Reprezentace znalostí
Reprezentace znalostí je schopnost jazyka (vyjadřovací síla) popisovat – reprezentovat jistou třídu znalostí. Základní klasifikací těchto tříd je způsob (filtr) poznání, prostřednictvím kterého byly znalosti získány. Přirozené poznání používá jako filtr poznání vágnost a získané znalosti jsou inherentně vágní (Bertrand Russell) [1]. Umělé poznání exaktních věd užívá diskrétní filtr Newtonův, získané znalosti jsou popsány exaktně.

Dva typy znalostí, mezi nimiž je propast.
Mezi znalostmi získanými přirozeným poznáním a znalostmi získanými poznáním metodou exaktních věd, je kvalitativní propast[2],[3], [4]. V prvém případě se na svět díváme filtrem vágnosti, v druhém případě filtrem „dírkovaným“, dírkami „vidíme“ atributy (veličiny a parametry} - elementární manifestace reálného světa a vztahy mezi nimi, a nic jiného. Newton „digitalizoval“ přirozený vágní pohled člověka na reálný svět. Inherentně vágní znalosti získané přirozeným poznáním lze sdělovat (reprezentovat, popsat) jen a jen neformálním jazykem, nejčastěji přirozeným. Znalosti získané umělým poznáním lze reprezentovat umělým formálním jazykem (matematika, logika, programovací jazyky). Charakteristickým rysem neformálních jazyků je vágní, subjektivní a emocionálně zabarvené přiřazení významu dané jazykové konstrukci, kterému se říká konotace. Sémantický diferenciál konotace je vždy nenulový. Formální jazyky naproti tomu musí mít sémantický diferenciál nulový, je to jejich základní ustavující podmínka. Konotace je v tomto případě exaktní a v matematice (logice) se jí říká interpretace. Formální jazyky proto nelze použít pro reprezentaci znalostí získaných přirozeným poznáním a reprezentovaných původně přirozeným jazykem.
Pojem reprezentace znalostí používá i odvětví zabývající se umělou inteligencí. V polovině 70. let se začal v umělé inteligenci přesouvat důraz od hledání univerzálního algoritmu pro řešení široké třídy úloh k práci se specializovanými znalostmi z určité oblasti. Tento trend se nejvíce rozvinul v oblasti expertních systémů.
Reprezentaci znalostí z pohledu umělé inteligence tedy můžeme chápat jako proces získávání, zaznamenávání a ukládání znalostí do strojem srozumitelné podoby a jejich následné využívání v rámci expertního systému.
Znalosti
„Schopnost člověka nebo jakéhokoli jiného inteligentního systému uchovávat, komunikovat a zpracovávat informace do systematicky a hierarchicky uspořádaných znalostních struktur. Znalost je charakterizována schopností abstrakce a generalizace dat a informací.“[5]
Znalost je vnitřní náhled, porozumění a praktické know-how, které všichni ovládáme. Je to základní zdroj, který nám umožňuje chovat se inteligentně.
Znalosti jsou spojeny s pojmy data a informace, respektive znalosti vycházejí z informací a ty zase vycházejí z dat. Za data lze pokládat všechny znakové řetězce, které vstupují do výpočetního řetězce. Tato data většinou mají nějaký význam, jsou tedy nějak interpretována. Interpretací dat se rozumí smysluplné přiřazení významu (sémantiky) datům. Informaci tvoří data spolu se svou interpretací, pojem informace je tedy neoddělitelný od významu dat, která jsou jejími nositeli. Znalost je potom informace, která je použitelná a začlenitelná respektive odvoditelná v souvislosti s jinými informacemi.
Přechod od dat ke znalostem je doprovázen dvěma úrovněmi přiřazování metadat. Na první z nich je datům smysluplně přiřazován jejich význam nějakým definičním jazykem, na druhé úrovni se nad nimi definují jejich vzájemné vztahy, souvislosti a možné důsledky.[6]
Podle Wiederholda[7] je rozlišení dat a znalostí z hlediska budování informačního, respektive znalostního systému tento:
- Jestliže se můžeme při sběru materiálu spolehnout na automatický proces nebo „úředníka“, hovoříme o datech. Správnost dat vzhledem k reálnému světu může být objektivně potvrzena s jeho opakovaným pozorováním.
