Vzorkování populace (epidemiologie)
Vzorkování populace (anglicky population sampling) je epidemiologická metoda, kdy se hledá nemoc v populaci, stanovuje promoření (jaká je prevalence). Kontrolní program (control program), stanovuje přesný postup na odběr vzorku pro depistáž konkrétní nemoci v populaci. Kontrolní program musí vydat stát. Pro každou nemoc je jiný. Celostátně se kontroluje jen několik málo nemocí. U ostatních nemocí se provádí depistáž (průzkum) nemoci v populaci, respektive epidemiologické studie na výskyt nemoci.
O kvalitě studie vypovídá její přesnost (precision=1-α) a síla (power=1-β) viz Chyby typu I a II.
Pojmy používané epidemiology při vzorkování populace
Celková populace jsou všechny druhy vnímavé k dané nemoci na konkrétním území. Například u paratuberkulózy jsou to všichni savci. Pokud se jedná o větší území jako je například stát či kontinent, pak se celková populace nikdy netestuje. Pokud se jedná jen o kravín či malý uzavřený region, bývá celková populace jediný druh s přesným počtem jedinců. U celkové populace stanoví člověk region, popíše v něm výskyt vnímavých druhů, spočítá jedince.
Studovaná populace (Study population) je ta část celkové populace, u které lze danými testy efektivně nemoc objevit. Na rozlišení studované populace od zbytku populace se provádějí epidemiologické studie, výsledek se vypočítá. Například u nemoci paratuberkulóza je studovaná populace zvířata nad 2 roky stáří. Tato nemoc má totiž inkubační dobu 3-6 let, pokud budeme testovat mladá zvířata, vyjdou výsledky vždy negativně (výjimka je souběh více nemocí u jedince). Je to obdobné, jako by se stařecká senilita testovala u dětí ve školce a následně jsme stát vyhlásili za prostý nemoci.
Velikost studované populace se může změnit objevením nových testů, které dokáží prokázat nemoc dříve či přesněji.
Kdo patří do studované populace, je dáno objektivními zákonitostmi, které umí odhalit jen epidemiologická studie. (Není možné, aby studovanou populaci stanovil úředník či epidemiolog na základě úvahy.)
Cílová populace (Target population) je ta část populace, která je v riziku. Týká se jednoho druhu a jen těch jedinců, u kterých by se nemoc mohla vyskytnout. U paratuberkulózy je cílová populace například mléčný skot. Nebo jiná cílová populace je masný skot. Další jsou například ovce (ty s mléčnou užitkovostí i produkcí vlny společně). Další kozy (všechny plemena společně). Celková populace se dělí na mnoho cílových populací.
Cílová populace má rizika nemoci stejná, má společný kontrolní program, společnou metodu ozdravování.
Testovaná populace je menší nebo rovna cílové populaci, stanovuje tu část populace, kterou jsme schopni pro daný účel efektivně testovat. Testovat všechny je drahé, často kontraproduktivní. Z populace určené k testování se vybere jen její malá část (vzorek populace), ta musí být pro daný účel reprezentativní.
Vzorek populace je ta část populace, která je testována. Správně se má vybrat ze studované populace tak, aby co nejvíce reprezentoval cílovou populaci. Důležitá je velikost vzorku (počet odebraných jedinců) a způsob výběru. Obecně platí, že velikost vzorku má být co největší (viz Chyby typu I a II) a způsob výběru jednoduchý náhodný (simple random sampling), ale to neplatí vždy.
- Pokud je chov nakažený například paratuberkulózou, pak jsou testována všechna zvířata, pozitivní se posílají na jatka. Z hlediska chovatele je cílová populace, testovaná populace i vzorek populace v tuto chvíli stejný.
- Po ozdravení stáda, se kontroluje pouze nulový výskyt nemoci ve stádě, stačí testovat jen část jedinců dle specificity a senzitivity laboratorního testu (viz validita laboratorního testu). Například kultivací trusu kolem 300 kusů ze stáda (viz tabulka statisticky významných počtů v kapitole paratuberkulóza).
