Konvoluční kód
Konvoluční kód je samoopravný kód používaný v telekomunikacích, u kterého
- Každý m-bitový informační symbol (každý m-bitový řetězec) je zakódován pomocí n-bitového symbolu, kde m/n je poměr kódu (n ≥ m) a
- Transformace je funkce posledních k informačních symbolů, kde k je délka kódového omezení kódu.
Použití
Konvoluční kódy se používají v mnoha aplikacích, kde je nutné dosáhnout spolehlivého přenosu dat, včetně digitálního televizní vysílání, radio, mobilní komunikace, a satelitní komunikace. Tyto kódy jsou často při implementaci řetězeny s kódy vydávajícími tvrdá rozhodnutí, především s Reed–Solomonovými kódy. Až do objevu turbo kódů se jednalo o nejefektivnější kódy přibližující se svojí účinností Shannonovu limitu.
Konvoluční kódování
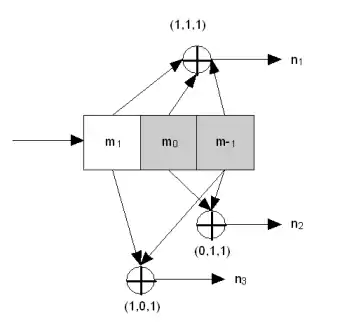
Pro konvoluční kódování dat je potřeba k jednobitových paměťových registrů. Není-li řečeno jinak, všechny registry mají počáteční hodnotu 0. Kodér má n sčítaček modulo-2 (sčítačka modulo 2 může být implementována jedním logickým hradlem XOR, jehož logika je 0+0 = 0, 0+1 = 1, 1+0 = 1, 1+1 = 0), a n generujících polynomů – jeden pro každou sčítačku (viz obr. 1 níže). Vstupním bitem m1 se plní registr úplně vlevo. Pomocí generujících polynomů a hodnot ve zbývajících registrech vyprodukuje kodér n bitů. Následně se provede bitový posun hodnot ve všech registrech doprava (m1 se přesune na m0, m0 se přesune na m-1) a čeká se na další vstupní bit. Pokud nezbývají žádné vstupní bity, kodér pokračuje v generování výstupu tak dlouho, dokud obsah všech registrů nenabude hodnoty nula.
Na následujícím obrázku je kodér s poměrem 1/3 (m/n) a délkou kódového omezení (k) 3. Generující polynomy jsou G1 = (1,1,1), G2 = (0,1,1), a G3 = (1,0,1). Proto se výstupní bity mohou počítat (modulo 2) takto:
- n1 = m1 + m0 + m-1
- n2 = m0 + m-1
- n3 = m1 + m-1.
Rekurzivní a nerekurzivní kódy
Kodér na obrázku výše je nerekurzivní kodér. Příklad rekurzivního:
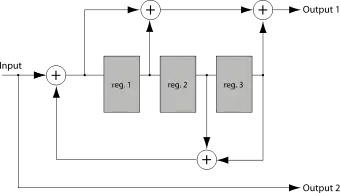
Je vidět, že vstup, který má být zakódován, je také obsažen ve výstupní posloupnosti (výstup Output 2). Kódy s touto vlastností se nazývají systematické; ostatní kódy nazývají nesystematické.
Rekurzívní kódy jsou téměř vždy systematické, a naopak nerekurzivní kódy jsou nesystematické. Neplatí to vždy, ale obvykle tomu tak je.
Impulsní odezva, přenosová funkce, a délka kódového omezení
Název konvoluční pochází z toho, že kodér provádí konvoluci vstupního bitového proudu s impulsními odezvami kodéru:

kde je vstupní posloupnost, je posloupnost z výstupu a je impulsní odezva pro výstup .




Konvoluční kodér je diskrétní lineární časově invariantní systém. Každý výstup kodéru může být popsán určitou přenosovou funkcí, která je blízce příbuzná generujícím polynomům. Impulsní odezva je spjata s přenosovou funkcí prostřednictvím Z-transformace.
Přenosové funkce prvního (nerekurzivního) kodéru jsou:



Přenosové funkce druhého (rekurzivního) kodéru jsou:


Definujme jako


kde, pro libovolnou racionální funkci ,

- .

