Vyhledávání Google
Vyhledávání Google je v současnosti nejpoužívanější internetový vyhledávač, který vlastní společnost Google.
 | |
| URL | google.com |
|---|---|
| Komerční | ano |
| Charakter stránky | webový vyhledávač |
| Registrace | nepovinná |
| V jazyce | Python, C, C++[1] |
| Vlastník | |
| Spuštěno | 15. září 1997 |
Vyhledávač původně navrhli Sergey Brin a Larry Page v rámci svého výzkumu na Stanfordově univerzitě, aby ověřili funkčnost svého algoritmu pro ohodnocování webových stránek PageRank. Záhy se ukázalo, že kvalita jeho výsledků natolik převyšovala tehdy dostupné vyhledávače, že je Google v krátké době téměř převálcoval.
Kromě řazení výsledků podle PageRanku bylo v Googlu novinkou i kladení důrazu na vyhledávání frází (takže se nestávalo, že víceslovný dotaz vrátil stránky, kde se tato slova vůbec nevyskytovala pohromadě) a ukládání plného textu indexovaných stránek (které umožňovalo u výsledných stránek rovnou zobrazovat relevantní fragmenty textu).
Architektura
Údaje uvedené v této kapitole se vycházejí z informací uvedených v popisu prototypu vyhledávače z roku 1998. Protože je v současnosti Google komerčním produktem, je o jeho vnitřních funkcí známo mnohem méně. Lze ale předpokládat, že základní rysy jsou shodné s prototypem.
Crawler stahuje ze sítě dokumenty, které mu určí URL Server. Crawlerů běží několik paralelně, každý najednou udržuje stovky otevřených spojení k webserverům, aby nebyl zdržován čekáním na jejich odpovědi. Vzhledem k variabilitě internetového obsahu musí být crawler velice robustní a odolný vůči atypickým případům, jako jsou např. online hry.
Store server dokumenty od Crawleru komprimuje a ukládá do Repository. Každé stránce je přiřazen identifikátor docID (ten se generuje, kdykoliv je získáno nové URL).
Indexer má několik úkolů:
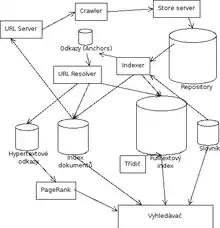
- Parsuje dokumenty do sady tzv. hitů – každý hit zaznamená výskyt slova v dokumentu společně s jeho pozicí, kapitalizací a relativní velikostí písma, jakým je napsáno. Hity jsou ukládány do “zásobníků” (barrels), které tak tvoří částečně setříděný index.
- Z parsovaných dokumentů také filtruje odkazy (anchors), které se ukládají do k tomu určeného souboru. U každého odkazu je uloženo, odkud a kam vede, a také text odkazu.
URLresolver dále zpracovává soubor s odkazy na URL – převádí relativní cesty na absolutní URL a na docID. Tyto informace ukládá do indexu dokumentů, který mimo jiné slouží jako zdroj dat pro URL Server. Texty odkazu také přidává do indexu k dokumentu, na nějž směřují. Informace o vzájemných odkazech se používají pro výpočet PageRanku.
Třídič (sorter) přetřiďuje index do zpětného indexu – hity místo podle docID řadí podle wordID (ID slova, které se používá v hitu). Třídič zároveň vytváří seznam použitých wordID a jejich četností, z nichž je programem DumpLexicon vytvořen nový slovník (lexicon).
Vyhledávač (searcher) běží na webserveru a s použitím slovníku, zpětného indexu a PageRanků odpovídá na dotazy.
Datové struktury
Pro dosažení co nejrychlejší odezvy jsou formáty uložených dat optimalizovány tak, aby byly přístupy na disk co nejřidší (v dnešním počítači je disk zdaleka nejpomalejší částí – přečtení informace trvá okolo 10ms, což je řádově milionkrát pomalejší než přístup do paměti).
Repository
Repository obsahuje úplný HTML kód každé zaindexované webové stránky. Stránky jsou uloženy zkomprimované pomocí knihovny zlib (přestože nabízí horší kompresní poměr než bzip, byla upřednostněna pro svou rychlost) jedna za druhou, přičemž před každou je uloženo její docID, délka a URL. K přístupu k repository nejsou nutná žádná další data, takže v případě potřeby je možné z jeho kopie rekonstruovat všechny ostatní struktury.
