Interlingvální strojový překlad
Interlingvální strojový překlad je jeden z klasických přístupů ke strojovému překladu. Při tomto způsobu překladu se text ze zdrojového jazyka (který chceme přeložit) převede do interlingvy, abstraktní reprezentace nezávislé na jazyce. Text v cílovém jazyce se poté vygeneruje z interlingvy. Interlingvální přístup je na poli pravidlového překladu alternativou k přímému a transferovému přístupu. .
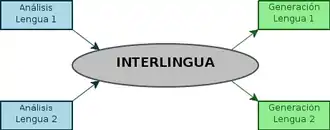
V případě přímého překladu jsou slova přeložena přímo bez použití další reprezentace. Při transferovém překladu je zdrojový text převeden do abstraktní, jazykově méně specifické reprezentace. Pomocí lingvistických pravidel specifických pro daný jazykový pár je reprezentace zdrojového jazyka převedena do abstraktní reprezentace cílového jazyka a z této je poté vytvořena věta v cílovém jazyku.
Interlingvální strojový překlad má své výhody i nevýhody. Mezi výhody patří to, že pro každou kombinaci zdrojového a cílového jazyka je potřeba méně komponent, obdobně také pro přidání nového jazyka. Interlingvální překlad podporuje parafrázování vstupu v původním jazyce, umožňuje, aby analyzátory i generátory jazyka vyvíjel monolingvální producent, a zvládá překládat jazyky, které se od sebe zásadně liší (např. angličtina a arabština[1]). Očividnou nevýhodou je to, že definice interlingvy je složitá a pro širší doménu pravděpodobně dokonce nemožná. Ideálním způsobem použití interlingválního strojového překladu je tedy multilingvální strojový překlad ve velice úzké doméně.
Historie
O interlingválním strojovém překladu se začalo poprvé přemýšlet v 17. století, kdy Descartes a Leibnitz přišli s nápadem vytvářet slovníky pomocí univerzálních číselných kódů. Jiní, jako např. Cave Beck, Athanasius Kircher a Johann Joachim Becher pracovali na vývoji jednoznačného univerzálního jazyka založeného na ikonografech a principech logiky. V roce 1668 popsal interlingvu ve svém díle "Essay towards a Real Character and a Philosophical Language" (Esej o skutečné podstatě a filozofickém jazyku) John Wilkins. V 18. a 19. století se objevilo mnoho návrhů na „univerzální“ mezinárodní jazyk, nejznámější z nich bylo esperanto.
I přesto se v prvních významných systémech strojového překladu myšlenka univerzálního jazyka neobjevila. Namísto toho se začalo pracovat na jednotlivých jazykových párech. Nicméně, v 50. a 60. letech začali myšlenku interlingvy rozvíjet výzkumníci z Cambridge (Margaret Mastermanová), z Leningradu (Nikolaj Andreev) a z Milána (Silvio Ceccato). V roce 1969 rozebral důkladně myšlenku interlingvy izraelský filozof Jehošua Bar-Hillel.
Během 70. let provedli zásadní výzkum v Grenoblu, kde se snažili o překlad fyzikálních a matematických textů z ruštiny do francouzštiny, a v Texasu, kde pracovali na podobném projektu (METAL) překladu z ruštiny do angličtiny. První interlingvální překladové systémy byly vyvinuty v 70. letech také na Stanfordu. Jeden z nich, vyvinutý Rogerem Schankem, se stal základem pro komerční systém pro bankovní převody. Kód druhého, vytvořeného Yorickem Wilksem, je uchován v Muzeu počítačů v Bostonu jako první interlingvální systém strojového překladu.
V 80. letech se interlingválnímu a znalostnímu překladu dostalo zvýšené pozornosti a této oblasti se věnovalo hodně výzkumů. Všechny tyto výzkumy spojoval názor, že k dosažení překladu vysoké kvality je potřeba opustit myšlenku nutnosti absolutního porozumění textu. Namísto toho by překlad měl být založen na lingvistických znalostech a specifické doméně, ve které bude systém použit. Nejdůležitější výzkum v této oblasti byl proveden v Utrechtu v projektu DLT (Distributed Language Translation), kde se pracovalo s upravenou verzí esperanta, a v Japonsku na systému od Fujitsu.