Pak je maximální stupeň polynomu , a délka kódového omezení je definována jako . V prvním příkladu je délka kódového omezení 3, ve druhém 4.


Trellis diagram
Konvoluční kodér je konečný automat. Kodér s n binárními buňkami bude mít 2n stavů.
Představme si, že kodér (zobrazený na obrázku 1 výše) má hodnotu '1' v levé paměťové buňce (m0) a '0' v pravé (m-1). (m1 není ve skutečnosti paměťová buňka, protože reprezentuje aktuální hodnotu). Tento stav označíme „10“. V dalším kroku může kodér v závislosti na hodnotě vstupního bitu přejít buď do stavu „01“ nebo „11“. Je zřejmé, že ne všechny přechody jsou možné (např. dekodér nemůže přejít ze stavu „10“ do „00“, ani zůstat ve stavu „10“).
Všechny možné přechody mohou být zobrazeny takto:

Skutečná zakódovaná posloupnost může být reprezentována jako cesta tímto grafem. Příklad jedné z možných cest je zobrazen červeně.
Tento diagram znázorňuje postup dekódování: pokud přijatá posloupnost nevyhovuje grafu, znamená to, že byla přijata s chybami, a musíme vybrat nejbližší opravnou posloupnost (která grafu vyhovuje). Tuto myšlenku využívají skutečné dekódovací algoritmy.
Volná vzdálenost a distribuce chyb
Volná vzdálenost (d) je minimální Hammingova vzdálenost mezi různými zakódovanými posloupnostmi. Opravná schopnost (t) konvolučního kódu je počet chyb, které mohou být kódem opraveny. Lze ji vypočítat jako

