je desať miest, kde politika nahrádzania môže umiestniť nový záznam, potom ak sa kontroluje, či záznam je v cache, je potrebné skontrolovať všetkých desať miest. Kontrola viacerých miesť stojí výpočtový výkon, pamäťové miesto a strojový čas. Na druhej strane cache s väčšou asociativitou trpia menej cache missess (pozri konfliktné cache missess dolu). Základným pravidlom je, že zdvojenie asociativity má približne rovnaký efekt na hit rate ako zdvojenie kapacity cache, od jednocestnej (priamo mapovanej) po štvorcestnú. Zvýšenie asociativity nad štvorcestnú má omnoho menší dopad na hit rate a vo všeobecnosti sa robí z iných dôvodov (pozri virtual aliasing dolu).
Jednou z výhod priamo mapovanej cache je, že umožňuje jednoduché a rýchle špekulácie. Keď sa raz vypočíta adresa, cache index, ktorý mohol byť kópiou údaju je známy. Je možné tento záznam cache prečítať a procesor môže pokračovať v práci s údajom predtým, než sa skončí kontrola, či sa štítok v skutočnosti zhoduje s požadovanou adresou.
Princíp, že procesor môže používať cacheované dáta predtým ako sa skončí kontrola zhodnosti štítku, je možné aplikovať aj na asociatívne cache. Podmnožinu štítku zvanú pomôcka (hint), je možné použiť paralelne s kontrolou celého štítku. Technika pomôcky funguje najlepšie, keď sa používa v kontexte prekladu adresy tak, ako je vysvetlené nižšie.
Povinné, kapacitné a konfliktné cache misses
Bolo vykonané množstvo analýz správania cache za účelom nájdenia najlepšej veľkosti, asociativity, veľkosti bloku atď. Sekvencie pamäťových referencií produkovaných benchmarkovými programami sa ukladajú ako address traces. Následné analýzy simulujú množstvo rôznych možných návrhov cache na týchto dlhých address traces. Zisťovanie toho, do akej miery toto množstvo premenných ovplyvňuje hit rate môže byť veľmi mätúce. Jedným z významných prispievateľov tejto analýzy je Mark Hill, ktorý rozdelil cache misses do troch kategórií:
- Povinné cache misses sú tie, ktoré sú spôsobené referenciou na údaj. Veľkosť cache a asociativita neovplyvnia množstvo povinných cache misses. Prefetching ako aj veľkosť blokov (čo je forma prefetchingu) môžu pomôcť.
- Kapacitné cache misses sú tie, ktorými bude trpieť cache danej veľkosti nezávisle od asociativity či veľkosti bloku. Krivka kapacitnej miss rate verzus veľkosť cache dáva určitú predstavu o lokalite určitého referenčného toku.
- Konfliktné cache misses sú tie, ktorým sa dalo vyhnúť, keby nebola cache vyhodila záznam skôr. Konfliktné cache misses sa dajú ďalej rozdeliť na mapping misses, ktoré sú pri danej asociativite nevyhnutné, a replacement misses, ktoré sú spôsobené danými príležitostnými nákladmi politiky nahrádzania.

Graf vpravo sumarizuje výkon cache na celočíselnej časti benchmarkov SPEC CPU2000, ako ich namerali Hill a Cantin . Tieto benchmarky majú reprezentovať druh záťaže, ktorý môže mať pracovná stanica v danom dni. Na tomto grafe môžeme vidieť rozličné vplyvy troch druhov cache misses.
Ďalej napravo pri veľkosti cache označenej ako "Inf", máme povinné cache misses. Ak chceme zlepšiť výkon stroja pri SpecInt2000, zväčšenie veľkosti cache nad 1MB je zbytočné. Taký pohľad nám dávajú povinné cache misses.
Miss rate plne asociatívnej cache je tu takmer reprezentatívnym príkladom kapacitnej miss rate. Rozdiel je, že prezentované údaje sú zo simulácií používajúcich politiku nahrádzania LRU. Zobrazenie kapacitnej miss rate by vyžadovalo dokonalú politiku nahrádzania, t. j. predvídanie budúcnosti a nájdenie záznamu cache, ktorý nebude potrebný.