Index dokumentů
V indexu dokumentů (document index) jsou uloženy informace o každém dokumentu (stránce). Používá strukturu ISAM (Indexed Sequential Access Method), v níž jsou všechny záznamy pevné délky uloženy sekvenčně za sebou, přičemž hashovací tabulky pro urychlení přístupu podle docID jsem uloženy mimo hlavní data.
Každá položka obsahuje aktuální stav dokumentu, ukazatel do repository, kontrolní součet souboru a různé statistiky. Pokud byl dokument rozparsován, je v položce také odkaz do souboru docinfo, v němž je zaneseno URL dokumentu a jeho titulek. V opačném případě odkazuje do URLlistu, který obsahuje pouze URL. Motivací tohoto řešení byla kompaktnost datové struktury a schopnost načíst záznam v jednom přístupu na disk.
Také existuje soubor pro převod URL na docID – setříděný seznam hashů URL a odpovídajících docID. Pro převod se spočítá hash URL a v tabulce se vyhledá příslušné docID. Pomocí slévaní je možné najít docID pro více URL najednou; tuto techniku používá URLresolver.
Slovník
Slovník je implementován jako sekvenční seznam slov oddělených nulami a hašovací tabulkou s ukazateli do ní. U prototypu vyhledávače slovník obsahoval 14 miliónů slov a vešel se do 256 MB operační paměti (což je klíčové pro jeho rychlou použitelnost). Slovník je zdrojem problémů při paralelizaci indexování – při běžném provozu musí být indexery schopny přidávat do slovníku nová slova. Tento problém byl vyřešen jeho zafixováním: nálezy nových slov se zapisují do zvláštního souboru, který na konci zpracuje poslední indexer. Vzhledem k velikosti slovníku je tento dodatečný soubor relativně malý, a jeho zpracování tudíž nezabere mnoho času.
Indexy
Seznamy hitů obsahují údaje o výskytu slov v dokumentech, a to včetně informací o pozici, velikosti písma a kapitalizaci. Protože tvoří většinu obsahu indexu i zpětného indexu, je důležité je ukládat co možná nejefektivněji; Google pro uložení hitu používá dva bajty. Hity se rozlišují na obyčejné a důležité, přičemž do důležitých se počítají slova obsažená v URL, titulku, textu a odkazů a v meta tazích.
Ve vlastních indexech se před seznam hitů ukládá jeho délka. Aby se dále ušetřilo místo, je délka zkombinovaná s wordID (resp. docID ve zpětném indexu), čímž pro délku zbývá 8, resp. 5 bitů. Pokud je hitů více, obsahuje pole pro délku escape kód, a samotná délka je uložena v následující dvou bajtech. Index se rozdělen do skupiny kontejnerů (barrels; prototyp používá 64), přičemž každý kontejner pokrývá určitou část wordID – index je už tedy částečně setříděn. Pokud dokument obsahuje slova, jejichž wordID spadají do daného kontejneru, je do kontejneru přidáno jeho docID, následované příslušnými wordID a jejich hitlistu. To sice vyžaduje o něco více prostoru kvůli duplikovaným docID, ale zato významně zjednodušuje náročnost úkolu pro třídič(e). Současně umožňuje místo celých wordID (které mají 32 bitů) ukládat jen rozdíl od minimálního wordID v rozsahu – tím pádem pro wordID stačí jen 24 bitů a 8 je možno použít pro počet hitů.
Zpětný index se skládá ze stejných kontejnerů jako index normální; kontejnery jsou jen přetříděny podle wordID. Pro každé platné wordID je pak do slovníku doplněn odkaz do kontejneru s odpovídajícím seznamem dokumentů, které slovo obsahují. Důležitou otázkou je, v jakém pořadí uváděn docID v tomto seznamu. Jednoduchým řešením je řadit je dle docID – to umožňovalo snadné slučování seznamů při zpracování víceslovných dotazů. Další možností je řadit je dle PageRanku dokumentů. Potom jsou odpovědi na jednoslovné dotazy trivialitou a je pravděpodobné, že i nejlepší odpovědi na dotazy víceslovné budou blízko začátku. Google používá kompromisní řešení: má dvě sady kontejnerů: “krátká” obsahuje pouze hity v titulcích a odkazech, “dlouhá” je úplná. Při prohledávání se potom nejprve prověří první sada, a teprve při příliš malém počtu nalezených výsledků se zkoumá druhá.
