Autokorelace
Autokorelace náhodných složek je jev, kterým ve statistice označujeme porušení Gauss-Markovova požadavku pro možnost odhadu regresních parametrů metodou nejmenších čtverců.
Matice kovariancí , která má při splnění nekorelovanosti náhodných složek tvar: , při autokorelaci vykazuje nenulové kovariance (tedy nediagonální prvky jsou nenulové). Platí, že je nám neznámý rozptyl náhodných složek a je jednotková matice řádu n.




Příčiny vzniku autokorelace
- chybná specifikace modelu - tzv. kvaziautokorelace
- přílišná aproximace v modelu (např. místo použijeme x apod.
- použití časově zpožděných proměnných v modelu
- zahrnutí chyb měření do vektoru u
- použití upravených dat - např. extrapolovaných, centrovaných, interpolovaných apod.

Důsledky autokorelace
- ztráta vydatnosti odhadu i asymptotické vydatnosti odhadu regresních parametrů
- i standardní chyby jsou vychýlené, R2 je nadhodnoceno, zatímco t-testy jsou slabé a rezidua jsou podhodnocená

Autokorelace prvního řádu
Tzv. autoregresní struktura prvního řádu:

zároveň platí následující vztah:

kde je tzv. autokorelační koeficient prvního řádu. Platí pro něj , protože jinak by měla rovnice explozivní charakter a byla by tak narušena homoskedasticita v matici . Nejsilnější korelace je vždy mezi dvěma sousedními vektory náhodných složek.


- Pokud je , pak se jedná o pozitivní autokorelaci.
- Pokud je , pak se jedná o negativní autokorelaci.
- Pokud je , pak jsou složky vektorů a sériově nezávislé.





Testování výskytu autokorelace
Protože neznáme přesnou podobu vektoru náhodných složek u, pracujeme s vektory reziduí .

Předpoklady použití testu
- úrovňová konstanta v modelu
- regresory nejsou stochastické proměnné
Testovací statistika

Pro výslednou charakteristiku nelze určit kritickou hodnotu, při které bychom odmítli hypotézu H0 při testování proti d-statistice. Postup vyhodnocení je následující:
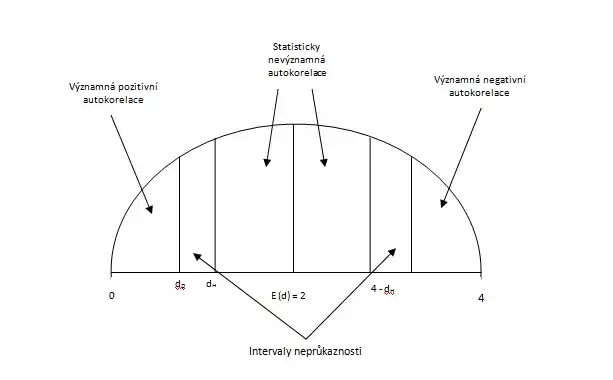
- statistika d má střední hodnotu E(d) = 2 a nachází se v intervalu <0;4>
- stanovíme tabulkové hodnoty dD (dolní mez d) a dH (horní mez d) podle stupňů volnosti modelu
- porovnáme hodnotu d s následujícími intervaly a na základě pozice d vyhodnotíme autokorelaci:
- Interval <0;dD> značí pozitivní autokorelaci
- V intervalu <dD;dH> nemůžeme rozhodnout, zda se jedná o korelaci, či nikoliv
- Interval <dH;2> poukazuje na statisticky nevýznamnou pozitivní autokorelaci
- Interval <2;4-dH> poukazuje na statisticky nevýznamnou negativní autokorelaci
- V intervalu <4-dH;4-dD> nemůžeme rozhodnout, zda se jedná o korelaci, či nikoliv
- Interval <4-dD;4> poukazuje na statisticky významnou negativní autokorelaci
Durbinovo h
- použijeme právě tehdy, pokud se v modelu nachází zpožděná vysvětlovaná proměnná
Statistika h má následující podobu:
- , kde j značí j-tou vysvětlující zpožděnou proměnnou za podmínky, že .


Statistiku h testujeme přes normované normální rozdělení N(0;1), kdy pro
- předpokládáme sériovou nezávislost náhodných složek
- usuzujeme na autokorelaci


Postup v případě identifikování autokorelace náhodných složek
- ověřit správnost modelu (jestli se nejedná o kvaziautokorelaci)
- logaritmování nebo semilogaritmování dat
- transformace dat v matici pozorování X pomocí matice T - tzv. Praisova-Winstenova transformace

což vyústí v následující podobu modelu, který již bude poskytovat při použití metody zobecněných nejmenších čtverců vydatné i asymptoticky vydatné odhady regresních parametrů:

Odkazy
Reference
- Cochrane a Orcutt. 1949. "Application of least squares regression to relationships containing autocorrelated error terms". Journal of the American Statistical Association 44, str. 32–61
Literatura
- Hušek, R. Ekonometrická analýza, Praha, 2007, nakladatelství Oeconomica, ISBN 978-80-245-1300-3