Všimnite si, že naša aproximácia kapacitnej miss rate strmo klesá medzi 32 KB a 64KB. To indikuje, že benchmark používa pracovnú vzorku s veľkosťou približne 64KB. Návrhár cache CPU skúmajúci tento benchmark bude mať silné nutkanie nastaviť veľkosť cache skôr nad 64KB ako pod túto veľkosť. Všimnite si, že pri tomto benchmarku nemôže žiadna zmena asociativity pomôcť 32KB cache k rovnako dobrým výsledkom ako má štvorcestná 64KB cache či priamo mapovaná 128KB cache.
Nakoniec si všimnite, že medzi 64KB a 1MB je veľký rozdiel medzi priamo mapovanými a plne asociatívnymi cache. Tento rozdiel je konfliktná miss rate. V roku 2004 sú sekundárne cache v rámci čipu v tomto rozsahu, pretože menšie cache sú dostatočne rýchle na to, aby boli primárnymi cache a väčšie cache sú príliš veľké na to, aby ich bolo možné ekonomicky produkovať na čipe (Itanium 2 má 9MB level-3 cache na čipe, najväčšiu aká sa predáva v roku 2004). Poučenie z pohľadu na konfliktné miss rates je, že sekundárnym cache veľmi prospieva asociativita.
Táto výhoda bola dobre známa na konci osemdesiatych rokov a začiatku devätdesiatych rokov, kedy návrhári CPU nemohli zmestiť veľké cache na čip a nemali dostatočnú šírku pásma na dátovú cache ani štítky cache aby mohli implementovať vysokú asociativitu na cache mimo čipu. Boli pokusy o zúfalé hacky: MIPS R8000 používal drahé rezervované SDRAM mimo čipu so štítkami, ktoré mali v sebe komparátory štítkov a large drivers on the match lines, aby tak implementovali 4MB štvorcestne asociatívnu cache. MIPS R10000 používali na štítky bežné SRAM čipy a pri každom prístupe hádali, ktorou cestou nastane cache hit.
Preklad adries
Väčšina CPU na všeobecné účely implementujú určitú formu virtuálnej pamäte. V skratke – každý program bežiaci na stroji vidí svoj vlastný zjednodušený adresný priestor, ktorý obsahuje iba jeho kód a dáta. Každý program si dáva veci do svojho adresného priestoru, bez ohľadu na činnosť iných programov v iných adresných priestoroch.
Virtuálna pamäť vyžaduje od procesora preklad virtuálnych adries generovaných programom na fyzické adresy v hlavnej pamäti. Časť procesora zodpovedná za tento preklad sa nazýva jednotka správy pamäte (memory management unit, MMU). Rýchla cesta cez MMU môže vykonávať tieto preklady uložená v zvláštne nazvanom Translation Lookaside Buffer (TLB), ktorý je cache mapovaní tabuľky stránok operačného systému.
Pre účely tohto rozboru rozlišujeme tri dôležité charakteristiky prekladu adries:
- Latencia: virtuálna adresa je dostupná od MMU po určitom čase, asi niekoľko cyklov potom ako je dostupná adresa od generátora adries.
- Aliasing: Viaceré virtuálne adresy môžu byť mapované na jednu fyzickú adresu. Väčšina procesorov zaručuje, že všetky aktualizácie tejto jednej fyzickej adresy sa budú diať v poradí ako nasledujú v programe. Aby procesor mohol túto záruku splniť, musí zabezpečiť, že v každom okamihu existuje v cache iba jedna kópia tejto fyzickej adresy.
- Granularita: virtuálny adresný priestor je rozdelený do stránok. Napríklad 4GB adresný priestor môže byť rozdelený na 1048576 4KB stránok, z ktorých každú je možné jednotlivo mapovať. Je možné podporovať rozličnú veľkosť jednotlivých stránok, detaily pozri v článku virtuálna pamäť.
Historická poznámka: prvé systémy s virtuálnou pamäťou boli veľmi pomalé, pretože vyžadovali prístup k tabuľke stránok (ktorá bola v pamäti) pre každým programovým prístupom k hlavnej pamäti. Bez akýchkoľvek cache bolo výsledkom spomalenie konečnej rýchlosti stroja na polovicu. Prvé hardvérové cache použité v počítačovom systéme vlastne neboli dátové ani inštrukčné cache, ale TLB.