Vyhledávání
Ohodnocování výsledků dotazů nezahrnuje pouze PageRank, ale i pozici hledaného slova v dokumentu. Hodnocení v Google byla navrženo tak, aby žádný jednotlivý faktor nemohl mít příliš velký vliv na výsledek.
Je-li vyhodnocován jednoslovný dotaz, zkoumá se seznam hitů pro dané slovo. Google má u každého hitu uložen i jeho druh (titulek, text odkazu, URL, obyčejný text velkým písmem, obyčejný text malým písmem, …); každému druhu je pak přiřazena určitá váha. Na tyto váhy lze nahlížet jako na vektor. Stejně tak je ohodnocen počet hitů pro každý druh – ohodnocení na začátku roste lineárně s počtem, ale pak se závislost “narovnává”, takže pokud počet výskytů překročí určitou mez, ohodnocení dále neroste.
Skalární součin vektoru vah a vektoru ohodnocení počtu výskytů tvoří ohodnocení relevance dokumentu, jehož kombinace s PageRankem určí konečné pořadí dokumentu ve výsledku.
Pro víceslovné dotazy je situace komplikovanější – musí se procházet několik seznamů hitů najednou, aby bylo možné ohodnocovat výsledky na základě vzdálenosti jednotlivých výskytů. Pro každou nalezenou skupinu hitů je spočítána vzdálenost výskytu všech nalezených slov v textu dokumentu (nebo odkazu), které je přiřazeno jedno z deseti ohodnocení. Počty výskytů se potom nepočítají jen pro různé druhy hitů, ale i pro každou dvojici druh-vzdálenost. Oba tyto údaje jsou převedeny na příslušná ohodnocení, a jejich skalární součin tvoří ohodnocení relevance dokumentu.
Do vyhledaváného výrazu je možné zadat operátory:
- uvozovky – vyhledání přesného výrazu
- OR – logické NEBO,
- AND – logické A,
- minus, NOT – výraz, který se ve vyhledaném dokumentu nesmí nacházet,
- hvězdička – náhradní výraz za různá slova mezi zadanými slovy,
- závorky – určují prioritu při zpracování výrazů s AND a OR,
- dvě tečky – definují interval.[2]
Současný Google
O technologiích, které používá současné Vyhledávání Google, není známo mnoho: Google jako komerční firma uvolňuje méně informací, než v době, kdy šlo o akademický projekt.
Jisté je, že celý vyhledávač je rozdělen do několika tzv. datacenter, rozmístěných po celém světě. Datacentra zodpovídají dotazy nezávisle, dotazy se mezi ně rozdělují pomocí rotace DNS záznamů (jmenné servery Google na každý dotaz vrací vstupní IP adresu jiného datacentra, vybírá je na základě geografické polohy uživatele a vytížení jednotlivých center).
Datacentrum se skládá z velkého počtu „běžných“ PC, používajících upravenou verzi operačního systému Linux. Takové počítače které mají lepší poměr cena/výkon než vysoce výkonné (ale současně velmi drahé) servery. V prvním čtvrtletí 2003 sahala paleta konfigurací od jednoprocesorových Intel Celeron 533 MHz po dvouprocesorové Intel Pentium III 1,4 GHz, s jedním nebo více 80 GB IDE disky. Podle odhadů z dubna 2004 se v datacentrech nachází přibližně 63 tisíc počítačů, což činí cluster Googlu nejvýkonnější na světě.
Spolehlivost je zajištěna na softwarové úrovni – při výpadku je počítač vyřazen z clusteru a jeho úlohy převezme jiný.
