CUDA
CUDA (akronym z angl. Compute Unified Device Architecture, výslovnost [ˈkjuːdə]) je hardwarová a softwarová architektura,[1] která umožňuje na vybraných GPU spouštět programy napsané v jazycích C/C++, Fortran nebo programy postavené na technologiích OpenCL, DirectCompute a jiných. Použití této architektury je omezeno pouze na grafické akcelerátory a výpočetní karty společnosti nVIDIA, která ji vyvinula. Konkurenční technologie společnosti AMD se nazývá AMD FireStream (dříve Close To Metal). Obě společnosti jsou také členy Khronos Group, která zajišťuje vývoj OpenCL.
 | |
| Vývojář | nVIDIA Corp. |
|---|---|
| Aktuální verze | 11.5.1 (21. listopadu 2021) |
| Operační systém | MS Windows, macOS, GNU/Linux |
| Platforma | podporovaná GPU |
| Typ softwaru | GPGPU |
| Licence | freeware |
| Web | www.nvidia.com |
| Některá data mohou pocházet z datové položky. | |
Historie
Technologii představila společnost nVIDIA v roce 2006. Následujícího roku bylo uvolněno SDK ve verzi 1.0 pro karty nVIDIA Tesla založené na architektuře G80. Ještě v prosinci téhož roku vyšla verze CUDA SDK 1.1, která přidala podporu pro GPU série GeForce 8. Se správným ovladačem grafické karty přibyla podpora pro překrývání paměťových přenosů výpočtem a podpora pro více GPU akcelerátorů.
V roce 2008 bylo vydáno současně s architekturou G200 SDK 2.0. Postupně s verzemi SDK 2.0–2.3 přibývala podpora pro emulovaný výpočet s dvojnásobnou přesností (double-precision) a podpora pro C++ šablony v rámci kernelu.
V roce 2010 bylo spolu s mikroarchitekturou Fermi vydáno SDK 3.0, obsahující nativní podporu pro výpočty s dvojnásobnou přesností, podporu pro ukazatele na funkce a podporu rekurze. Vylepšeny byly též profilovací nástroje a debuggery pro CUDA / OpenCL.
V květnu 2011 byla vydána verze CUDA SDK 4.0. Největší změnou je zde unifikace paměťových prostorů a masivní podpora MultiGPU.
Nejnovější verzí je CUDA SDK 9.0 ze září roku 2017.
Mikroarchitektura GPU
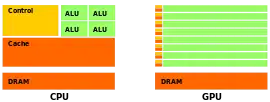
Drtivou většinu plochy čipu grafického akcelerátoru od nVidie zabírá velké množství relativně jednoduchých skalárních procesorů (na rozdíl od architektur konkurenční firmy AMD, jejíž GPU jsou tvořeny VLIW SIMD, resp. RISC SIMD jednotkami, tzv. stream procesory), které jsou organizovány do větších celků zvaných streaming multiprocesory. Vzhledem k tomu, že se jedná o SIMT architekturu, řízení jednotek a plánování instrukcí je jednoduché a spolu s velmi malou vyrovnávací pamětí zabírá malé procento plochy GPU čipu. To má bohužel za následek omezené predikce skoků a časté zdržení výpadky cache (některé typy pamětí dokonce nejsou opatřeny cache). Poslední významnou částí, která je rozměrově velice podobná CPU je RAM řadič.
Struktura multiprocesoru

Obecně se multiprocesor skládá z několika (dnes až ze 32) stream procesorů, pole registrů, sdílené paměti, několika load/store jednotek a Special Function Unit – jednotky pro výpočet složitějších funkcí jako sin, cos, ln.