Existencia rozličných fyzických a virtuálnych adries vyvoláva otázku, či sa v štítku a cache indexe používajú virtuálne alebo fyzické adresy. Motivácia za použitím virtuálnych adries je rýchlosť: vituálne indexovaná, virtuálne štítkovaná dátová cache úplne odbremeňuje MMU od opakovanej záťaže. Latencia tohto opakovania (load latency) je kritickou premennou ovplyvňujúcou výkon CPU. Väčšina moderných cache prvej úrovne je virtuálne indexovaných, čo aspoň umožňuje paralelné vykonávanie vyhľadávanie MMU v TLB s prinesením dát z cacheovanej RAM.
Ale virtuálne indexovanie nie je vždy najlepšou voľbou. Zavádza problém virtuálnych aliasov—cache môže mať viaceré adresy, ktoré môžu uložiť hodnotu jedinej fyzickej adresy. Náklady použitia virtuálnych aliasov rastú s veľkosťou cache a výsledkom je, že väčšina cache druhej a vyššej úrovne sú fyzicky indexované.
Virtuálne štítkovanie nie je obvyklé. Ak je možné ukončiť vyhľadávanie v TLB pred vyhľadávaním v RAM cache, fyzická adresa je včas dostupná pre porovnanie štítkov a virtuálne štítkovanie nie je potrebné. Väčšie cache potom bývajú fyzicky štítkované a iba malé cache s veľmi nízkou latenciou sú štítkované virtuálne. V posledných CPU na všeobecné účely nahradilo virtuálne štítkovanie vhints, čo je popísané nižšie.
Virtuálne indexovanie a virtuálne aliasy
Obvyklým spôsobom, ako procesor zaručuje, že aliasované virtuálne adresy sa správajú ako jediná adresa je zabezpečenie, že sa v cache neustále nachádza iba jediná kópia daného virtuálneho aliasu.
Zakaždým, keď sa do virtuálne indexovanej cache pridá nový záznam, procesor hľadá, či už v cache neexistuje virtuálny alias a ak áno, najskôr ho vyhodí. Táto špeciálna obsluha nastáva iba v prípade cache miss. Počas cache hit nie je potrebná žiadna zvláštna činnosť, čo pomáha udržať rýchlu cestu rýchlou.
Najpriamejším spôsobom, ako nájsť aliasy je zabezpečiť, aby boli všetky mapované na rovnakú adresu v cache. To sa stáva napr. keď má TLB 4KB stránky a cache s veľkosťou 4KB alebo menšou je mapovaná priamo.
Moderné cache prvej úrovne sú oveľa väčšie ako 4KB, ale stránky virtuálnej pamäte zostali na rovnakej veľkosti. Ak má cache veľkosť napr. 16KB a je virtuálne indexovaná, pre každú virtuálnu adresu existujú štyri cache adresy, ktoré ju môžu obsahovať, ale sú aliasované na rozličné virtuálne adresy. V prípade cache miss je potrebné skontrolovať všetky štyri adresy, či sa ich zodpovedajúce fyzické adresy nezhodujú s prístupom, ktorý spôsobil cache miss.
Tieto kontroly sú tie isté, ako používajú množinovo asociatívne cache pri výbere jednotlivých zhôd. Takže ako je 16KB virtuálne indexovaná cache štvorcestne množinovo asociatívna a používa sa s virtuálnou pamäťou so 4KB stránkami, na vyhodenie virtuálnych aliasov počas cache miss nie je potrebná žiadna ďalšia práca, pretože kontroly už prebehli počas kontroly cache hit. Vezmime si znova ako príklad AMD Athlon—má 64KB dátovú cache prvej úrovne, 4KB stránky a dvojcestnú množinovú asociativitu. Keď nastane cache miss, 2 z 16 (==64KB/4KB) možných virtuálnych aliasov už boli skontrolované a ďalších sedem cyklov hardvéru kontroly štítkov je potrebných na dokončenie kontroly virtuálnych aliasov.
Virtuálne štítky a vhints
Virtuálne štítkovanie je tiež možné. Veľkou výhodou virtuálnych štítkov je to, že pri asociatívnych cache umožňujú pokračovanie kontroly zhody štítkov predtým, ako sa dokončí preklad virtuálnej adresy na fyzickú. Ale:
- Koherenčné skúšky a vyhodenia produkujú fyzickú adresu, s ktorou sa má pracovať. Hardvér musí byť schopný nejako konvertovať fyzickú adresu na cache index, vo všeobecnosti uložením fyzických štítkov ako virtuálne štítky. Pre porovnanie—fyzicky štítkovaná cache nemusí udržiavať virtuálne štítky, čo je jednoduchšie.