- Jak riziko výskytu nemoci ve stádě klesá, přechází se k testování minimálního statistického vzorku (zpravidla 30 kusů ze stáda).
- Pokud se přijme teritoriální princip, pak se po ozdravení regionu přestanou stáda testovat. Stát financuje nahodilé testování (haphazard sampling), kdy se testují jen zvířata nad 2 roky stáří na jatkách, to stačí k průkazu, že se nemoc do populace nevrátila.
Správně stanovit vzorek populace je základem pro kontrolní program.
Rámec vzorků (Sampling frame) je manažerský pojem. Manažer stanoví na základě finančních a vědeckých údajů, kdo konkrétně bude do testu zahrnut, respektive stanoví pravidla, podle kterých budou jedinci vybíráni. Rámec je menší nebo roven studované populaci (study population), respektive by měl být shodný se správně stanoveným vzorkem populace. Obecně platí, že čím více se testuje jedinců, tím větší je průkaznost celého testování.
Pokud se stanoví příliš velký rámec vzorků, pak se plýtvá penězi i zdroji, pokud příliš malý, pak může celé testování dojít k chybným závěrům, je lepší ho vůbec neprovádět.
Skutečná velikost vzorku (Sampling size) je laboratorní pojem. Je to počet vzorků zaslaných do laboratoře a otestovaných s pozitivním či negativním výsledkem. Měl by odpovídat rámci vzorku, ale skutečnost bývá jiná (některé vzorky se rozbijí, někteří jedinci zmizí, něco se nezdaří otestovat s jednoznačným výsledkem). Tento údaj je společně s počty pozitivních a negativních výsledků klíčový pro jakékoli další výpočty.
Frakce vzorku (Sampling fraction) je konečný ukazatel, který vypovídá, jak moc je náš konkrétní test průkazný. Obecně platí, že čím je frakce menší, tím menší má vypovídající hodnotu. Frakce vzorku je poměr mezi vzorky vyhodnocenými laboratoří (sampling size) a populací, která je hodnocena. V čitateli frakce je vždy počet vyhodnocených vzorků, ve jmenovateli může být cílová populace (target population), studovaná populace (study population) nebo rámec vzorků (sampling frame). U frakce je tedy nutno říct, z jaké populace se počítá. Malá frakce vzorku usvědčuje vědeckou studii z nevědeckosti, velká frakce má průkaznou sílu, kterou nelze zpochybnit.
Statisticky správný způsob výběru vzorků populace
V populaci, kde se předpokládá normální rozdělení dat (Interval spolehlivosti), se vzorky vybírají dvojím způsobem: náhodný výběr vzorků (probability sampling) a cílený výběr vzorků (non probability sampling).
Cíleně se hledá nemoc, ale náhodně se určuje její výskyt v populaci.
Populaci je třeba vnímat jako celistvou. Pokud existují rozdíly v populaci či metodice výzkumu, je vhodné populaci rozdělit dle smysluplných hledisek. Základní dělení je podle dvou kritérií: Skupiny (Cluster) a vrstvy (Strata). Skupiny dělí populaci dle regionů (např. kraje, okresy, územně celistvá hospodářství), vrstvy podle pohlaví, stáří, plemene či užitkovosti.
Dělit lze podle mnoha dalších kritérií, ale vždy to musí mít pro zkoumání nemoci nějaký předem definovaný význam. Přiřadit ke každému testovanému jedinci množství deskriptivních dat a uložit je, umožňuje hodnotit populaci i dodatečně. Mnoho let po provedení prvotní studie lze provádět srovnávací studie s ohledem na pohlaví, věk, sociální postavení, zaměstnání, zdravotní predispozice. U zvířat lze zkoumat ještě více ukazatelů spojených s dědičností, plemenem, užitkovostí, způsobem chovu.
Dělení má za úkol chyby zmenšit. Pokud se dělením chyby zvětší, je nutno výsledky přepočítat nebo dělení anulovat.