Přehled
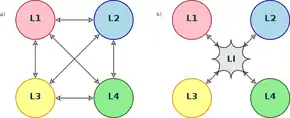
Interlingva může být definována jako popis analýzy zdrojového textu takový, který umožňuje převést jeho morfologické, syntaktické a sémantické (dokonce i pragmatické) charakteristiky, tedy jeho „význam“, do cílového jazyka. Taková interlingva umožňuje popsat všechny charakteristiky všech jazyků, které chceme přeložit, místo toho, abychom jenom překládali z jednoho jazyka do druhého.
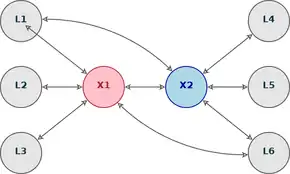
Někdy jsou při překladu použity dvě interlingvy. První možností je, že jedna z nich pokrývá více charakteristik zdrojového jazyka a druhá více charakteristik jazyka cílového. Takový překlad poté převádí věty ze zdrojového jazyka do vět bližších cílovému jazyku ve dvou fázích. Systém může také fungovat tak, že druhá interlingva používá specifičtější slovní zásobu, která je bližší nebo strukturně podobnější cílovému jazyku, což může ve výsledku vylepšit kvalitu překladu.
Výše zmíněný systém je založen na myšlence jazykové blízkosti, která může vylepšit kvalitu překladu z textu v jednom originálním jazyce do mnoha dalších strukturálně podobných jazyků za použití pouze jedné originální analýzy. Tento princip je také použit při překladu využívajícím pivotní jazyk, kde se jako převodní jazyk mezi dvěma vzdálenějšími jazyky používá jazyk přirozený. Například při překladu z angličtiny do ukrajinštiny se jako převodní jazyk použije ruština. [2]
Postup překladu
Interlingvální překladové systémy obsahují dvě monolingvální komponenty: analýzu zdrojového jazyka a interlingvy a generování interlingvy a cílového jazyka. Je nicméně nutné rozlišit mezi interlingválními systémy využívajícími pouze syntaktické metody (např. systémy vyvinuté v 70. letech na univerzitách v Grenoblu a Texasu) a těmi, které jsou založeny na umělé inteligenci (od roku 1987 v Japonsku a systémy z výzkumu na univerzitách South California a Carnegie Mellon). První typ odpovídá schématu na Obrázku 1, zatímco druhý je možné popsat diagramem na Obrázku 4.
Pro interlingvální překladový systém jsou potřeba:
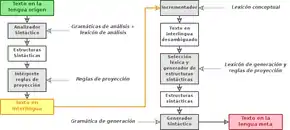
- Slovníky (nebo lexikony) pro analýzu a generování (specifické pro použitou doménu a jazyky).
- Slovník pojmů (specifický pro danou doménu), který obsahuje znalosti o akcích a entitách dané domény.
- Sada projekčních pravidel pro cílový jazyk (specifických pro danou doménu a jazyk).
- Gramatika pro analýzu a generování použitých jazyků.
Jedním z problémů znalostních překladových systémů je, že je nemožné vytvořit databáze pro jiné než velmi úzce specifikované domény. Dalším problémem je, že zpracovávání těchto databází je výpočetně náročné.
Efektivita
Jednou z hlavních výhod této překladové strategie je, že poskytuje úsporný způsob pro vytváření multilingválních překladových systémů. Použijeme-li interlingvu, není již potřeba vytvářet překladové páry pro všechny jazykové páry v systému. Takže místo vytváření jazykových párů, kde je počet jazyků v systému, je nutné vytvořit pouze párů mezi jazyky a interlingvou.



Hlavní nevýhodou této strategie je složitost vytvoření vhodné interlingvy. Měla by být abstraktní a nezávislá jak na zdrojovém, tak cílovém jazyku. Čím více jazyků je zahrnuto v překladovém systému a čím jsou tyto jazyky odlišnější, tím účinnější musí interlingva být, aby dokázala vyjádřit všechny možné směry překladu. Dalším problémem je, že je složité získávat znalosti z textů v originálním jazyce, které jsou potřeba pro vytvoření požadované mezireprezentace.
Existující interlingvální překladové systémy
Reference
V tomto článku byl použit překlad textu z článku Interlingual machine translation na anglické Wikipedii.
- Abdel Monem, A., Shaalan, K., Rafea, A., Baraka, H., Generating Arabic Text in Multilingual Speech-to-Speech Machine Translation Framework[nedostupný zdroj], Machine Translation, Springer, Netherlands, 20(4): 205-258, December 2008.
- Bogdan Babych, Anthony Hartley, and Serge Sharoff (2007) "Translating from under-resourced languages: comparing direct transfer against pivot translation Archivováno 3. 3. 2016 na Wayback Machine".