- Keď je z TLB zmazané mapovanie fyzickej adresy na virtuálnu, záznamy cache s touto virtuálnou adresou sa musia nejako uvoľniť. Alebo ak sú záznamy cache povolené na stránkach, ktoré nie sú mapované pomocou TLB, tieto záznamy musia byť uvoľnené po zmene prístupových práv k týmto stránkam v tabuľke stránok.
Je tiež možné, aby operačný systém zabezpečoval, aby v cache súčasne neexistovali virtuálne aliasy. Operačný systém to dosiahne vynútením farbenia stránok, ktoré je opísané nižšie. Niektoré skoré RISC procesory (SPARC, RS/6000) sa vydali touto cestou. V poslednej dobe nebola použitá, keďže hardvérové náklady na detekciu a vyhadzovanie virtuálnych nákladov klesli a stúpla daň za komplexnosť softvéru a stratu výkonu pri dokonalom farbení stránok.
Môže byť užitočné rozlišovať dve funkcie štítkov v asociatívnej cache: používajú sa na zistenie, ktorú cestu záznamu vybrať a používajú sa na zistenie, či nastal cache hit alebo miss. Druhá funkcia musí byť vždy správna, ale pre prvú funkciu je prípustné, aby hádala a niekedy chybila.
Niektoré procesory (napr. skoré SPARC) majú cache s virtuálnymi aj fyzickými štítkami. Virtuálne štítky sa používajú na výber cesty a fyzické na určenie, či nastal cache hit alebo miss. Tento druh cache má výhodu latencie virtuálne štítkovanej cache a jednoduché softvérové rozhranie fyzicky štítkovanej cache. Prináša však náklady duplikovaných štítkov. Tiež počas spracovania cache miss je potrebné skontrolovať alternatívne cesty cache line indexu kvôli virtuálnym aliasom a vyhodiť všetky duplikáty.
Dosiahnuť určité kapacitné (aj isté latenčné) výhody je možné udržiavaním virtual hints (virtuálne vodítka) pre každý cache záznam namiesto virtuálnych štítkov. Tieto vodítka sú podmnožinou alebo hashom virtuálneho štítku a používajú sa na výber cesty, ktorou sa dostať k dátam a k fyzickému štítku. Ako pri virtuálne štítkovanej cache, môže nastať zhoda virtuálnych vodítok, ale nezhoda fyzických tagov, kedy je potrebné vyhodiť záznam so zhodným vodítkom, aby mali prístupy do cache po zaplnení cache na tejto adrese iba jedu zhodu vodítka. Keďže virtuálne vodítka sa odlišujú v menšom počte bitov ako virtuálne štítky, cache s virtuálnymi štítkami trpí väčším počtom konfliktných cache misses ako virtuálne štítkovaná cache.
Snáď najväčšia redukcia virtuálnych vodítok sa nachádza v Pentium 4 (jadrá Willamette a Northwood). V týchto procesoroch je efektívne virtuálne vodítko 2 bity dlhé, pričom cache je štvorcestne množinovo asociatívna. Hardvér si udržiava jednoduchú permutáciu virtuálnej adresy ku cache indexu, a tak na výber tej správnej zo štyroch ciest nie je potrebný CAM .
Farbenie stránok
Veľké fyzicky indexované cache (zvyčajne sekundárne cache) narážajú na problém: nad tým, ktoré stránky v cache navzájom kolidujú ma kontrolu operačný systém a nie aplikácia. Rozdiely v alokácii stránok od programu k druhému vedú k rozdielnym vzorom kolízií v cache, čo má za dôsledok veľké rozdiely vo výkone programu. Tieto rozdiely môžu veľmi sťažiť dosiahnutie konzistentného a opakovateľného časovania pre beh benchmarku, čo vedie k frustrovaným predajcom žiadajúcim nápravu problému od autorov operačných systémov.
Pre pochopenie problému uvažujme CPU s 1MB fyzicky indexovanej priamo mapovanej cache druhej úrovne a 4KB virtuálnymi pamäťovými stránkami. Sekvenčné fyzické stránky sú mapované do súvislej oblasti v cache, až po 256 stránkach sa vzorka opakuje od začiatku. Každú fyzickú stránku môžeme označiť farbou od 0-255 určujúcou, kam do cache môže ísť. Adresy v rámci fyzických stránok s rozličnou farbou nemôžu v cache kolidovať.