- Jestliže hledáme experta, který by poskytl materiál, potom hovoříme o znalostech. Znalosti obsahují abstrakce a generalizace objemného materiálu. Obvykle jsou méně přesné a těžko je můžeme objektivně ověřit.
Vyjádření znalostí
Implicitní znalost
Jedná se o takovou znalost, která není přímo vyjádřena v určitém zdroji, je primárně skryta, ale je potenciálně sdělitelná. Obvykle je zahrnuta v jednání, způsobu řešení úloh, souboru dat apod. Speciální skupinou implicitních znalostí jsou tacitní (slovy nesdělitelné) znalosti. V počítačových expertních systémech se jako implicitní označují znalosti rozptýlené v jednotlivých programových instrukcích, které se aplikují podle předem stanoveného algoritmu (procedurálně reprezentované znalosti).[8]
Explicitní znalost
Znalost zaznamenaná v určitém jazyce a dostupná přímo v určitém informačním zdroji (např. dokument, záznam v databázi). V počítačových expertních systémech se jako explicitní označují znalosti uložené v bázi znalostí, jež je oddělena od programu, který ji umožňuje využívat a odvozovat z ní nové znalosti (deklarativně reprezentované znalosti).[9]
Znalostní modely a ontologie
V klasickém pojetí je získávání znalostí (např. pro expertní systémy) založeno na získávání znalostí od expertů. Zpočátku mělo získávání znalostí podobu přebírání znalostí: znalostní inženýr převzal znalosti od experta a přímo je vkládal do expertního systému. Takto vytvářené báze znalostí jsou ale obtížně modifikovatelné a přenositelné. Nebývají v nich totiž rozlišeny statické znalosti, týkající se celé aplikační oblasti a znalosti vztahující se k řešení dané konkrétní úlohy. Proto dochází na přelomu 80. a 90. let ke změně pohledu na proces získávání znalostí. Tento proces začíná být chápan jako modelování znalostí, tedy jako tvorba přehledných a opakovaně použitelných modelů dané úlohy. Znalosti jsou zachycovány nezávisle na odvozovacích mechanizmech a jazyku reprezentace znalostí konkrétního expertního systému. Výhody tohoto přístupu jsou v zásadě dvojí:
- usnadnění vývoje aplikace: model vede tvůrce systému k lepšímu strukturování řešené úlohy
- sdílení a opakované používání: pokud jsou modely založeny na standardizované terminologii, pak jsou srozumitelné nejen tvůrcům aplikace ale celé komunitě.
Nejnověji se ve znalostním modelování objevuje pojem ontologie. Tento pojem je (na rozdíl od filosofického pojetí, kde ontologie znamená nauku o „bytí“) chápán jako označení domluvené terminologie pro určitou aplikační oblast, která umožňuje sdílení znalostí z této oblasti. Ontologie tedy umožňují formalizovat doménové znalosti.[10]
Reprezentační jazyky
V běžném životě obvykle využíváme k vyjádření svých znalostí přirozeného jazyka. Ten však odráží kromě informační funkce i kulturně historické podmínky svého vývoje a je příliš složitý, nepravidelný a někdy nejednoznačný. Proto, aby bylo možné pracovat se znalostmi v podobě vhodné pro počítačovou implementaci, je třeba zavést umělý- reprezentační jazyk. Umělé jazyky jsou jednoznačné a úsporné a jejich vhodná volba má značný význam i pro časovou, výpočetní a prostorovou náročnost kladenou na zpracování znalostí.
Predikátová logika
Jako základní nástroj pro reprezentaci znalostí v umělé inteligenci je považován jazyk predikátové logiky prvního řádu. Tento jazyk má přesně definovanou syntaxi a sémantiku a jeho podstatnou výhodou je to, že kromě schopnosti popsat znalosti ještě poskytuje metody jak odvozovat znalosti další. Přitom zaručuje, že pokud jsou výchozí znalosti pravdivé, jsou pravdivé i znalosti odvozené. Jazyk predikátové logiky obsahuje:
- individuové proměnné x, y, z, … (nekonečně mnoho)
- predikátové symboly P, Q, R, … (konečně mnoho)
- funkční symboly f, g, h, … (konečně mnoho) – např. : sin, ln, ale také matka (někoho) apod.