A: Náhodné výběry
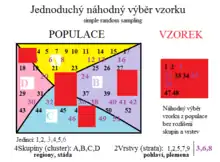
1.Jednoduchý náhodný výběr vzorků (Simple Random Sampling). Každý jedinec v populaci má stejnou šanci, že bude vybrán, stejně tak každá kombinace jedinců má stejnou šanci výběru. Tento způsob výběru je nejčastější, nejpoužívanější, často jediný správný.
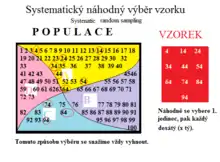
2. Systematický náhodný výběr (Systematic Random Sampling). Náhodný výběr prvního jedince, každý další pak v určitém intervalu. Díky tomu má sice každý jedinec v populaci stejnou šanci být vybrán, ale kombinace jedinců mají různé šance. Některé skupiny jsou díky systému odběru vzorků více testovány, jiné méně či dokonce vůbec. (Pokud bychom prvního jedince nevybrali náhodně, je celý odběr cílený.) Tomuto způsobu odběru se vždy snažíme vyhnout!

3.Vrstevnatý náhodný výběr vzorku (Stratified Random Sampling). Test se snaží odstranit chybu jednoduchého náhodného výběru vzorků, pokud se populace skládá z odlišných skupin. Cílem je testovat všechny skupiny, žádnou neminout. Testy rozpočítáme tak, aby v každé skupině bylo odebráno stejné množství vzorků (v každé skupině se vybírají například dva testy, ať je její velikost jakákoli). Vhodné pro zkoumání zamoření velkých členitých území.

4.Náhodný skupinový výběr vzorku (Cluster Random Sampling). Populace je rozdělena do skupin (například dle regionů), náhodně je vybrána jedna skupina a otestována. Pokud jsou skupiny srovnatelné, získají se data na úrovni testu celé populace. Pokud jsou skupiny odlišné, je toto testování nevhodné. Vhodné pro zkoumání zamoření malých homogenních území.
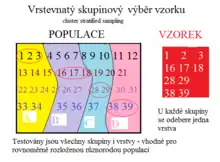
5.Vrstevnatý skupinový výběr vzorku (Cluster Stratified Sampling). Snahou je zmenšit chybu testování pouze jedné skupiny tak, že se populace rozdělí na vrstvy, ty se testují odděleně. Z každé skupiny (regionu) se vybere jedna vrstva (například z jednoho regionu pouze mladí muži, z druhého staří, ze třetího mladé ženy, ze čtvrtého staré), testují se všechny regiony i vrstvy náhodně. Výsledek je zatížen menší chybou, než kdyby se testovala celá jedna skupina (jeden region), ale ostatní vůbec ne.
6.Komplex vícečetných náhodných výběrů vzorků (Multi Stage Sampling). Jsou stanoveny geografické skupiny (Clusters), jsou vytyčeny vrstvy (Strata). Skupiny jsou vybírány náhodně pro jednotlivé vrstvy a to ve více stupních testování. Existuje více variant tohoto testování. Snad nejznámější je průzkum veřejného mínění, kdy se náhodnými telefonáty či rozesíláním dotazníků získávají validní statistická data.
B: Cílené výběry
- Poměrný výběr vzorků (Quota). Stanoví se počet jedinců, který bude odebrán (například 100 vzorků) nebo procento z populace (např. každý desátý či 10 % z populace). Takovýto výběr není náhodný, například při odběru 100 vzorků testujeme prvních 100 jedinců, kteří se dostaví. Jsou to tedy například ti nejsilnější, nebo ti, kteří přijeli ranním vlakem z určité oblasti, nebo ti nejmladší atd. U testování každého např. 10. získáme jen průřez cíleně vybraného vzorku. Takovýto výběr není náhodný, může být zatížen značnou systematickou chybou (bias). Pro epidemiology je vždy chybný.