Programátor pokúšajúci sa maximálne využiť cache môže zostaviť prístupové vzory svojho programu tak, aby bolo naraz v každom okamihu potrebné cacheovať iba 1 MB dát, čím sa vyhne kapacitným cache misses. Ale mal by tiež zabezpečiť, aby prístupové vzory nemali konfliktné cache misses. Jedným zo spôsobov poňatia tohto problému je rozdeliť virtuálne stránky, ktoré program používa, a priradiť im virtuálne farby rovnakým spôsobom, ako sme priradili fyzické farby fyzickým stránkam.
Programátor potom môže zostaviť prístupové vzory svojho kódu tak, aby naraz nepoužíval dve stránky s rovnakou virtuálnou farbou v jednom časovom okamihu. O tomto druhu optimalizácie existuje množstvo literatúry (napr. loop nest optimization), zväčša pochádzajúcej od High Performance Computing (HPC) komunity.
Chyták je v tom, že aj keď všetky naraz používané stránky majú rozličnú virtuálnu farbu, niektoré môžu mať rovnakú fyzickú farbu. V skutočnosti, ak operačný systém priraďuje fyzické stránky náhodne a jedným spôsobom, je extrémne pravdepodobné, že niektoré stránky budú mať rovnakú fyzickú farbu a potom adresy týchto stránok budú v cache kolidovať (toto je tzv. birthday paradox).
Riešením je nechať operačný systém pokúsiť sa priradiť rozličné fyzické farby rozličným virtuálnym farbám, technika nazývaná farbenie stránok (page coloring). Hoci skutočné mapovanie z virtuálnej na fyzickú farbu je irelevantné vzhľadom na výkon systému, je zložité pracovať s čudnými mapovaniami a neprinášajú veľké výhody, takže väčšina pokusov farbenia stránok pozostáva zo snahy udržiavať fyzické a virtuálne farby rovnaké.
Ak môže operačný systém zaručiť, že každá fyzická farba je mapovaná iba na jednu virtuálnu farbu, potom neexistujú virtuálne aliasy a procesor môže používať virtuálne indexovanú cache bez ďalších kontrol na virtuálne aliasy počas obsluhy cache miss. Alebo OS môže vyhodiť stránku z cache zakaždým, keď zmení virtuálnu farbu na inú. Ako sme spomenuli vyššie, tento prístup bol použitý v niektorých raných návrhoch SPARC a RS/6000.
Hierarchia cache v modernom procesore
Moderné procesory majú v skutočnosti na čipe viacero spolupracujúcich cache. Vývoj modernej hierarchie cache bol usmerňovaný dvoma problémami.
Špecializované cache
Prvý problém je, že CPU s pipeline pristupujú k pamäti z viacerých miest v pipeline: prinesenie inštrukcie, preklad adresy z virtuálnej na fyzickú a prinesenie dát. Jednoduchý príklad je uvedený v článku Classic RISC Pipeline. Prirodzeným dôsledkom je použiť rozličné fyzické cache pre každý z týchto bodov, aby nebolo potrebné používať žiadne fyzické zariadenie na obsluhu dvoch miest v pipeline. Tak pipeline prirodzene skončí s aspoň tromi oddelenými cache (inštrukčná, TLB, a dátová), každou špecializovanou na určitú úlohu.
Victim cache
victim cache je cache používaná na udržiavanie blokov vyhodených z cache CPU z dôvodu konfliktného alebo kapacitného cache miss. Victim cache leží medzi hlavnou cache a jej dopĺňacou cestou a udržiava iba bloky, ktoré boli vyhodené z cache počas cache miss. Táto technika sa používa na redukciu nákladov, ktoré spôsobuje cache miss.
Originálna victim cache na HP PA7200 bola malá, plne asociatívna cache. Neskoršie procesory ako AMD K7 a K8 používali veľmi veľkú sekundárnu cache ako victim cache aby sa vyhli duplikácii obsahu veľkej primárnej cache.
Trace cache
Jedným z extrémnejších príkladov špecializácie cache je trace cache, ktorú môžeme nájsť v procesoroch Intel Pentium 4.
Trace cache je mechanizmus zväčšenia šírky pásma pre prinesenie inštrukcií ukladaním stôp inštrukcií, ktoré už boli prinesené. Mechanizmus bol prvýkrát navrhli Eric Rotenberg, Steve Bennett a Jim Smith v ich dokumente z roku 1996 : "Trace Cache: a Low Latency Approach to High Bandwidth Instruction Fetching."