- konstanty a, b, c, … (nejvýše konečně mnoho)
- kvantifikátory a
- logické spojky: pro konjunkci, pro disjunkci pro implikaci, pro ekvivalenci, pro negaci. Výjimečně se zařazují další logické spojky
Z individuových proměnných, konstant a funkčních symbolů jsou vytvářeny termy. Termy reprezentují všechna univerzální i speciální jména objektů, o nichž může být při použití daného jazyka řeč. Predikátové symboly, kvantifikátory a logické spojky pak slouží k vytváření formulí, což jsou právě takové jazykové výrazy, které reprezentují znalosti. Mezi nimi hrají důležitou roli, takové formule, kterým lze přidělit pravdivostní hodnotu a chovají se tak jako výroky.[11][6]
Pravidla
Pravidla představují nejpoužívanější prostředek pro reprezentaci znalostí v expertních systémech. Pravidla jakožto IF-THEN struktury jsou známa z programovacích jazyků, sémantika pravidel vychází z implikací ve výrokové logice. Pravidla mohou být chápána dvojím způsobem:
- procedurálně: jestliže situace, pak akce
- deklarativně: jestliže předpoklad pak závěr
Procedurální interpretace je běžná v generativních expertních systémech – nastala-li příslušná situace, systém provede danou akci. Deklarativní interpretace odpovídá diagnostickým expertním systémům – je-li splněn příslušný předpoklad, systém odvodí daný závěr. Tato interpretace je vlastně speciálním případem procedurální interpretace, provádí se jediná standardní akce – odvození závěru. Pravidla v bázi znalostí je možno znázornit v podobě AND/OR grafu. Uzly grafu představují výroky a orientované hrany představují pravidla. Konjunktivní vazba mezi výroky v předpokladu pravidla se znázorňuje obloučkem.[12]
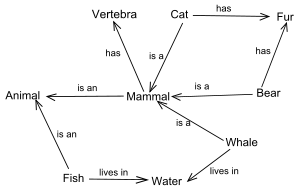
Sémantické sítě
Sémantické sítě byly navrženy v druhé polovině 60. let v rámci prací na porozumění přirozenému jazyku. Sémantická síť umožňuje popisovat realitu jako objekty, které jsou navzájem v nějakých vztazích (relacích). Sémantická síť má přirozenou grafovou reprezentaci – objekty jsou uzly a relace mezi nimi jsou hrany v grafu. Relace v sémantických sítích představují základní prostředek pro vyjadřování znalostí. Často vyskytujícími relacemi jsou:
- is_a – umožňuje vyjádřit, že nějaký konkrétní objekt (instance) patří do určité třídy objektů
- a_kind_of – umožňuje vyjadřovat hierarchii tříd
- part_of – umožňuje vyjádřit, že objekt (třída objektů) je tvořen částmi
Rámce
Rámce byly navrženy v polovině 70. let Marvinem Minskym z MIT jako prostředek pro reprezentaci znalostí. Rámce v původní představě měly umožňovat reprezentovat stereotypní situace. Práce s rámci měla být založena na postupném vyplňování stránek, do kterých se zapisují hodnoty položek (vlastnosti). Přitom se hojně využívá předdefinovaných hodnot. Rámce dobře umožňují vyjádřit statické znalosti, tedy nějakou hierarchii pojmů (s použitím položek a_kind_of) nebo dekompozici (s použitím položek part_of). Vazba mezi rámci se dá (podobně jako u sémantických sítí) znázornit grafem. Na rozdíl od sémantických sítí ale mají uzly v grafu (rámce) vnitřní strukturu. V současné době rámce pronikly do programovacích jazyků. Zde se pro ně používá název objekty; příslušný styl programování využívající objekty se pak nazývá objektově orientované programování. V případě rámců pro reprezentaci znalostí má největší význam dědičnost (lze dědit položky i jejich hodnoty; obvyklé je dělení shora dolů) a zapouzdření (součástí rámce jsou kromě datových struktur i procedury pro práci s nimi).[10]
Další způsoby
Předchozí čtyři reprezentační jazyky patří mezi nejčastěji využívané způsoby reprezentace znalostí. Nejedná se však o všechny možné způsoby reprezentace, mezi další patří například:
- deskripční logika – zastřešuje řadu příbuzných logických formalismů, jejichž společným rysem je snaha zachytit strukturu tříd a relací chápaných obdobně, jako v systémech založených na rámcích.