Protože konvoluční kód nezpracovává bloky, ale proud bitů, hodnota t se týká množství chyb, které se nacházejí „blízko“ sebe. To znamená, že u skupin chyb, které jsou relativně daleko od sebe, lze opravit více skupin t chyb.
Volná vzdálenost může být interpretována jako minimální délka chybné skupiny („burst“) na výstupu konvoluční dekodéru. Při návrhu kódů zřetězených s vnitřním konvolučním kódem, je nutné brát v potaz, že se chyby objevují ve skupinách. Obvyklým řešením tohoto problému je provádět prokládání dat před konvolučním kódováním, takže vnější blokový kód (obvykle Reedovy–Solomonovy kódy) může většinu chyb opravit.
Dekódování konvolučních kódů
Existuje několik algoritmů pro dekódování konvoluční kódů. Pro relativně malé hodnoty k, se univerzálně používá Viterbiho algoritmus protože poskytuje výkonnost maximální věrohodnosti a je vysoce paralelizovatelný. Viterbiho dekodéry lze jednoduše implementovat VLSI hardwarem nebo softwarově na procesorech s instrukční sadou SIMD.
Kódy s větší délkou kódového omezení jsou praktičtěji dekódovány libovolným z několika algoritmů sekvenčního dekódování, z nichž nejznámější je Fanoův algoritmus. Na rozdíl od Viterbiho dekódování, sekvenční dekódování nepracuje s maximální věrohodností, jeho složitost však roste s délkou kódového omezení pouze pomalu, což umožňuje používání silných kódů s velkou délkou kódového omezení. Tyto kódy se používaly při programu Pioneer kosmických letů k Jupiteru a Saturn na začátku 70. let 20. století, ale pak byly nahrazeny kratšími kódy s Viterbiho dekódováním, obvykle zřetězenými s rozsáhlými Reedovy–Solomonovými kódy, které činí křivku celkové bitové chybovosti strmější a dosahují extrémně nízkého podílu zbytkových nedetekovaných chyb.
Jak Viterbiho tak sekvenčně dekódování algoritmy vrací tvrdá rozhodnutí: bity, které vytvářejí nejpravděpodobnější kódové slovo. Přibližná míra confidence může být přidána ke každému bitu použitím Viterbiho algoritmu s měkkým výstupem. Měkká rozhodnutí pro každý bit využívající Maximum posteriori (MAP) mohou být získány pomocí BCJR algoritmu.
Oblíbené konvoluční kódy
Velmi oblíbený konvoluční kód s Viterbiho dekódováním používaný například v programu kosmických sond Voyager má délku kódového omezení k=7 a poměr r=1/2.
- Větší délkou kódového omezení poskytují výkonnější kódy, ale protože složitost Viterbiho algoritmu roste exponenciálně s délkou kódového omezení, tyto výkonnější kódy se používají spíše jen pro vesmírné sondy, kde je složitost dekodéru bohatě vynahrazena vyšší výkonností kódu.
- Mars Pathfinder, Mars Exploration Rover a sonda Cassini k Saturnu používají k 15 a poměr 1/6; tento kód má asi o 2 dB lepší výkonnost než jednodušší kód k=7 za cenu 256násobného zvýšení složitosti dekódování v porovnání s kódy používanými v programu kosmických letů Voyager.
Punctured konvoluční kódy
Zúžení kódu (anglicky puncturing) je technika používaná pro vytvoření kódového poměru m/n ze „základního“ kódu s nižším poměrem (např. 1/n). Toho se dosáhne vypuštěním některých bitů z výstupu kodéru. Bity se vypouštějí podle puncturing matice. Nejčastěji se používají následující puncturing matice:
| Kódový poměr | Puncturing matice | Volná vzdálenost (pro standardní konvoluční kód NASA s K=7) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1/2 (No perf.) |
|
10 | ||||||||||||||
| 2/3 |
|
6 | ||||||||||||||
| 3/4 |
|
5 | ||||||||||||||
| 5/6 |
|
4 | ||||||||||||||
| 7/8 |
|
3 |
Pokud například chceme vytvořit kód s poměrem 2/3 použitím příslušné matice z tabulky výše, musíme brát výstup základního kodéru a vysílat každý druhý bit z první větve a každý bit z druhé. Určité pořadí vysílání je definováno příslušným komunikačním standardem.
Punctured konvoluční kódy se široce používají při družicové komunikaci například u systému Intelsat a pro digitální televizní vysílání.
Punctured konvoluční kódy se také nazývají anglicky „perforated“.
Turbo kódy: náhrada za konvoluční kódy
Místo jednoduchých konvoluční kódů s Viterbiho dekódováním se nyní častěji používají turbo kódy, což je nová třída iterovaných krátkých konvolučních kódů, které se více přibližují teoretickým mezím daným Shannonovým teorémem a přitom jejich dekódování je mnohem jednodušší než Viterbiho algoritmus pro dlouhé konvoluční kódy stejné výkonnosti. Jejich zřetězením s vnějším algebraickým kódem (např. Reedovým–Solomonovým) odstraňuje problém s chybovým prahem, který je nedílnou vlastností turbo kódů.
Implementace
Program MATLAB obsahuje podporu konvolučních kódů. Například kodér na obrázku 1 může být implementován takto:
G1 = 7;% 7 osmičkově je binárně 111 n1 = m1 + m0 + m-1
G2 = 3;% 3 osmičkově je binárně 011 n1 = m0 + m-1
G3 = 5;% 5 osmičkově je binárně 101 n1 = m1 + m-1
constraintLen = 3; % Délka kódového omezení
% Vytvořit trellis, který reprezentuje konvoluční kód
convCodeTrellis = poly2trellis(constraintLen, [ G1 G2 G3 ]);
uncodedWord = [1 ];
codedWord1 = convenc(uncodedWord, convCodeTrellis)
uncodedWord = [1 0 0 0];
codedWord2 = convenc(uncodedWord, convCodeTrellis)
Výstup je následující:
codedWord1 =
1 0 1
codedWord2 =
1 0 1 1 1 0 1 1 1 0 0 0
Bity prvního výstupního proudu jsou na pozicích 1, 4, 7, ..., 3k+1, ... výstupního vektoru codedWord, bity druhého proudu na pozicích 2, 5, ... ,3k+2 , ... a bity třetího proudu na pozicích 3, 6, ..., 3k, ...
Implicitně se počáteční stav inicializuje samými nulami.
Odkazy
Reference
V tomto článku byl použit překlad textu z článku Convolutional code na anglické Wikipedii.
Souvisejí články
- Konvoluce
- Kvantový konvoluční kód
Externí odkazy
- Teorie informace, inference, a učící algoritmy, On-line učebnice, jejíž autor David J.C. MacKay diskutuje konvoluční kódy v kapitole 48.
- Stránka věnovaná kódům pro opravu chyb