Trace cache ukladá inštrukcie potom, ako boli dekódované alebo odložené. To umožňuje jednotke pre prinesenie inštrukcií priniesť niekoľko základných blokov bez toho, aby sa musela starať o vetvy v toku programu. Trace lines sa ukladajú v trace cache na základe program counter prvej inštrukcie v trace a množine predpovedí vetvenia. To umožňuje ukladanie rôznych trace ciest začínajúcich na rovnakej adrese. Keď je pipeline vo fáze prinesenia inštrukcie, skontroluje sa aktuálny program counter spolu s množinou predpovedí vetvenia, či nenastal cache hit. Ak nastal hit, trace line sa použije na prinesenie, ktoré tak nemusí smerovať do bežnej cache alebo do pamäte. Trace cache naďalej posiela prinášaciu jednotku do konca trace line alebo do chyby predpovede v pipeline. Ak nastane cache miss, začne sa budovať nová trace.
Trace cache sa tiež používajú v procesoroch ako Intel Pentium 4 na uloženie už dekódovaných mikrooperácií alebo preklad komplexných x86 inštrukcií, aby ich nebolo potrebné znova dekódovať keď budú znova potrebné.
Plný text Dokumentu Smitha, Rotenberga a Bennetta na Citeseer.
Architektúra Harvard
Pipelines s oddelenými cache pre inštrukcie a dáta nazývame Harvard architecture. Pôvodne toto spojenie označovalo stroje s oddelenými inštrukčnými a dátovými pamäťami, ktoré tak zabraňovali programu modifikovať svoje inštrukcie.
Viacúrovňové cache
Druhým problémom je fundamentálne vybalansovanie medzi latenciou cache a hit rate. Väčšie cache sú pomalšie a majú lepšie hit rate. Na zmiernenie tohto vyrovnania používajú mnohé počítače viaceré úrovne cache, kde sú malé a rýchle cache sekondované väčšími a pomalšími. Ako sa zväčšuje rozdiel v latencii hlavnej pamäte a najrýchlejšej cache, niektoré procesory začali používať až tri úrovne cache na čipe. Napríklad v roku 2003 sa začal dodávať Itanium II so spolu 6MB cahe tretej úrovne na čipe. Rad IBM Power 4 má 256MB cache tretej úrovne mimo čipu, ktorú zdieľa niekoľko procesorov.
Viacúrovňové cache vo všeobecnosti fungujú tak, že sa najprv skontroluje najmenšia cache prvej úrovne; ak nastane cache hit, procesor môže rýchlo pokračovať. Ak nastane cache miss, skontroluje sa nasledujúca väčšia cache atď. až po kontrolu hlavnej pamäte.
Viacúrovňové cache predstavujú nové rozhodnutia pri návrhu. Napríklad v niektorých procesoroch (ako Intel Pentium 2, 3 a 4, ako aj väčšina RISCov), dáta v L1 cache môžu byť aj v L2 cache. Tieto cache sa nazývajú inkluzívne. Iné procesory (ako AMD Athlon) majú exkluzívne cache—je zaručené, že dáta sa nachádzajú najviac v jednej z L1 a L2 cache.
Výhodou exkluzívnych cache je, že sú schopné uchovať viac dát. Táto výhoda sa zväčšuje so zvyšujúcou sa veľkosťou cache. Keď nastane L1 cache miss, cache line L2, ktorá mala cache hit, sa nahradí s cache line v L1. Táto výmena je o niečo viac prácna ako iba skopírovanie cache line z L2 do L1, čo robí inkluzívna cache.
Niektoré implementácie inkluzívnych cache zaručujú, že všetky dáta v L1 cache sa nachádzajú aj v L2 cache (implementácie Intel x86 nie). Jednou výhodou prísne inkluzívnych cache je, že keď externé zariadenia alebo iné procesory v multiprocesorovom systéme chcú odstrániť cache line z procesora, stačí, aby procesor skontroloval L2 cache. V hierarchiách cache, ktoré nevynucujú inklúziu je potrebné skontrolovať aj L1. Nevýhodou je vzťah medzi asociativitami cache L1 a L2: ak nemá L2 cache aspoň toľko ciest, ako všetky cache L1 spolu, efektívna asociativita L1 cache je obmedzená.
Inou výhodou inkluzívnej cache je, že väčšia cache môže používať väčšie cache lines, čo redukuje veľkosť štítkov sekundárnej cache. Ak je sekundárna cache o rád väčšia ako primárna a dáta cache sú o rád väčšie ako štítky, je toto ušetrené miesto porovnateľné s priestorom, ktorý môže byť využitý na uloženie obsahu L1 v L2 cache.