- konceptuální grafy –zachycují abstraktní, konceptuální strukturu jazykové podoby vyjádřené znalosti. Mohou být znázorněny graficky či zapsány v podobě jim odpovídajícího lineárního textového kódu. Tvorba konceptuálních grafů vychází z lingvistické znalosti gramatické stavby vět přirozeného jazyka a z pojetí, že věty v přirozeném jazyce vyjadřují vztahy mezi koncepty.
Závěr
Reprezentace znalostí je stále se rozvíjející obor, který nachází praktické uplatnění v expertních systémech, které dovolují vykonávat rozhodovací operace bez nutnosti lidského zásahu právě na základě reprezentovaných znalostí. Z popsaných prostředků pro reprezentaci znalostí jsou pravidla tím nejpoužívanějším. Jejich výhodou je jednoduchost, srozumitelnost a modularita. Nevýhodou je, že v bázi tvořené souborem pravidel mohou být skryty strategické znalosti o způsobu řešení úlohy (např. pořadí pravidel). Dále pak například využití rámců je výhodné pro zachycení struktury nějakých konceptů nebo pro aplikace, kde se provádí porovnávání mezi daty a hypotézami. Mezi hlavní nevýhodu rámců patří to, že přítomnost nebo nepřítomnost jiných rámců může ovlivnit položky v daném rámci kvůli vzájemné provázanosti rámců (jsou tedy méně modulární). Současné nástroje pro tvorbu aplikací mohou nabízet více než jeden prostředek pro reprezentaci znalostí. Jedná se o takzvané hybridní schémata reprezentace, kde se nejčastěji kombinují pravidla a rámce. Vhodný prostředek pro reprezentaci znalostí pak souvisí i s typem a složitostí aplikace.
Odkazy
Reference
- RUSSELL Bertrand.: Vagueness In: The Australasian Journal of Psychology and Philosophy 1, June 1923, pp. 84--92.
- KŘEMEN Jaromír: Notes on Vagueness of Knowledge: Fuzzy ToolsIn: Acta Polytechnica, Vol. 39, No 4, CTU Prague, 1999, pp. 81– 91.
- KŘEMEN Jaromír: Modely a systémy, ACADEMIA, Praha 2007
- KŘEMEN Jaromír.: Nový pohled na možnosti automatizovaného (počítačového) odvozování. Slaboproudý obzor. Roč. 68 (2013), č. 1., str. 7 – 11.
- JONÁK, Zdeněk. Znalost. In: KTD : Česká terminologická databáze knihovnictví a informační vědy (TDKIV)[online databáze]. Praha : Národní knihovna České republiky, c2009 [cit. 2013-05-14]. Dostupné z WWW: http://aleph.nkp.cz/F/?func=direct&doc_number=000000498&local_base=KTD
- LUKASOVÁ, Alena ... [et al.], Formální reprezentace znalostí. Ostrava: Ostravská univerzita v Ostravě, 2010. 343 s. ISBN 978-80-7368-900-1.
- WIDERHOLD, G. Knowledge versus Data. In: Knowledge Base Management Systems. Integrating Artificial Intelligence and Database Technologies. Springer Verlag, 1986.
- KUČEROVÁ, Helena. Implicitní znalost. In: KTD : Česká terminologická databáze knihovnictví a informační vědy (TDKIV)[online databáze]. Praha : Národní knihovna České republiky, c2009a [cit. 2013-05-14]. Dostupné z WWW: http://aleph.nkp.cz/F/?func=direct&doc_number=000000104&local_base=KTD
- KUČEROVÁ, Helena. Explicitní znalost In: KTD : Česká terminologická databáze knihovnictví a informační vědy (TDKIV)[online databáze]. Praha : Národní knihovna České republiky, c2009b [cit. 2013-05-14]. Dostupné z WWW: http://aleph.nkp.cz/F/?func=direct&doc_number=000000102&local_base=KTD
- BERKA, Petr a kol., Expertní systémy. Praha: Vysoká škola ekonomická, 1998. 160 s.. ISBN 80-7079-873-4.
