Algoritmus k-nejbližších sousedů
Algoritmus k-nejbližších sousedů (neboli k-NN) je algoritmus strojového učení pro rozpoznávání vzorů.
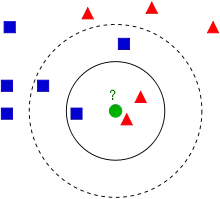
Jde o metodu pro učení s učitelem, kdy se klasifikují prvky reprezentované vícedimenzionálními vektory do dvou nebo více tříd. Ve fázi učení se předzpracuje trénovací množina tak, aby všechny příznaky měly střední hodnotu 0 a rozptyl 1 - toto umístí každý prvek trénovací množiny do některého místa v N-rozměrném prostoru. Ve fázi klasifikace umístím dotazovaný prvek do téhož prostoru a najdu k nejbližších sousedů. Objekt je pak klasifikován do té třídy, kam patří většina z těchto nejbližších sousedů.
Pokud je k=1, jde o speciální zjednodušený případ, metodu nejbližšího souseda.
Pro hledání nejbližšího souseda v množině lze použít různé metriky. Nejobvyklejší je euklidovská metrika nebo Hammingova metrika.