Ako sme uviedli vyššie, väčšie počítače občas majú medzi L2 cache a hlavnou pamäťou ďalšiu cache zvanú L3. Táto cache sa vo všeobecnosti implementuje na oddelenom čipe od CPU a v roku 2004 sa jej veľkosť pohybuje od 2 do 256 megabajtov. Implementácia tejto cache vo všeobecnosti stojí dobre cez $1 000 a jej účinky je možné vidieť väčšinou na veľkých množinách dát, aké sa zvyčajne nenachádzajú na PC. Dôvodom prečo procesory pre PC vo všeobecnosti nemávajú takúto cache sú náklady.
Nakoniec, na druhom konci pamäťovej hierarchie, samotný súbor registrov CPU môžeme považovať za najmenšiu a najrýchlejšiu cache v systéme so zvláštnou charakteristikou, že je organizovaná softvérom—zvyčajne kompilátorom, keďže ten alokuje, ktoré registre budú udržiavať hodnoty prinesené z hlavnej pamäte.
Príklad: K8
Na ilustráciu špecializácie a viacúrovňovej organizácie cache, tu je hierarchia cache procesora AMD Athlon 64, ktorého návrh jadra je známy ako K8 (detaily tu).
K8 má 4 špecializované cache: inštrukčnú cache, inštrukčnú TLB, dátovú TLB a dátovú cache. Každá z týchto cahe je špecializovaná:
- inštrukčná cache udržiava kópie 64 bajtových riadkov pamäte a prináša 16 bajtov v každom cykle. Každý bajt v tejto cache sa ukladá v desiatich bitoch namiesto ôsmich, kde nadbytočné dva bity značia hranice inštrukcií (toto je príklad preddekódovania). Cache má iba paritnú ochranu namiesto ECC, pretože parita je menšia a akékoľvek poškodené dáta je možné nahradiť čerstvými dátami prinesenými z pamäte (ktorá má vždy aktuálnu kópiu inštrukcií).
- inštrukčná TLB udržiava kópie záznamov tabuľky stránok (PTEs). Prinesenie inštrukcií v každom cykle prekladá virtuálne adresy na fyzické pomocou tejto tabuľky. Každý záznam má buď 4 alebo 8 bajtov pamäte. Každá TLB je rozdelená na dve časti, jednu, ktorá udržiava PTEs, ktoré mapujú 4 KB, a jednu, ktorá udržiava PTEs mapujúce 4MB alebo 2MB. Takéto rozdelenie umožňuje zjednodušenie plne asociatívnych porovnávacích obvodov v každej časti. Operačný systém mapuje rozdielne sekcie virtuálneho adresného priestoru pomocou PTEs rozličnej veľkosti.
- Dátová TLB má dve kópie udržiavajúce identické záznamy. Dve kópie umožňujú dvom dátovým prístupom v každom cykle preloženie virtuálnej adresy na fyzickú. Ako inštrukčná TLB, aj táto je rozdelená na dva druhy záznamov.
- Dátová cache udržiava kópie 64 bajtových riadkov pamäte. Je rozdelená do ôsmich „banks“ (z ktorých každá ukladá 8KB dát) a môže priniesť dva 8-bajtové bloky dát v každom cykle, pokiaľ sú tieto v odlišných banks. Existujú dve kópie štítkov, pretože 64 bajtový riadok je rozdelený pozdĺž všetkých ôsmich banks. Každá kópia štítku obsluhuje jeden z dvoch prístupov v cykle.
K8 má tiež viacúrovňovú cache. Existujú inštrukčné a dátové TLB druhej úrovne, ktoré ukladajú iba PTEs mapujúce 4KB. Inštrukčné aj dátové cache a rôzne TLB, môžu byť plnené z veľkej zjednotenej L2 cache. Táto cache je exkluzívna pre L1 inštrukčnú aj dátové cache čo znamená, že ktorýkoľvek 8-bbajtový riadok môže byť len v jednej z týchto cahce: L1 inštrukčná cache, L1 dátová cache alebo L2 cache. Je však možné, aby mal riadok v dátovej cache PTE, ktorý je tiež v jednej z TLB—operačný systém je zodpovedný za udržiavanie koherencie jednotlivých TLB tým, že ich časti vyčistí pri aktualizácii tabuľky stránok v pamäti.