Zdroje příjmů Google
Popularita Google umožnila jeho zakladatelům založit inzertní systém Google AdWords a Google AdSense. AdWords je v podstatě administrátorské rozhraní, které umožňuje inzerentům, kteří mají u Google založený účet a na něm vloženy finanční prostředky, vytvořit inzerát, který se pak bude zobrazovat u fulltextových výsledků označený jako sponsored listings. Tento malý inzerát je svázán pevnými pravidly – má limitovaný rozsah a i jeho obsah je omezen. Inzerenti si pro každý inzerát stanoví i tzv. keywords, čili klíčová slova, po jejichž zadání do vyhledávače Google nebo některé z jeho přidružených stránek, se zobrazí právě onen inzerát. Inzerent platí Google částku, kterou si sám stanoví (min. částku stanoví Google), za každé kliknutí na jeho inzerát. Pořadí inzerátů je stanoveno systémem na základě kombinace několika faktorů – ceny za klik (cost per click) a míry prokliků (click through rate).
Zpracování dotazu
Po příchodu do datacentra je HTTP požadavek přesměrován hardwarovým load-balancerem (prvkem vyrovnávajícím zátěž) na jeden z webových serverů (Google Web Server – GWS). Webserver pak koordinuje zpracování dotazu a formátuje výsledek do HTML odpovědi, kterou na závěr posílá uživateli.
První fází zpracování dotazu je vyhledání odpovídajících dokumentů ve zpětném indexu. Princip je v zásadě stejný jako u prototypu, jediným rozdílem je velikost zpětného indexu. Aby bylo dosaženo adekvátní rychlosti, je zpětný index rozdělen na větší počet fragmentů (shards), přičemž každý pokrývá náhodně vybranou podmnožinu dokumentů. Požadavky na každý fragment obsluhuje více počítačů (jejich sada se označuje jako pool). Při zpracování požadavku na nějaké slovo pak load balancer pošle dotaz jednomu stroji pro každý fragment. Ten vyřídí svou část úkolu, a spojené odpovědi dají celkový výsledek pro celý index v čase, který zabere prohledání jednoho fragmentu.
Pokud jeden z počítačů selže, load balancer na něj přestane směrovat dotazy a další prvky obsluhující cluster se jej pokusí oživit, případně jej nahradí jiným strojem. V průběhu poruchy je kapacita systému snížena úměrně podílu celkové kapacity, který počítač představoval.
Výsledkem prohledávání je setříděný seznam docID. Další fází zpracování je přiřadit ke každému docID URL, titulek a úryvek textu relevantní k dotazu. K tomu slouží dokumentové servery (docservers), které najdou příslušný záznam v repository a získají z něj potřebné informace. Rychlost odezvy je řešena stejným způsobem jako u vyhledávání v indexu: repository je rozdělen na více fragmentů, každý z nich obsluhuje pool serverů a požadavky jsou distribuovány load balancerem. Jakmile úryvky a další informace z docserverů dorazí, vyřazují se z výsledků duplicity a provádí se klastrování podle doménového jména.
Kvůli replikaci nutné pro zajištění dostupnosti a rychlosti odezvy tak Google v clusterech dokumentových serverů přechovává několik kopií celého webu.
Zároveň s těmito hlavními aktivitami ještě webserver získává další informace, jako jsou návrhy na možné opravy pravopisu (například při zadání dotazu „Csech Republic“ se kromě výsledků hledání uživateli zobrazí také otázka, zda náhodou neměl na mysli „Czech Republic“) a reklamy cílené na klíčová slova zadaná uživatelem. To vše je následně sloučeno do HTML stránky, která je odeslána zpět uživateli.
Reference
- BRIN, Sergey; PAGE, Lawrence. The Anatomy of a Large-Scale Hypertextual Web Search Engine [online]. Stanfordova univerzita [cit. 2019-09-07]. Dostupné online. (anglicky)
- KILIÁN, Karel. Tipy pro Google: Umí mnohem víc než jen vyhledávat, zkuste některé fígle. Živě.cz [online]. 2019-01-31 [cit. 2019-09-07]. Dostupné online.
Související články
Externí odkazy
 Obrázky, zvuky či videa k tématu Google na Wikimedia Commons
Obrázky, zvuky či videa k tématu Google na Wikimedia Commons - http://www.google.com VyhledáváníGoogle
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
Sergey Brin, Lawrence Page; Computer Networks and ISDN Systems, 30(1998), 107–117. (PDF verze) - Web Search for a Planet: The Google Cluster Architecture
Luiz André Barroso, Jeffrey Dean, Urs Hölzle; IEEE Micro, March-April 2003, 22–28 (PDF verze[nedostupný zdroj])