Trie
Trie nebo prefixový strom je datová struktura, která se používá pro uchovávání dvojic klíč-hodnota, kde klíči jsou obvykle řetězce. Na rozdíl od binárního vyhledávacího stromu, kde se podle hodnoty uzlu rozhoduje, do které větve sestoupit, trie v každém uzlu obsahuje všechny podřetězce, kterými může pokračovat řetězec v dosud prohledané cestě. Všichni následníci uzlu mají společný prefix, který je shodný s řetězcem přiřazeným k danému uzlu. Kořen je asociovaný s prázdným řetězcem. Hodnoty obvykle nejsou asociovány se všemi uzly, ale jen s listy a některými vnitřními uzly, které odpovídají klíčům.
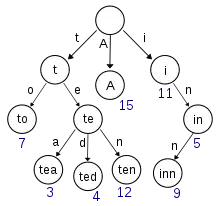
Slovo trie pochází z anglického „retrieval“ – získávání, vyhledávání.
V uvedeném příkladu jsou klíče v uzlech a hodnoty pod nimi. Na trie může být nazíráno jako deterministický konečný automat, ačkoli symbol na každé hraně je často implicitní v pořadí větví.
Přestože je to obvyklé, trie nemusí mít jako klíče textové řetězce. Stejné algoritmy mohou být snadno upraveny, aby sloužily podobným funkcím na seznamech jakékoliv podoby, např. permutace na seznamu číslic, permutace na seznamu tvarů atd.
Výhody a nevýhody trie vzhledem k binárnímu vyhledávacímu stromu
Výhody oproti binárnímu vyhledávacímu stromu:
- Nalezení klíče je rychlejší. Nalezení klíče délky m trvá v nejhorším případě O(m). BVS to trvá O(log n), kde n je počet prvků ve stromě, protože vyhledávání závisí na hloubce stromu, která je logaritmická v počtu klíčů. Jednoduché operace, které používá trie během vyhledávání, jako je indexování pole pomocí znaku, jsou v praxi rychlejší.
- Trie potřebuje méně paměti, pokud obsahuje velký počet krátkých řetězců, protože klíče nejsou uchovávány explicitně, a uzly jsou tak sdíleny klíči se společnými začátky.
- Trie pomáhají při hledání nejdelšího prefixu, kde je úkolem najít klíč sdílející nejdelší možný prefix unikátních znaků.
Konstrukce trie, ať už dávková nebo postupným přidáváním, je implementačně trochu složitější než u binárního vyhledávacího stromu. To platí zvláště při použití optimalizací a optimalizovaných variant.
Užití
Jako náhrada jiných datových struktur
Trie může nahradit hašovací tabulku, oproti které má následující výhody:
- Vyhledání dat v trie je rychlejší v nejhorším případě, tj. O(m), oproti hašovací tabulce s kolizemi O(N), typicky však O(1).
- Nenastávají žádné kolize různých klíčů.
- Datová struktura pro uchovávání kolizních klíčů je potřeba pouze v případě, že více hodnot má přiřazeno totožný klíč.
- Není třeba hašovací funkce nebo její změna při přidávání dalších klíčů.
- Trie může poskytnout abecední řazení záznamů podle klíče.
Má také ale nevýhody:
- Trie může být v některých případech pomalejší než hašovací tabulka při vyhledávání dat, zejména pokud je k nim přistupováno na pevném disku nebo podobných zařízeních, kde je doba náhodného přístupu velká vůči hlavní paměti.
- Trie je často méně paměťově efektivní než hašovací tabulka.
Reprezentace slovníku
Častou aplikací trie je uložení slovníku, např. v mobilních telefonech. To využívá schopnosti trie rychle vyhledávat, vkládat a odstraňovat záznamy.
Trie je také vhodné pro implementaci algoritmů přibližného matchování, jako jsou ty používané v programech pro kontrolu pravopisu.
Algoritmy
Následující pseudokód ukazuje obecný algoritmus zjišťující, jestli je daný řetězec v trie. Pole naslednici obsahuje následníky uzlu, koncový uzel je ten, který obsahuje platné slovo.
function jeVTrie(uzel, klic):
if (klic je prazdny retezec): # výchozí případ
return je uzel koncový?
else: #rekurzivní případ
c = prvni znak v klici #funguje, protože klíč není prázdný
sufix = klic minus prvni znak
naslednik = uzel.naslednici[c]
if (naslednik je prazdny): #nelze rekurze, ale klíč je neprázdný
return false
else:
jeVTrie(naslednik, sufix)
Řazení
Lexikografické řazení skupiny prvků může být provedeno jednoduchým algoritmem založeným na trie:
- Vlož všechny klíče do trie.
- Vrať všechny klíče v trie průchodem preorder, který způsobí, že výstup je ve lexikograficky vzestupném pořadí, nebo postorder, díky němuž bude výstup v sestupném pořadí. Průchod preorder a postorder jsou dva druhy průchodu do hloubky.
Tento algoritmus je formou číslicového řazení.
Trie tvoří základní datovou strukturu burstsortu, v současné době nejrychlejšího známého algoritmu pro řazení řetězců založeném na využití cache.
Paralelní algoritmus pro řazení N klíčů založený na trie je O(1), pokud je N procesorů a klíče mají konstantní horní omezení. Existuje možnost, že klíče mohou kolidovat tím, že mají společné prefixy, nebo jsou identické, což snižuje výhodu rychlosti zpracování více paralelně pracujícími procesory.
Fulltextové vyhledávání
K indexování všech sufixů v textu za účelem rychlého fulltexového vyhledávání může být použit speciální druh trie, sufixový strom. Dalším využitím může být hledání nejdelšího společného prefixu.
Odkazy
Literatura
- DE LA BRIANDAIS, R., 1959. File Searching Using Variable Length Keys. In: [s.l.]: [s.n.]. DOI 10.1145/1457838.1457895. S. 295–298.
- FREDKIN, Edward, 1960. Trie Memory. Communications of The ACM. Roč. 3, čís. 9, s. 490–499. DOI 10.1145/367390.367400.
- KNUTH, Donald, 1997. The Art of Computer Programming. 3. vyd. Svazek 3: Sorting and Searching. [s.l.]: Addison-Wesley. ISBN 0-201-89685-0. Kapitola 6.3, s. 492–512.
- AOE, Jun-Ichi; MORIMOTO, Katsushi; SATO, Takashi, 1992. An Efficient Implementation of Trie Structures. Software—practice and experience. Září 1992, roč. 22, čís. 9, s. 695–721. Dostupné online.
- GONG, Cai-chun; LI, Yang; BAI, Shuo, 2007. An Efficient Double-Array Establishing Algorithm Based on Following-set. [s.l.]: [s.n.]. Dostupné online.
Externí odkazy
 Obrázky, zvuky či videa k tématu trie na Wikimedia Commons
Obrázky, zvuky či videa k tématu trie na Wikimedia Commons - Animace trie ve flashi + implementace
- Cache-Efficient String Sorting Using Copying