Výpočetní možnosti (Compute capability)
Výpočetní možnosti popisují vlastnosti zařízení a množinu instrukcí, které jsou podporovány. Některé z těchto vlastností jsou shrnuty v tabulce níže, ostatní lze nalézt v oddílu F nVIDIA CUDA C Programming Guide.[2]
| Vlastnost | 1.0 | 1.1 | 1.2 | 1.3 | 2.x |
|---|---|---|---|---|---|
| Maximální dimenze mřížky bloků | 2 | 4 | |||
| Maximální x-, y- nebo z- rozměr mřížky bloků | 65 535 | ||||
| Maximální dimenze bloku vláken | 3 | ||||
| Maximální x-, y- rozměr bloku vláken | 512 | 1 024 | |||
| Maximální z-rozměr bloku vláken | 64 | ||||
| Maximální počet vláken v bloku | 512 | 1 024 | |||
| Velikost warpu | 32 | ||||
| Maximální počet bloků přidělených na multiprocesor | 8 | ||||
| Maximální počet warpů přidělených na multiprocesor | 24 | 32 | 48 | ||
| Maximální počet vláken přidělených na multiprocesor | 768 | 1 024 | 1 536 | ||
| Počet 32bitových registrů na multiprocesor | 8 000 | 16 000 | 32 000 | ||
| Maximální množství sdílené paměti na multiprocesor | 16 KiB | 48 KiB | |||
| Počet sdílených paměťových banků | 16 | 32 | |||
| Množství lokální paměti na vlákno | 16 KiB | 512 KiB | |||
| Velikost konstantní paměti | 64 KiB | ||||
| Velikost cache pro konstantní paměť na multiprocesor | 8 KiB | ||||
| Velikost cache pro texturovací paměť na multiprocesor | Závislé na zařízení, mezi 6 KiB a 8 KiB | ||||
| Maximální počet textur na jeden kernel | 128 | ||||
| Maximální počet instrukcí na jeden kernel | 2 000 000 | ||||
| Podpora výpočtů v double-precision | Ne | Ano | |||
Programovací model

CUDA aplikace je složena z částí, které běží buď na host (CPU) nebo na CUDA zařízení (GPU). Části aplikace běžící na zařízení jsou spouštěny hostem zavoláním kernelu, což je funkce, která je prováděna každým spuštěným vláknem (thread [θred]).
- Blok (thread block)
- Vlákna jsou organizována do 1D, 2D nebo 3D bloků, kde vlákna ve stejném bloku mohou sdílet data a lze synchronizovat jejich běh. Počet vláken na jeden blok je závislý na výpočetních možnostech zařízení. Každé vlákno je v rámci bloku identifikováno unikátním indexem přístupným ve spuštěném kernelu přes zabudovanou proměnou threadIdx.
- Mřížka (grid)
- Bloky jsou organizovány do 1D, 2D nebo 3D mřížky. Blok lze v rámci mřížky identifikovat unikátním indexem přístupným ve spuštěném kernelu přes zabudovanou proměnou blockIdx. Každý blok vláken musí být schopen pracovat nezávisle na ostatních, aby byla umožněna škálovatelnost systému (na GPU s více jádry půjde spustit více bloků paralelně oproti GPU s méně jádry, kde bloky poběží v sérii).
- Warp
- Balík vláken zpracovávaných v jednom okamžiku se nazývá warp. Jeho velikost je závislá na počtu výpočetních jednotek.
Počet a organizace spuštěných vláken v jednom bloku a počet a organizace bloků v mřížce se určuje při volání kernelu.
Typický průběh GPGPU výpočtu
- Vyhrazení paměti na GPU
- Přesun dat z hlavní paměti RAM do paměti grafického akcelerátoru
- Spuštění výpočtu na grafické kartě
- Přesun výsledků z paměti grafické karty do hlavní RAM paměti
Ukázka kódu v CUDA C
Převzato z [2].
// Kód pro GPU
__global__ void VecAdd(float* A, float* B, float* C, int N)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N)
C[i] = A[i] + B[i];
}
// Kód pro CPU
int main()
{
int N = …;
size_t size = N * sizeof(float);
// Alokace vstupních vektorů h_A and h_B v hlavní paměti
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
// Inicializace vstupních vektorů
…
// Alokace paměti na zařízení
float* d_A;
cudaMalloc(&d_A, size);
float* d_B;
cudaMalloc(&d_B, size);
float* d_C;
cudaMalloc(&d_C, size);
// Přesun vektorů z hlavní paměti do paměti zařízení
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Volání kernelu
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock – 1) / threadsPerBlock;
VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// Přesun výsledků z paměti zařízení do hlavní paměti
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Uvolnění paměti na zařízení
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Uvolnění hlavní paměti
…
Paměťový model

Na grafické kartě je 6 druhů paměti, se kterými může programátor pracovat.
- Pole registrů
- je umístěno na jednotlivých stream multiprocesorech a jejich rozdělení mezi jednotlivé stream procesory plánuje překladač. Každé vlákno může přistupovat pouze ke svým registrům.