Implementácia
Pretože čítanie z cache je najbežnejšou operáciou, ktorá zaberá viac ako jeden cyklus, opakovaný výskyt od načítania inštrukcie po inštrukciu na ňom závislú predstavuje v dobre navrhnutých procesoroch zvyčajne kritickú cestu, aby dáta v tejto ceste mrhali čo najmenej času pri čakaní na dokončenie cyklu. Výsledkom je, že cache prvej úrovne je najcitlivejším blokom na latenciu z celého čipu.
Najjednoduchšia cache je virtuálne indexovaná priamo mapovaná cache. Virtuálna adresa sa počíta sčítačkou, relevantná časť adresy sa vyberie a použije na indexáciu SRAM, ktorá vráti načítané dáta. Dáta sa zarovnajú do bajtov v bitovom posúvači a odtiaľ sa podajú ďalšej operácii. Nie je potrebná žiadna kontrola štítkov vo vnútornej slučke—v skutočnosti štítky netreba ani čítať. Neskôr v pipeline, ale pred odsunutím inštrukcie načítania, je potrebné prečítať štítok pre načítané dáta a porovnať s virtuálnou adresou, aby sa uistilo, že nastal cache hit. V prípade cache miss sa cache aktualizuje pomocou požadovanej cache a pipeline sa reštartuje.
Asociatívna cache je zložitejšia, pretože je potrebné načítať nejaký štítok, aby sa určilo, ktorý záznam z cache vybrať. N-cestná množinovo asociatívna cache prvej úrovne zvyčajne číta všetkých N možných štítkov a N dát paralelne a potom vyberie dáta priradené danému štítku. L2 cache niekedy šetria energiu tým, že najprv prečítajú štítky, aby sa z dátovej SRAM prečítal iba jeden prvok.
Diagram napravo objasňuje spôsob, akým sa používajú rôzne časti adresy. Adresné bity sú označené v notácii little endian. Diagram zobrazuje SRAM, indexovanie a multiplexovanie pre 4KB, 2-cestnú množinovo asociatívnu, virtuálne indexovanú a virtuálne štítkovanú cache so 64B riadkami, 32b šírkou čítania a 32b virtuálnou adresou.
Pretože cache je 4KB a má 64B riadky, v cache je iba 64 riadkov a čítame dva naraz zo štítkovej SRAM, ktorá má 32 riadkov, každý s párom 21-bitových štítkov. Hoci by na indexáciu štítkov a dátových SRAM mohla byť použitá akákoľvek funkcia bitov 31 až 6 virtuálnej adresy, je najjednoduchšie použiť najmenej významné bity.
Podobne, pretože cache je 4KB a má čítaciu cestu o šírke 4B a pre každý prístup číta dve cesty, dátová SRAM má 512 riadkov o šírke 8 bajtov.
Modernejšia cache my mohla byť 16KB, 4-cestne množinovo asociatívna, virtuálne indexovaná, s virtuálnymi pomôckami (vhints) a fyzicky štítkovaná s 32B riadkami, 32b šírkou čítania a 36b fyzickými adresami. Opakovaný výskyt čítacej cesty by bol veľmi podobný hore uvedenej ceste. Namiesto štítkov by sa čítali vhints a porovnávali s podmnožinou virtuálnych adries. Neskôr v pipeline by sa virtuálne adresy preložili na fyzické pomocou TLB a fyzický štítok by sa prečítal (iba jeden, keďže vhints poskytujú informáciu o ceste pre čítanie). Nakoniec by sa fyzická adresa porovnala s fyzickým štítkom, aby sa určilo, či nastal cache hit.
Niektoré návrhy SPARC vylepšili rýchlosť svojich L1 cache o niekoľko zdržaní hradiel tak, že rozdelili sčítačku virtuálnej adresy do dekóderov SRAM. Pozri Sum addressed decoder.
Pozri aj
- Cache
- Cache coherency
- Cache line
- No-write allocation
- Memoization, briefly defined in List of computer term etymologies
Externé odkazy
- Evaluating Associativity in CPU Caches — Hill and Smith — 1989 — Introduces capacity, conflict, and compulsory classification.
- Cache Performance for SPEC CPU2000 Benchmarks — Hill and Cantin — 2003 — This reference paper has been updated several times. It has thorough and lucidly presented simulation results for a reasonably wide set of benchmarks and cache organizations.