- Nahodilé testování (Haphazard Sampling) neboli příležitostné (Convenience, Accidental). Obecně se jedná o test jedince, nikoli populace. Nahodile je vybrán jedinec, který je testován (na ulici, ve třídě atd.). Takovýto test je zatížen značnou chybou (bias sampling), ale jeho provedení bývá pohodlné. Pozitivní nález sice dokáže odhalit nemoc v populaci, ale negativní nález má mizivou vypovídající hodnotu.
- Účelové testování (Purposive) se provádí s konkrétním cílem, většinou odhalit nemoc. Cíleně vybereme jedince s určitými symptomy, provedeme testy. Tento test nelze provádět jako průkaz neexistence nemoci.
Příklady z veterinární epidemiologie
Náhodný výběr se zjednodušeně považuje za průkazný, cílený za neprůkazný.
V praxi se provádí všechny možné kombinace průkazného i neprůkazného testování. Závěry, které ze vzorkování plynou, se posuzují na základě statistiky.
Cílem je mít vysokou přesnost (precision), respektive 1-α, ta závisí na statistické chybě I. typu , a současně velkou statistickou sílu (power), respektive 1-β, ta závisí na statistické chybě II typu . Viz Chyby typu I a II.
Tabulka příkladů několika málo metod výběru vzorku populace ve veterinární praxi
| Charakteristika populace | Účel testování | Metoda výběru vzorku z populace |
|---|---|---|
| homogenní | jedno stádo skotu testované na TBC | Jednoduchý náhodný výběr (Simpe Random Sampling) |
| rovnoměrné vrstvení populace | dvě stáda skotu stejné velikosti i užitkovosti – prevalence mastitid dle užitkovosti | Jednoduchý vrstevnatý výběr (Simple Stratified Sampling) |
| vrstvení populace s dvojí odlišností, která je v proporci | dvě stáda skotu odlišné velikosti i užitkovosti – prevalence mastitid dle užitkovosti | Poměrný vrstevnatý výběr (Proportional Stratified Sampling) |
| skupiny jsou jasně charakterizované, ale heterogenní | státní laboratoř obdrží vzorky z chovů, porovnává procento pozitivních | Skupinový výběr (Cluster Sampling) |
| skupiny jsou charakterizované, dělené do kategorií | státní laboratoř porovná procento pozitivních dle chovů a kategorie zvířat (odchovna býků, kravín, teletník) | Skupinový vrstevnatý (Cluster Stratified Sampling) |
| populace bez rámce vzorku | laboratoř zkoumá ze 30 vzorků od každého chovatele stádovou prevalenci paratuberkulózy | Mnohočetný výběr vzorků (Multistage Sampling) |
| celá republika | na jatkách se testují poražené krávy na BSE (bovinní spongiformní encefalopatie) neboli nemoc šílených krav, dokazuje se nulový výskyt v ČR | Nahodilé testování (Haphazard Sampling) |
Testování provádí chovatel, učiní z něj svůj závěr. Laboratoř získá data od chovatelů v regionu, vyvozuje odlišné závěry. Centrálně se výsledky z více laboratoří i chovů analyzují, získávají se jiné závěry. Například chovatel zjistí, zda má ve svém chovu paratuberkulózu. Laboratoř vypočte testovanou prevalenci paratuberkulózy v regionu. Epidemiologové udělají mapu výskytu paratuberkulózy v zemi, navrhnout národní kontrolní program.
Související články
Externí odkazy
- Principy epidemiologie na Centers for Disease Control and Prevention (anglicky)
- Základy epidemiologie na www.researchgate.net (anglicky)
- Dirk Pfeiffer (Londýnská universita) – Úvod do veterinární epidemiologie https://www.researchgate.net/publication/305279557_Introduction_to_Veterinary_Epidemiology
- https://web.archive.org/web/20170809101742/http://www.cnstn.rnrt.tn/afra-ict/ICT%20TOOLS%20RAF0026/PESTE%20BOVINE/References/1006.pdf