- BRACHMAN, Ronald J. Knowledge representation and reasoning. Amsterdam: Morgan Kaufmann, c2004. 381 s. ISBN 1-55860-932-6.
- SKLENÁK, Vilém a kol., Data, informace, znalosti a Internet. Praha: C.H. Beck, 2001. xvii, 507 s. ISBN 80-7179-409-0.
- MAŘÍK, Vladimír; ŠTĚPÁNKOVÁ, Olga; LAŽANSKÝ, Jiří a kol. Umělá inteligence: Díl 2. Praha: Academia, 1997. 373 s. ISBN 80-200-0504-8
Literatura
- BERKA, Petr a kol., Expertní systémy. Praha: Vysoká škola ekonomická, 1998. 160 s.. ISBN 80-7079-873-4.
- BERKA, Petr, Dobývání znalostí z databází. Praha: Academia, 2003. 366 s. ISBN 80-200-1062-9.
- BRACHMAN, Ronald J. Knowledge representation and reasoning. Amsterdam: Morgan Kaufmann, c2004. 381 s. ISBN 1-55860-932-6.
- DAVIS, R.; SHROBE, H.; SZOLOVITS, P.: What is a Knowledge Representation? AI MagazIne. 14(1), 17-33, 1993.
- Foundations of Knowledge Representation and Reasoning. Edited by Gerhard Lakemeyer, Bernhard Nebel. Berlin: Springer-Verlag, 1994, 355 s. ISBN 3-540-58107-3.
- HELBIG, Hermann. Knowledge Representation and the Semantics of Natural Language, Springer, Berlin, Heidelberg, New York 2006
- JIROUŠEK, Radim. Metody reprezentace a zpracování znalostí v umělé inteligenci. V Praze: Vysoká škola ekonomická, 1995. 103 s. ISBN 80-7079-701-0.
- LUKASOVÁ, Alena ... [et al.], Formální reprezentace znalostí. Ostrava: Ostravská univerzita v Ostravě, 2010. 343 s. ISBN 978-80-7368-900-1.
- MAŘÍK, Vladimír. Umělá inteligence: Díl 1. Praha: Academia, 1993. 264 s. ISBN 80-200-0496-3.
- MAŘÍK, Vladimír; ŠTĚPÁNKOVÁ, Olga; LAŽANSKÝ, Jiří a kol. Umělá inteligence: Díl 2. Praha: Academia, 1997. 373 s. ISBN 80-200-0504-8
- OLEJ, Vladimír; PETR, Pavel, Expertní a znalostní systémy v managementu : distanční opora. Pardubice: Univerzita Pardubice, 2004. 54 s. ISBN 80-7194-688-5.
- PSUTKA, Josef a Jiří KEPKA. Reprezentace znalostí : umělá inteligence. Plzeň: Západočeská univerzita, 1994. 82 s. ISBN 80-7082-126-4.
- SKLENÁK, Vilém a kol., Data, informace, znalosti a Internet. Praha: C.H. Beck, 2001. xvii, 507 s. ISBN 80-7179-409-0.
- SOWA, J.: Knowledge Representation: Logical, Philosophical, and Computational Foundations, Brooks/Cole Publishing Co., Pacific Grove, CA, 2000.
- WIDERHOLD, G. Knowledge versus Data. In: Knowledge Base Management Systems. Integrating Artificial Intelligence and Database Technologies. Springer Verlag, 1986.
Externí odkazy
 Obrázky, zvuky či videa k tématu reprezentace znalostí na Wikimedia Commons
Obrázky, zvuky či videa k tématu reprezentace znalostí na Wikimedia Commons - Reprezentace znalostí v České terminologické databázi knihovnictví a informační vědy (TDKIV)