Aritmetické kódování
Aritmetické kódování je metoda pro bezztrátovou kompresi dat. Obvykle zabere reprezentace řetězce znaků jako např. slov "nazdar bazar" pevný počet bitů na znak, tak jako v ASCII kódu. Podobně jako Huffmanovo kódování, aritmetické kódování je forma entropického kódování s proměnlivou délkou kódového slova. To konvertuje řetězce do jiného tvaru tak, že pro časté znaky použije méně bitů a pro vzácné použije více bitů s cílem zabrat celkově méně bitů. Na rozdíl od technik entropického kódování, které rozdělí vstupní text na jeho dílčí symboly a každý symbol nahradí kódovým slovem, zakóduje aritmetické kódování celý vstupní text do jednoho čísla, zlomku n, kde (0.0 ≤ n < 1.0).
Jak funguje aritmetické kódování
Definice modelu
Aritmetické kodéry mají téměř optimální výstup pro danou množinu symbolů a pravděpodobností (optimální hodnota je −log2P bitů pro každý symbol s pravděpodobností P. Kompresní algoritmy, které používají aritmetické kódování, začínají určením modelu dat – v podstatě předpovědi, které vzorky budou nalezeny ve vstupním textu. Čím přesnější je tato předpověď, tím blíže optimalitě bude výstup.
Příklad: jednoduchý, statický model pro popis výstupu určitého monitorovacího zařízení v čase může být:
- 60% pro symbol NEUTRAL
- 20% pro symbol POSITIVE
- 10% pro symbol NEGATIVE
- 10% pro symbol END-OF-DATA. (Přítomnost tohoto symbolu znamená, že proud dat bude 'interně ukončen' tak, jak je běžné pro kompresi dat; když se tento symbol objeví v datovém proudu, dekodér bude vědět, že byl dekódován celý proud).
Modely též mohou pracovat s abecedami jinými než je jednoduchá čtyřsymbolová množina pro tento příklad. Modely však mohou být i složitější: změny v modelování vyššího řádu, kdy se určuje pravděpodobnost aktuálního symbolu podle, symbolů, které mu předcházely (kontext). V modelu pro anglický text, by například pravděpodobnost výskytu "u" byla mnohem vyšší, pokud následuje za "Q" nebo "q". Modely dokonce mohou být adaptivní tím, že nepřetržitě mění své předpovědi, podle dat, které zrovna obsahuje proud. Dekodér musí mít stejný model jako kodér.
Zjednodušený příklad
Jako příklad toho, jak se zakóduje posloupnost symbolů, uvažme toto: máme posloupnost tří symbolů, A,B a C, každé se stejnou pravděpodobností výskytu. Jednoduché blokové kódování by použilo 2 bity na symbol, což je plýtvání: jedna z bitových variací není nikdy použita.
Místo toho reprezentujeme posloupnost jako racionální číslo mezi 0 a 2 o základu 3, kde každá číslice reprezentuje jeden symbol. Například z posloupnosti "ABBCAB" se stane 0.0112013. Potom zakódujeme toto trojkové číslo do odpovídajícího dvojkového s dostatečným počtem míst pro případnou obnovu, tj. 0.0010110012 — toto je jenom 9 bitů, o 25% méně než při naivním blokovém kódování. To je výhodné pro dlouhé posloupnosti, díky efektivním in-place algoritmům převodu mezi číselnými soustavami na číslech s libovolným počtem míst za čárkou.
Nakonec, protože víme, že řetězec měl délku 6, můžeme převést číslo zpět do trojkové soustavy, zaokrouhlit na 6 míst a odtud znovu získáme řetězec.
Kódování a dekódování
Obecně, každý krok kódovacího procesu, vyjma úplně posledního, je stejný; kodér uvažuje v zásadě jen troje různá data:
- Další symbol, který potřebuje být zakódován
- Stávající interval (na úplném začátku kódovacího procesu, je interval nastaven na [0,1), ale to se změní)
- Přechody modelu přidělené každému z různých symbolů dostupných v současném stavu (jak bylo zmíněno dříve, modely vyšších řádů nebo adaptivní modely ukazují, že tyto pravděpodobnosti nemusí být v každém kroku stejné).
Kodér rozdělí aktuální interval na podintervaly, z nichž každý je zlomkem aktuálního intervalu velkým úměrně pravděpodobnosti symbolu ve stávajícím kontextu. Každý interval odpovídající aktuálními symbolu (tj. tomu který se má zrovna zakódovat), se stane intervalem použitým v dalším kroku.
Příklad: pro čtyřsymbolový model výše:
- interval pro NEUTRAL bude ⟨0, 0.6)
- interval pro POSITIVE bude ⟨0.6, 0.8)
- interval pro NEGATIVE bude ⟨0.8, 0.9)
- interval pro END-OF-DATA bude ⟨0.9, 1).
Po zakódování všech symbolů výsledný interval jednoznačně identifikuje posloupnost symbolů, z kterých vznikl. Kdokoli má tento výsledný interval a použitý model, může znovu získat původní posloupnost symbolů zakódovanou jako tento interval.