- Lokální paměť
- je užívána v případě, že dojde k vyčerpání registrů. Tato paměť je také přístupná pouze jednomu vláknu, je ale fyzicky umístěna v globální paměti akcelerátoru a tak je přístup k ní paradoxně pomalejší než např. ke sdílené paměti.
- Sdílená paměť
- je jedinou pamětí kromě registrů, která je umístěna přímo na čipu streaming multiprocesoru. Mohou k ní přistupovat všechna vlákna v daném bloku. Ke sdílené paměti se přistupuje přes brány zvané banky. Každý bank může zpřístupnit pouze jednu adresu v jednom taktu a v případě, že více streaming procesorů požaduje přístup přes stejný bank, dochází k paměťovým konfliktům, které se řeší prostým čekáním. Speciálním případem je situace, kdy všechna vlákna čtou ze stejné adresy a bank hodnotu zpřístupní v jednom taktu všem streaming procesorům pomocí broadcastu.
- Globální paměť
- je sdílená mezi všemi streaming multiprocesory a není ukládána do cache paměti.
- Paměť konstant
- je paměť pouze pro čtení, stejně jako globální paměť je sdílená s tím rozdílem, že je pro ni na čipu multiprocesoru vyhrazena L1 cache. Podobně jako sdílená paměť umožňuje rozesílání výsledku broadcastem.
- Paměť textur
- je také sdílená mezi SMP, určena pro čtení a disponuje cache pamětí. Je optimalizována pro 2D prostorovou lokalitu, takže vlákna ve stejném warpu, které čtou z blízkých texturovacích souřadnic dosahují nejlepšího výkonu.
| Typ paměti | Umístění | Uložení do cache | Přístup | Viditelnost | Životnost |
|---|---|---|---|---|---|
| Registry | Na čipu | Ne | Čtení/Zápis | 1 vlákno | Vlákno |
| Lokální | Mimo čip | Ne [pozn 1] | Čtení/Zápis | 1 vlákno | Vlákno |
| Sdílená | Na čipu | Ne | Čtení/Zápis | Všechna vlákna v bloku | Blok |
| Globální | Mimo čip | Ne [pozn 1] | Čtení/Zápis | Všechna vlákna a host | Do uvolnění |
| Paměť konstant | Mimo čip | Ano | Čtení | Všechna vlákna a host | Do uvolnění |
| Paměť textur | Mimo čip | Ano | Čtení | Všechna vlákna a host | Do uvolnění |
| |||||
Spolupráce s OpenGL a Direct3D
Některé prvky OpenGL a Direct3D mohou být mapovány do adresního prostoru CUDA aplikace, což umožňuje výměnu dat bez nutnosti jejich přenosu do hlavní paměti. Pro spolupráci s OpenGL lze mapovat OpenGL buffery, textury a renderbuffer objekty, pro spolupráci s Direct3D lze mapovat Direct3D buffery, textury a povrchy. Před samotným použitím v CUDA aplikaci je nutné nejprve prvek registrovat. Protože samotná registrace je výpočetně náročnou operací, je prováděna pouze jednou pro každý prvek. Registrované prvky lze poté podle potřeby přidávat a odebírat z adresního prostoru CUDA aplikace.
Přehled nástrojů pro debugging a profiling
Nedílnou součástí programování je profiling a debugging. Profiling je zvlášť důležitý pro optimalizaci velikosti bloků a počtu vláken, což má za následek lepší překrývání paměťových operací výpočtem.
Profilovací nástroje:
- NVIDIA Nsight Visual Studio Edition
- nVIDIA Visual Profiler
- TAU Performance system
- Vampir 9.1 – Performace Optimization
- The PAPI CUDA Component
Nástroje pro debugging:
Externí odkazy
 Obrázky, zvuky či videa k tématu CUDA na Wikimedia Commons
Obrázky, zvuky či videa k tématu CUDA na Wikimedia Commons
- CUDA Toolkit Documentation [online]. NVIDIA Developer. nVIDIA Corporation, rev. 2018-01-24 [cit. 2018-02-13]. Dostupné online. (anglicky)
- CUDA Toolkit Documentation v9.1.85 [online]. NVIDIA Developer. nVIDIA Corporation, rev. 2018-01-24 [cit. 2018-02-13]. Dostupné online. (anglicky)