Není nutné předávat dál výsledný interval, nicméně; je potřeba předat dál jeden zlomek, který leží v intervalu. Zvláště je nutné předat dál číslice (v kterékoli soustavě) tohoto zlomku tak, aby všechny zlomky začínající těmito číslicemi patřily do výsledného intervalu.
Příklad
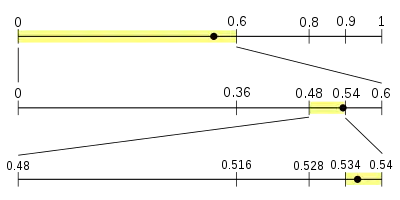
Dejme tomu, že se pokusíme dekódovat zprávu zakódovanou čtyřsymbolovým modelem popsaným výše. Zpráva bude zakódována do zlomku 0.538 (pro přehlednost používáme desítkovou soustavu místo dvojkové; také předpokládáme, že kdokoli nám dá zakódovanou zprávu dá nám jenom tolik číslic, kolik je potřeba k dekódování zprávy. Obě záležitosti si vysvětlíme později.)
Začínáme, tak jako kodér, s intervalem ⟨0,1), který rozdělíme s použitím našeho modelu na známé čtyři podintervaly. Náš zlomek 0.538 padne do podintervalu pro NEUTRAL, ⟨0, 0.6); což nám ukazuje, že první symbol, který přečetl kodér musel být NEUTRAL, takže si můžeme poznamenat první symbol zprávy.
Potom rozdělíme interval ⟨0, 0.6) na podintervaly:
- interval pro NEUTRAL bude ⟨0, 0.36) – 60% z ⟨0, 0.6)
- interval pro POSITIVE bude ⟨0.36, 0.48) – 20% z ⟨0, 0.6)
- interval pro NEGATIVE bude ⟨0.48, 0.54) – 10% z ⟨0, 0.6)
- interval pro END-OF-DATA bude ⟨0.54, 0.6). – 10% z ⟨0, 0.6)
Náš zlomek 0.538 je v intervalu ⟨0.48, 0.54); proto druhý symbol zprávy musí být NEGATIVE.
Ještě jednou rozdělíme náš aktuální interval do podintervalů:
- interval pro NEUTRAL bude ⟨0.48, 0.516)
- interval pro POSITIVE bude ⟨0.516, 0.528)
- interval pro NEGATIVE bude ⟨0.528, 0.534)
- interval pro END-OF-DATA bude ⟨0.534, 0.540).
Náš zlomek 0.538 padne do intervalu pro symbol END-OF-DATA; což tím pádem musí být náš další symbol. Protože je též symbol vnitřního ukončení, je dekódování hotové. Kdyby proud nebyl interně ukončen, potřebovali bychom vědět z jiného zdroje, kde proud skončí. Jinak bychom pokračovali v dekódování navždy tím, že bychom chybně četli ze zlomku více znaků, než do něj bylo zakódováno.
Stejná zpráva by mohla být zakódována stejně dlouhými čísly 0.534, 0.535, 0.536, 0.537, nebo 0.539. To svědčí o tom, že naše použití desítkové soustavy místo dvojkové způsobilo neefektivitu. To je správně; informace obsažená ve třech desítkových číslicích je přibližně 9.966 bits; stejnou zprávu bychom mohli zakódovat do dvojkového zlomku 0.10001010 (jež se rovná 0.5390625 desítkově) za cenu pouze 8 bitů. (Poznamenejme, že poslední nula musí v zápisu dvojkového čísla figurovat, jinak bude zpráva nejednoznačná bez vnější informace jako je např. velikost komprimovaného proudu.)
Tento 8bitový výstup je větší než obsažená informace (Informační entropie) naší zprávy, která je 1.57 · 3 nebo 4.71 bitů. Ten velký rozdíl v příkladu mezi 8(nebo 7 s vnější informací o velikosti komprimovaného textu) bity výstupu a entropií 4.71 bitů je způsoben tím, že ukázková zpráva je tak krátká, že nedokáže využít kodér efektivně. Požadovali jsme pravděpodobnosti symbolů [0.6, 0.2, 0.1, 0.1], ale skutečné četnosti v tomto příkladě jsou [.33, 0, .33 .33]. Pokud jsou intervaly upraveny pro tyto frekvence, entropie zprávy je 1.58 bitů a tato zpráva NEUTRAL NEGATIVE ENDOFDATA může být zakódována jako intervaly ⟨0, 1/3); ⟨1/9, 2/9); ⟨5/27, 6/27); a dvojkové intervaly ⟨1011110, 1110001). Výstup je pak 111, neboli 3 bity. Toto je také příklad, jak statistické kódovací metody jako aritmetické kódování mohou produkovat výstup větší než vstup, zvláště když je pravděpodobnostní model mimo.
Reference
V tomto článku byl použit překlad textu z článku Arithmetic coding na anglické Wikipedii.